前回の記事では、Pythonを使ったスクレイピング(Scraping)の方法について、価格COMのスペック情報を抜き出すというテーマで解説しました。
今回は、前回のソースコードの中から汎用的に使える部分をクラス化したので紹介したいと思います。
ついでに、前回のサンプルコードを今回のクラスで置き換えてスッキリさせましたので、併せてご紹介したいと思います。
クラスはコピペで使えますので、是非ご活用下さい。
スクレイピング便利クラスの概要
今回はScrape というクラス名にしました。
クラスの構成は次の様になっています。
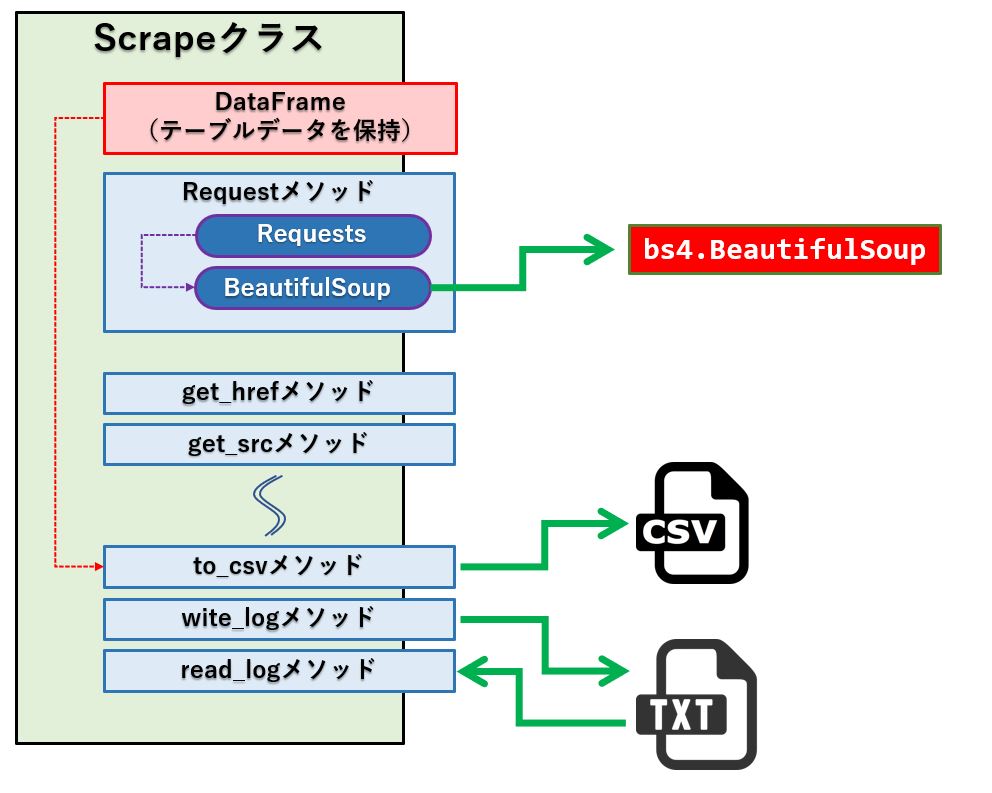
下記は指定したURLのページを読み込み、title タグの text を読み出すサンプルになります。
scr = Scrape(2,5)
soup = scr.request('https://kakaku.com/camera/digital-camera/itemlist.aspx')
title = soup.find('title').textコンストラクタで2と5を指定していますので、URLを1ページ読み込むごとに最低2秒、最大5秒の間でランダムなウェイトが発生します。
リファレンス
詳細はソースコードのコメントに記載していますので、ここでは各メソッドについて簡単に解説しておきます。
| 内容 | メソッド名と引数 | 補足 |
|---|---|---|
| コンストラクタ | Scrape(wait=1,max=None) | リクエストごとに、wait~max の間で ランダムな待ち時間が入る。 |
| サイトにリクエストを発行し、取得したHTMLを保持したBeautifulSoupのインスタンスを返す | request(url, wait=None, max=None, console=True) | wait,maxが指定されると、コンストラクタよりこちらの値が優先される。 console=Trueの場合、URLと処理時間 がコンソールに出力される。 戻り値として、BeautifulSoupのインスタンスが返される。 |
| アンカータグからURLを取得し リストで返す 。 | get_href(soup,contains = None) | contains を指定すると、その文字列が含まれるURLだけが返される。 |
| Imgタグから画像のURLを取得し リストで返す 。 | get_src(soup,contains = None) | contains を指定すると、その文字列が含まれるURLだけが返される。 |
| 文字列にキーワードが 含まれているかチェックする 。 | contains(line,kwd) | line もしくは kwd が None 又は '' の場合は Trueを返す。 |
| 指定した文字を削除する 。 | omit_char(values,omits) | omits はリスト形式で指定する。 例:[’\u3000’,'\n'] |
| DataFrameに1行追加する 。 | add_df(values,columns, omits = None) | クラス内部に保持しているDataFrameに1行追加する。 |
| DataFrameの内容を CSVとしてファイルに書き込む 。 | to_csv(filename,dropcolumns=None) | クラス内部に保持しているDataFramをCSV出力する。 |
| テキストプロパティの値を取得する。 | get_text(soup) | findの結果が bs4.element.Tag で返されるので、これを引数として渡す。そfindの結果がNoneの場合は半角スペース(' ')を、Noneでなければ text の値を返す。 |
| 重複する列名の末尾に連番を 付けてユニークにする 。 | rename_column(columns) | リストで指定したカラム名において、重複しているカラム名には末尾に連番を付けて返す。 |
| 指定したファイルに任意の文字 列を追記する 。 | write_log(filename,message) | スクレイプした結果、エラーになったURLなどをファイルに記録しておくためのもの。 |
| 指定したファイルを読み込んで リストで返す 。 | read_log(filename) | エラーになったURLリストを読み込んで、再読み込み等何らかの処理を行いたい場合に使う。 |
Scrapeクラスのソースコード
以下はScrapeクラスのソースコードになります。
そのままコピペしてお使いいただけますが、必要に応じて適宜修正してお使い下さい。
import requests
from bs4 import BeautifulSoup
import time
import random
import pandas as pd
import time
import datetime
class Scrape():
def __init__(self,wait=1,max=None):
self.response = None
self.df = pd.DataFrame()
self.wait = wait
self.max = max
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36"}
self.timeout = 5
def request(self,url,wait=None,max=None,console=True):
'''
指定したURLからページを取得する。
取得後にwaitで指定された秒数だけ待機する。
max が指定された場合、waitが最小値、maxが最大値の間でランダムに待機する。
Params
---------------------
url:str
URL
wait:int
ウェイト秒
max:int
ウェイト秒の最大値
console:bool
状況をコンソール出力するか
Returns
---------------------
soup:BeautifulSoupの戻り値
'''
self.wait = self.wait if wait is None else wait
self.max = self.max if max is None else max
start = time.time()
response = requests.get(url,headers=self.headers,timeout = self.timeout)
time.sleep(random.randint(self.wait,self.wait if self.max is None else self.max))
if console:
tm = datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S')
lap = time.time() - start
print(f'{tm} : {url} 経過時間 : {lap:.3f} 秒')
return BeautifulSoup(response.content, "html.parser")
def get_href(self,soup,contains = None):
'''
soupの中からアンカータグを検索し、空でないurlをリストで返す
containsが指定された場合、更にその文字列が含まれるurlだけを返す
Params
---------------------
soup:str
BeautifulSoupの戻り値
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
urls = list(set([url.get('href') for url in soup.find_all('a')]))
if contains is not None:
return [url for url in urls if self.contains(url,contains)]
return [url for url in urls if urls is not None or urls.strip() != '']
def get_src(self,soup,contains = None):
'''
soupの中からimgタグを検索し、空でないsrcをリストで返す
containsが指定された場合、更にその文字列が含まれるurlだけを返す
Params
---------------------
soup:str
BeautifulSoupの戻り値
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
urls = list(set([url.get('src') for url in soup.find_all('img')]))
if contains is not None:
return [url for url in urls if contains(url,self.contains)]
return [url for url in urls if urls is not None or urls.strip() != '']
def contains(self,line,kwd):
'''
line に kwd が含まれているかチェックする。
line が None か '' の場合、或いは kwd が None 又は '' の場合は Trueを返す。
Params
---------------------
line:str
HTMLの文字列
contains:str
抽出条件となる文字列
Returns
---------------------
return :[str]
条件を満たすurlのリスト
'''
if line is None or line.strip() == '':
return False
if kwd is None or kwd == '':
return True
return kwd in line
def omit_char(self,values,omits):
'''
リストで指定した文字、又は文字列を削除する
Params
---------------------
values:str
対象文字列
omits:str
削除したい文字、又は文字列
Returns
---------------------
return :str
不要な文字を削除した文字列
'''
for n in range(len(values)):
for omit in omits:
values[n] = values[n].replace(omit,'')
return values
def add_df(self,values,columns,omits = None):
'''
指定した値を DataFrame に行として追加する
omits に削除したい文字列をリストで指定可能
Params
---------------------
values:[str]
列名
omits:[str]
削除したい文字、又は文字列
'''
if omits is not None:
values = self.omit_char(values,omits)
columns = self.omit_char(columns,omits)
df = pd.DataFrame(values,index=self.rename_column(columns))
self.df = pd.concat([self.df,df.T])
def to_csv(self,filename,dropcolumns=None):
'''
DataFrame をCSVとして出力する
dropcolumns に削除したい列をリストで指定可能
Params
---------------------
filename:str
ファイル名
dropcolumns:[str]
削除したい列名
'''
if dropcolumns is not None:
self.df.drop(dropcolumns,axis=1,inplace=True)
self.df.to_csv(filename,index=False,encoding="shift-jis",errors="ignore")
def get_text(self,soup):
'''
渡された soup が Noneでなければ textプロパティの値を返す
Params
---------------------
soup: bs4.element.Tag
bs4でfindした結果の戻り値
Returns
---------------------
return :str
textプロパティに格納されている文字列
'''
return ' ' if soup == None else soup.text
def rename_column(self,columns):
'''
重複するカラム名の末尾に連番を付与し、ユニークなカラム名にする
例 ['A','B','B',B'] → ['A','B','B_1','B_2']
Params
---------------------
columns: [str]
カラム名のリスト
Returns
---------------------
return :str
重複するカラム名の末尾に連番が付与されたリスト
'''
lst = list(set(columns))
for column in columns:
dupl = columns.count(column)
if dupl > 1:
cnt = 0
for n in range(0,len(columns)):
if columns[n] == column:
if cnt > 0:
columns[n] = f'{column}_{cnt}'
cnt += 1
return columns
def write_log(self,filename,message):
'''
指定されたファイル名にmessageを追記する。
Params
---------------------
filename: str
ファイル名
message: str
ファイルに追記する文字列
'''
message += '\n'
with open(filename, 'a', encoding='shift-jis') as f:
f.write(message)
print(message)
def read_log(self,filename):
'''
指定されたファイル名を読み込んでリストで返す
Params
---------------------
filename: str
ファイル名
Returns
---------------------
return :[str]
読み込んだ結果
'''
with open(filename, 'r', encoding='shift-jis') as f:
lines = f.read()
return lines価格COMのデジカメ情報を取得する
では、次に今回のクラスを使って、前回記事で掲載したプログラムを書き直した結果をご紹介しましょう。
全体の構造
今回は Scrape クラスを使うので、その分ソースコードが簡略化できます。
とは言うものの、詳細ページからスペック情報を取得する部分が少々煩雑なので、これをget_detailという名前で関数化することにしました。
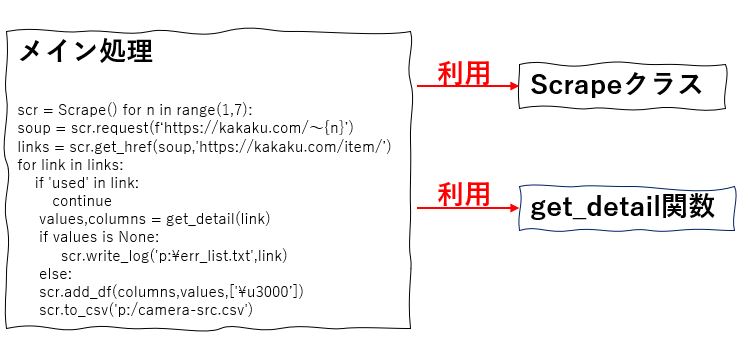
get_detail関数は価格COMの詳細情報からスペック情報を抜き出すための専用関数であるため、Scrape クラスにメソッドは実装せず、今回専用の関数として用意しました。
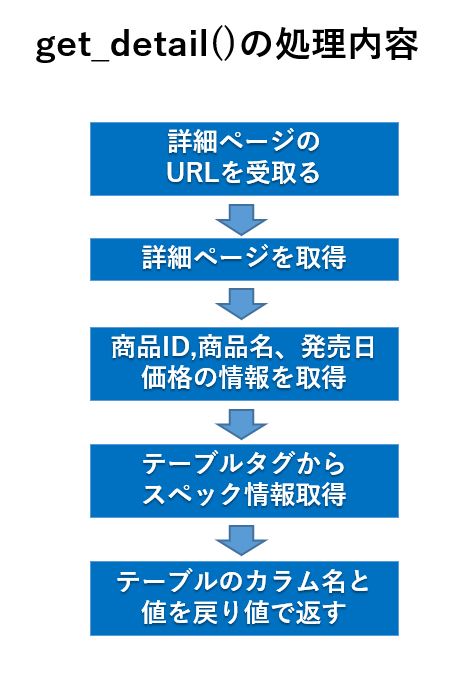
以下がそのソースコードになります。
def get_detail(link):
'''
指定した商品明細のURLに記載されているページからスペック情報を取得する関数
Params
---------------------
link:str
価格comの商品詳細ページのURL
'''
scr = Scrape()
soup = scr.request(f'{link}spec/#tab')
table = soup.find('table',class_='tblBorderGray mTop15')
if table is None:
return None,None
#商品ID,商品名,発売日,最安価格,価格帯(下限、上限)を取得
columns = ['商品ID','商品名','発売日','最安価格','価格帯(下限)','価格帯(上限)']
values = [
link[-12:-1],
scr.get_text(soup.find('h2',itemprop='name')),
scr.get_text(soup.find('span',class_='releaseDate')),
scr.get_text(soup.find('span',class_='priceTxt')).replace(',','')[1:],
scr.get_text(soup.find('span',itemprop='lowPrice')).replace(',','')[1:],
scr.get_text(soup.find('span',itemprop='highPrice')).replace(',','')[1:]
]
#tableタグの中身からスペック情報を取り出す
trs = table.find_all('tr')
for tr in trs:
ths = tr.find_all('th')
tds = tr.find_all('td')
for th,td in zip(ths,tds):
columns.append(th.text)
values.append('' if td is None else td.text)
return columns,valuesメインのスクレイピング処理
メインのスクレイピング処理は、次の様なフローになります。

実際にスクレイピングをして分かったことですが、一覧ページの中には中古デジカメのURLも含まれていました。
これを処理しないようにするため、URLに 'used' の文字が含まれていた場合、処理を飛ばすようにしています。
また、何らかの理由でページ読み込みに失敗することがあったので、それが分かるようにログファイルにURLを出力するようにしています。
正しくスペック情報が取得できた場合、ScrapeのインスタンスにあるDataFrameに結果を格納していき、最後にCSV出力するという方法を取っています。
以上のことを念頭に、もう少しフローを細かく記載したのが下記の図です。
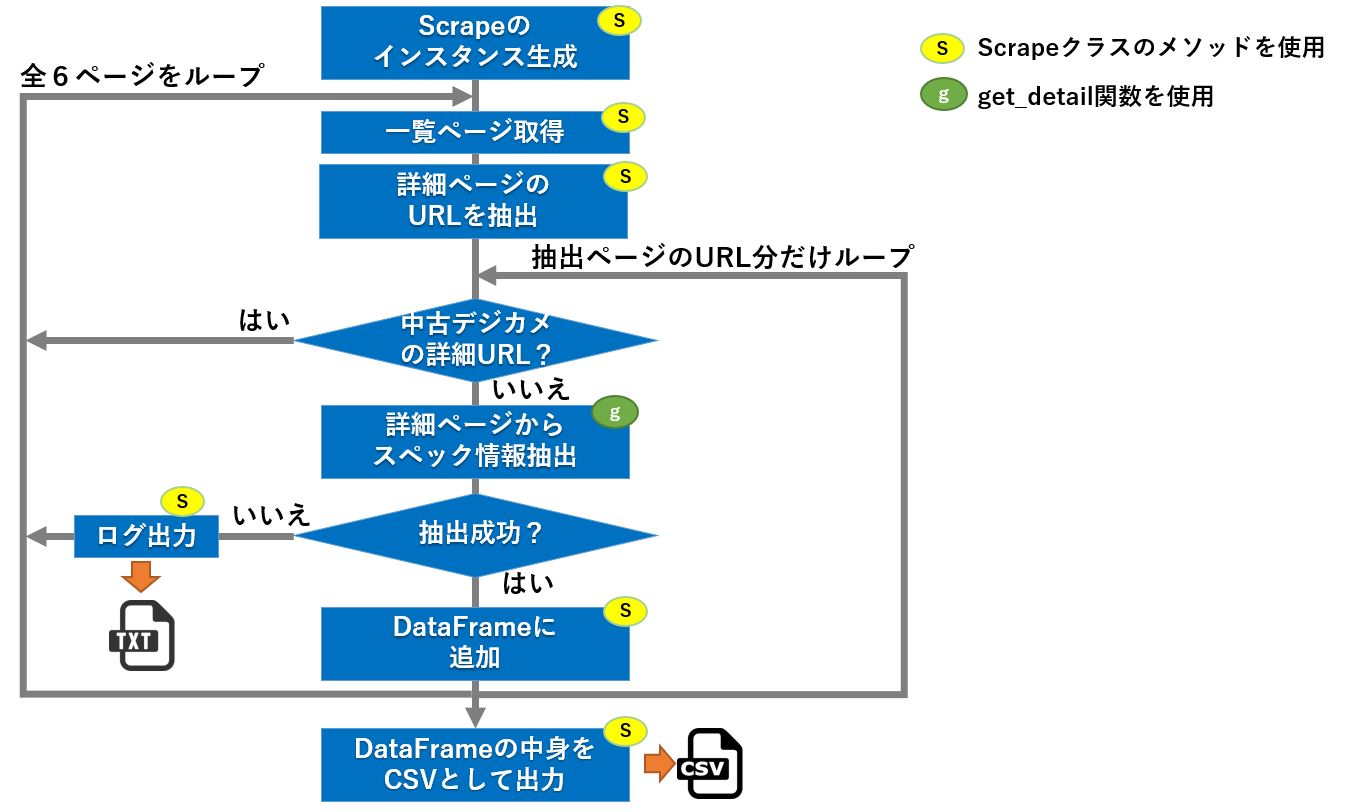
そして、最終的なスクレイピングのソースコードは次の様になりました。
デジカメの商品一覧ページは全部で6ページありますので、for ループで1~7でカウントをしています。
scr = Scrape()
for n in range(1,7):
soup = scr.request(f'https://kakaku.com/camera/digital-camera/itemlist.aspx?pdf_pg={n}')
links = scr.get_href(soup,'https://kakaku.com/item/')
for link in links:
if 'used' in link:
continue
values,columns = get_detail(link)
if values is None:
#失敗したURLをログに追加
scr.write_log('p:\err_list.txt',link)
else:
#DataFrameにスペック情報を格納
scr.add_df(columns,values,['\u3000'])
scr.to_csv('p:/camera-src.csv')
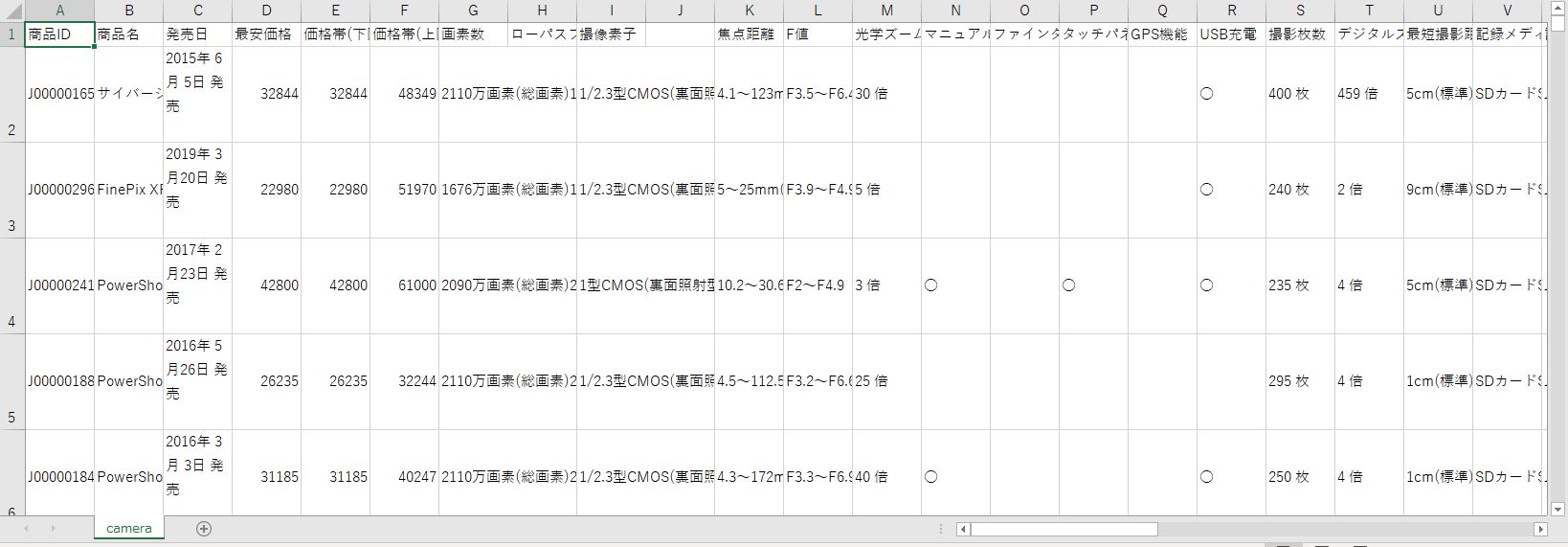
出力されたCSVは次の様になりました。
まとめ
今回はPythonを使ったスクレイピングで便利に使えるScrapeクラスを作ってみたので、それについて解説致しました。
また、前回記事で掲載したソースコードをScrapeクラスを使うように書き換えたサンプルも紹介致しました。
クラスにどのような機能を持たせるかについては、個人の考え方がありますので、あくまでも1つの例として参考にして頂ければと思います。
ちなみに、商品一覧のURL部分を書き換えるだけで、価格.COM に掲載されている他の商品にも対応できそうです。
全て試したわけではありませんが、ノートPCとかデジタル一眼は、この方法でうまくいきました。
今回の記事が皆様のお役に立てば幸いです。








コメント