前々回の記事では、requests と BeautifulSoupを使ったスクレイピングについて紹介し、前回の記事 では今後使えそうな機能をクラスしてみました。
今回は、request の代わりに selenium を使ってスクレイピングをしましたので、その方法について解説したいと思います。
selenium で抜き出したHTMLは前回紹介した共通クラスを使って情報を抽出していますので、共通クラスの使い方をもう少し知りたいも、是非ご一読ください。
今回の背景
実は、このブログは Cocoon というWordPress用のフリーのテーマを使っており、管理者画面では記事毎の統計情報(日毎、週毎、月毎、及び記事公開から今日までのアクセス件数)が見れるようになっています。
これを分析すれば、どの記事が興味をもたれているかが分かるので、スクレイピングで収集しようと試みたところ、そもそも管理者画面に入るにはIDとパスワードが必要となり、前回までの方法では出来ないことが分かりました。
requests を使って、URLの要求時にIDとパスワードを送って認証させる方法もあるのですが、それで対応できる方法はベーシック認証などごく一般的なもので、残念ながらWordPressの場合はこの方法が使えません。
それなら、selenium を使って画面からIDとパスワードを入力するのが手っ取り早そうだと判断し、今回の記事に至ります。
selenium とは
スクレイピングを行う上でよく使われるライブラリとして、Requests、BeautifulSoup、Seleniumがあることは前々回の記事でも説明いたしました。
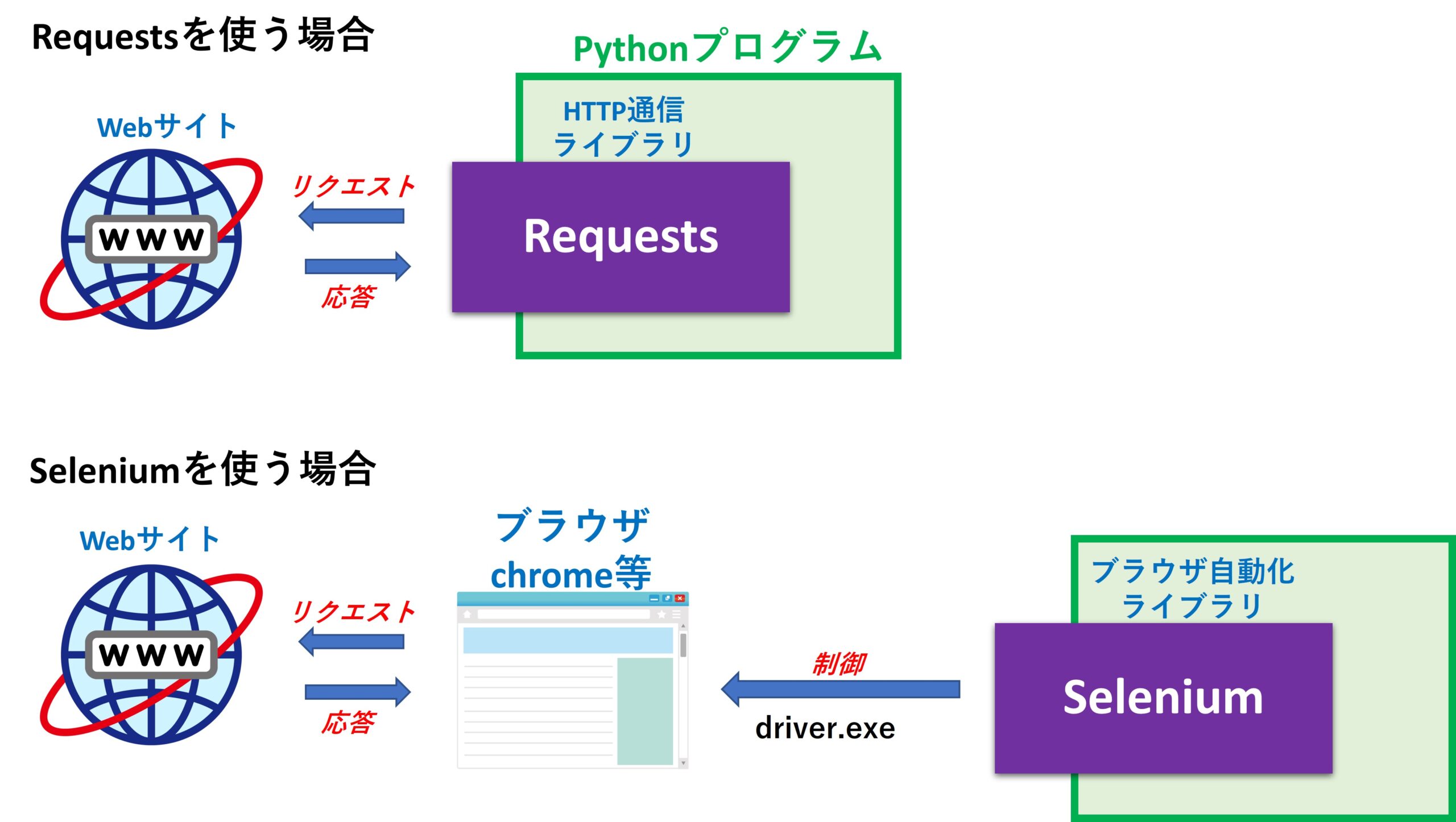
Reauests はブラウザを表示することなく、直接WebサイトとHTTP通信が行えるライブラリです。
それに対して、Selenium は Chromeなどの既存ブラウザをPythonから操作するためのライブラリです。
旅行に例えて言うなら、自分が直接宿泊施設に電話して宿を押さえてもらうか、旅行会社(この場合はSelenium)に頼んで宿を押さえてもらうかの違いです。
もともとCeleniumはWebアプリのデバッグ用として開発されており、あたかも人が画面操作するのと同じことを自動で行わせることで、テスト作業を効率化するものです。
しかし、これを利用することで、あたかも人が操作しているようにスクレイピングが可能になります。
つまり、スクレイプされる側のWebサイトは、人がやっているのか自動でやっているのか全く区別がつきません。
selenium の使い方
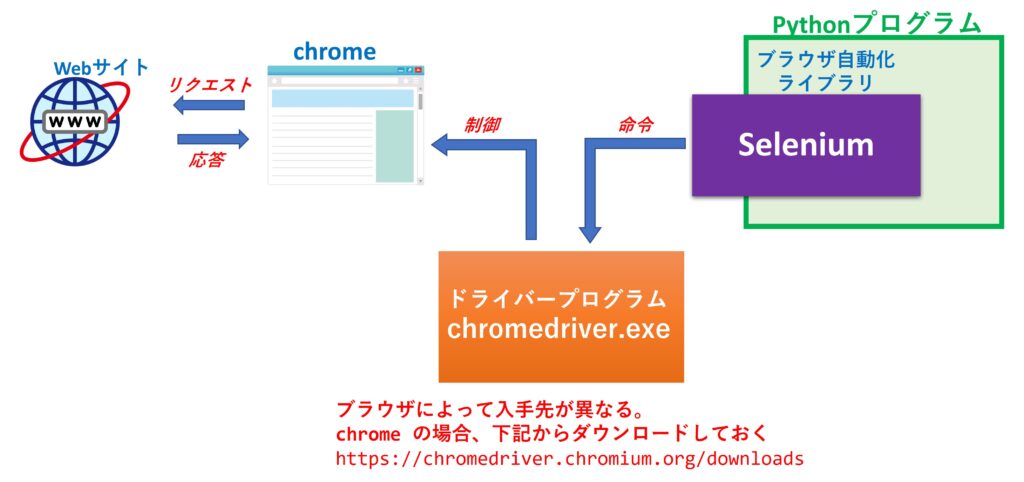
Selenium は ブラウザごとに用意されたドライバープログラム(Chrome の場合は chromedriver.exe)をダウンロードし、このドライバープログラムを通じてPython 側からブラウザを制御します。
Pythonにimport したSeleniumライブラリは、あくまでも chromedriver に対して命令を出すだけで、実際のブラウザ制御は chromedriver.exe が担当します。
より詳しい情報が必要な場合は、Selenium公式ページでご確認下さい。
Seleniumを使うための準備
使うための準備は3つです。
1つ目は、ドライバープログラムをダウンロードして所定のフォルダに置くことです。
2つ目は、Pythonにライブラリをインストールすること。
3つ目は、インストールしたライブラリをインポートすること。
では、順を追って説明していきます。
ドライバをダウンロードして所定のフォルダに置く
Seleniumのバージョン4.3.0以降は、インストールされている Chromeブラウザのバージョンに応じたドライバープログラムを、自動でダウンロードしてくれます。
ダウンロード場所は下記のフォルダになりますので、もしバージョン違い等の不具合が発生した場合は、このフォルダにある schromedriver.exe を更新して下さい。
C:\Users\<ユーザー名>\.cache\selenium\chromedriver\win64\<Chromeブラウザバージョン>
今回は chrome を使うことを前提にしていますが、他のブラウザを seleniumuで制御したい場合も同様の手順になります。
Chromeブラウザのバージョン確認方法は次の通りです。
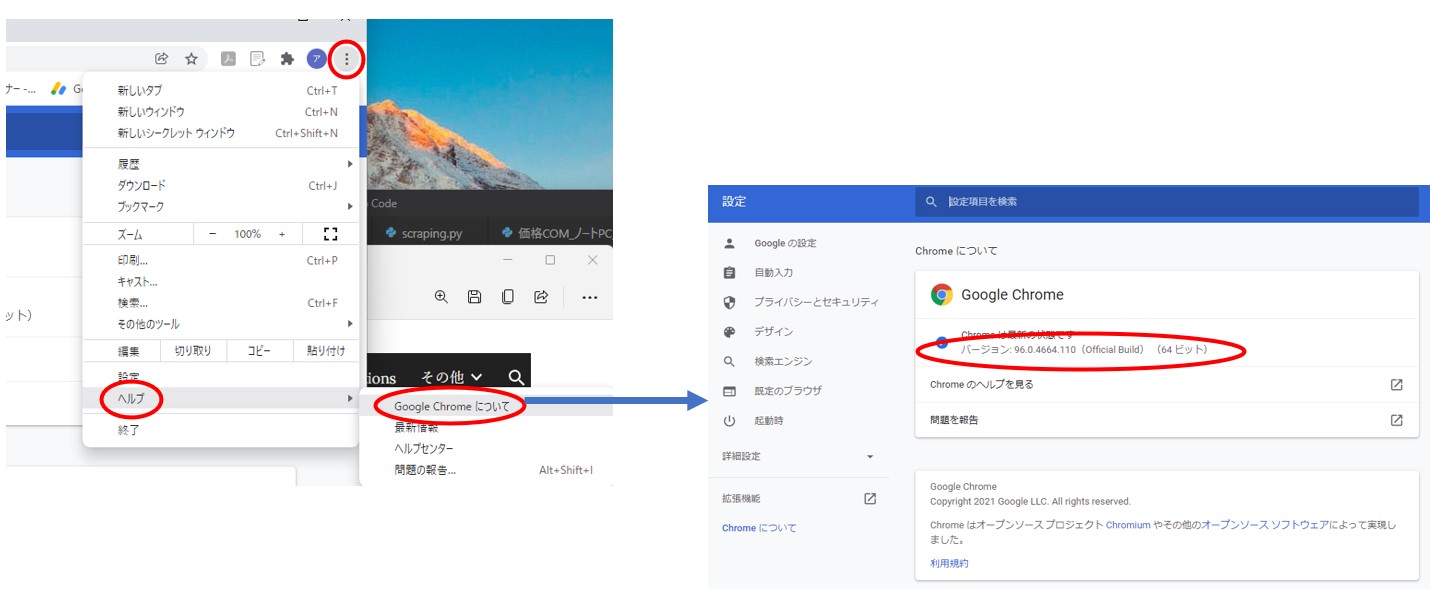
ちなみに、2023年10月時点で、私の環境では バージョン: 118.0.5993.70(Official Build) (64 ビット)でした。
本来は手動でのダウンロードは必要ありませんが、念のため chromedirver.exe の入手先を共有しておきます。
インストールする
インストール方法ですが、PythonをAnaconda経由でインストールされた方は conda を使って、Python公式サイトからPythonをインストールされた方は pip を使ってインストールします。
#Anaconda経由でPythonをインストールされた方
conda install -c conda-forge selenium
#Python公式サイトからPythonをインストールされた方
pip install seleniumインポートする
次に、プログラムをインポートします。
これは次の様に記述します。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By1行目、2行目は必須ですが、3行目、4行目は selenium 経由でブラウザ内のタグを検索したり、値をセットしたい場合に役立つものなので、必要に応じて記述して下さい。
Selenium を使ってみる
使い方は簡単で、webdriver.Chrome() によりインスタンスを生成し、Seleniumに用意されている様々なメソッドを呼び出すだけです。
driver = webdriver.Chrome()例えば、get() メソッドで ブラウザに表示されているページのHTMLが取得でき、さらにfind_element(By.NAME,"要素名")で要素を検索してテキストを取り出したり、その要素に対してキーを入力することが出来ます。
# name属性が log の要素に対して、hogehoge とエンターキーを送信する
driver.find_element(By.NAME, "log").send_keys("hogehoge", Keys.RETURN)Options() のオブジェクトを引数で渡すことで、Chromeドライバの起動時にパラメータを渡して、動作を変えることができます。
例えば、options.add_argument('--headless') を指定すると、ブラウザを非表示にした状態で処理を行う事が出来ます。
options = Options()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)selenium で用意されている find_element() を使えば、要素の値を取得できますので、簡単なページ解析程度であれば BeautifulSoup を使わなくても、selenium だけで済ませることも可能です。
前回記事で紹介した共通クラスにメソッドを追加
前回記事で紹介した共通クラス(Scrape)に、1つだけメソッドを追加しました。
get_soup(thml) というメソッドで、引数にHTMLを渡すと、BeautifulSoup のインスタンスが返ってくるというものです。
今回は request メソッドは使わず、Seleniumu 経由でHTMLを取得するための処置です。
class Scrape():
def __init__(self,wait=1,max=None):
self.response = None
self.df = pd.DataFrame()
self.columns = []
self.values = []
self.wait = wait
self.max = max
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36"}
self.timeout = 5
def request(self,url,wait=None,max=None,console=True):
'''
指定したURLからページを取得する。
取得後にwaitで指定された秒数だけ待機する。
max が指定された場合、waitが最小値、maxが最大値の間でランダムに待機する。
Params
---------------------
url:str
URL
wait:int
ウェイト秒
max:int
ウェイト秒の最大値
console:bool
状況をコンソール出力するか
Returns
---------------------
soup:BeautifulSoupの戻り値
'''
self.wait = self.wait if wait is None else wait
self.max = self.max if max is None else max
start = time.time()
response = requests.get(url,headers=self.headers,timeout = self.timeout)
time.sleep(random.randint(self.wait,self.wait if self.max is None else self.max))
if console:
tm = datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')
lap = time.time() - start
print(f'{tm} : {url} 経過時間 : {lap:.3f} 秒')
return self.get_soup(response.content)
def get_soup(self,thml):
'''
指定したhtml から BeautifulSoup を取得する
Params
---------------------
thml:str
解析したいhtml
Returns
---------------------
return : BeautifulSoupの戻り値
条件を満たすurlのリスト
'''
return BeautifulSoup(thml, "html.parser")
def get_href(self,soup,contains = None):
'''
soupの中からアンカータグを検索し、空でないurlをリストで返す
containsが指定された場合、更にその文字列が含まれるurlだけを返す
Params
---------------------
soup:str
BeautifulSoupの戻り値
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
urls = list(set([url.get('href') for url in soup.find_all('a')]))
if contains is not None:
return [url for url in urls if self.contains(url,contains)]
return [url for url in urls if urls is not None or urls.strip() != '']
def get_src(self,soup,contains = None):
'''
soupの中からimgタグを検索し、空でないsrcをリストで返す
containsが指定された場合、更にその文字列が含まれるurlだけを返す
Params
---------------------
soup:str
BeautifulSoupの戻り値
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
urls = list(set([url.get('src') for url in soup.find_all('img')]))
if contains is not None:
return [url for url in urls if contains(url,self.contains)]
return [url for url in urls if urls is not None or urls.strip() != '']
def contains(self,line,kwd):
'''
line に kwd が含まれているかチェックする。
line が None か '' の場合、或いは kwd が None 又は '' の場合は Trueを返す。
Params
---------------------
line:str
HTMLの文字列
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
if line is None or line.strip() == '':
return False
if kwd is None or kwd == '':
return True
return kwd in line
def omit_char(self,values,omits):
'''
リストで指定した文字、又は文字列を削除する
Params
---------------------
values:str
対象文字列
omits:str
削除したい文字、又は文字列
Returns
---------------------
return :str
不要な文字を削除した文字列
'''
for n in range(len(values)):
for omit in omits:
values[n] = values[n].replace(omit,'')
return values
def add_df(self,values,columns,omits = None):
'''
指定した値を DataFrame に行として追加する
omits に削除したい文字列をリストで指定可能
Params
---------------------
values:[str]
列名
omits:[str]
削除したい文字、又は文字列
'''
if omits is not None:
values = self.omit_char(values,omits)
columns = self.omit_char(columns,omits)
df = pd.DataFrame(values,index=self.rename_column(columns))
self.df = pd.concat([self.df,df.T])
def to_csv(self,filename,dropcolumns=None):
'''
DataFrame をCSVとして出力する
dropcolumns に削除したい列をリストで指定可能
Params
---------------------
filename:str
ファイル名
dropcolumns:[str]
削除したい列名
'''
if dropcolumns is not None:
self.df.drop(dropcolumns,axis=1,inplace=True)
self.df.to_csv(filename,index=False,encoding="shift-jis",errors="ignore")
def get_text(self,soup):
return ' ' if soup == None else soup.text
def rename_column(self,columns):
lst = list(set(columns))
for column in columns:
dupl = columns.count(column)
if dupl > 1:
cnt = 0
for n in range(0,len(columns)):
if columns[n] == column:
if cnt > 0:
columns[n] = f'{column}_{cnt}'
cnt += 1
return columns
def write_log(self,filename,message):
message += '\n'
with open(filename, 'a', encoding='shift-jis') as f:
f.write(message)
print(message)
def read_log(self,filename):
with open(filename, 'r', encoding='shift-jis') as f:
lines = f.read()
return lines.split('\n')尚、Seleniumu で取得したHTMLを BeautifulSoup で解析する場合、次の様に記述する必要があります。
html = driver.page_source.encode('utf-8')Cocoonの統計情報をスクレイピングする
下記はこのブログの管理画面です。
赤く囲っている部分がスクレイピングで取得したい箇所になります。
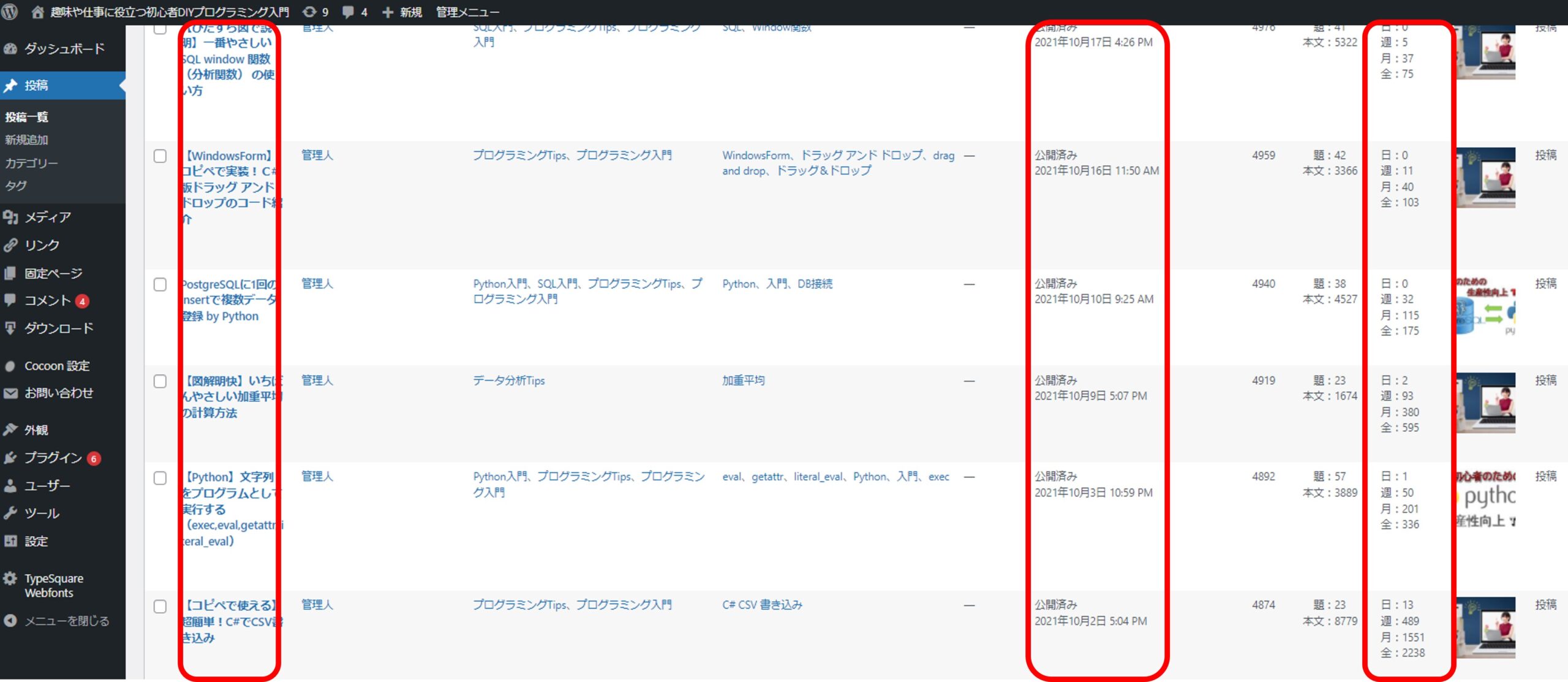
一応ソースは掲載しておきますが、今回はスクレイピングの内容が特殊なので、HTMLの解析に関する解説はしません。
使い方の具体例としてご利用いただければと思います。
しかし、WordPressのテーマでCocoonを使っている方であれば、ユーザー名とパスワード、ドライバープログラムのパスと、CSVを出力するパス及びファイル名を修正して頂ければ、統計情報のCSVが入手できます。
driver = webdriver.Chrome()
scr = Scrape()
res = driver.get('https://hogehoge.com/wp-admin/')
driver.find_element(By.NAME,"log").send_keys("ユーザー名", Keys.RETURN)
driver.find_element(By.NAME,"pwd").send_keys("パスワード", Keys.RETURN)
post_pages=9 #記事一覧のページ数(記事数÷20)
fixed_pages=3 #固定記事一覧のページ数(記事数÷20)
urls = [f'https://hogehoge.com/wp-admin/edit.php?paged={n}' for n in range(post_pages)]
urls.extend([f'https://hogehoge.com/wp-admin/edit.php?post_type=page&paged={n}' for n in range(fixed_pages)])
columns = [ 'タイトル','公開日','日','週','月','全']
for url in urls:
page = driver.get(url)
html = driver.page_source.encode('utf-8')
soup = scr.get_soup(html)
titles = soup.find_all('div',class_='post_title')
dates = soup.find_all('td',class_='date column-date')
cnts = soup.find_all('span',class_='pv-title-count')
for p in range(len(titles)):
pos = p * 4
values = [
titles[p].text,
dates[p].text[4:].split(' ')[0],
cnts[pos].text,
cnts[pos+1].text,
cnts[pos+2].text,
cnts[pos+3].text
]
scr.add_df(values,columns)
scr.to_csv('p:/統計情報.csv')まとめ
今回はSeleniumの使い方と、それを使って WordPress のログイン認証を行い、統計情報をCSVに保存するという少々ニッチなスクレイピングについて紹介いたしました。
実は、WordPress が使っているデータベースに統計情報は保存されているので、それを見るのが手っ取り早いかもしれません。
しかし、DBを直接参照する際に、誤った操作でデータを壊してしまうリスクも少なからずあるので、これが一番安心安全です。
この記事が皆様のスクレイピングの参考になれば幸いです。








コメント