今回は、PythonでWebスクレイピングをするために知っておきたいことを、図とサンプルを使ってやさしく解説したいと思います。
スクレイプの記事はたくさんありますが、技術的なことやサンプルの提示で終わっていることが多く、スクレイプ対象サイトのHTMLに対して、どのようにプログラムを組み立てていくかについて殆ど触れられていないのが現状です。
この記事では、「価格COMからスペック情報を取り出す」というケースを想定し、具体的にHTMLのどの部分に着目し、どうプログラムを組み立てれば良いのかについて、必要となる基礎知識を含めて解説することにしました。
図やサンプルも豊富に掲載しましたので、スクレイプについて具体的なプログラミングが知りたい方は、是非ご一読ください。
スクレイピングとは
スクレイピング(Scraping)は直訳すると「こする」とか「削る」という意味になりますが、ITの世界では「Webサイト上に存在する情報又はデータを収集する」という行為のことです。
よく似た行為としてクローリングという言葉がありますが、こちらは「Webサイトの内容や構造を把握する」ために定期的に行われるもので、その目的が異なります。
ちなみに、両者は同じ技術を使います。
スクレイピングの注意点
ここでは、スクレイプする上でよく問題となる2点について解説しておきます。
対象Webサイトへのアクセス負荷
スクレイピングで最も気を付ける必要があるのは、Webサイトへの負荷です。
プログラムを使って対象となるWebサイトを閲覧し、掲載されている内容を取得するわけですから、大量ページに対して絶え間なく連続アクセスすることは非常に簡単です。
この時、対象となるWebサイトのサーバ性能が低ければどうなるでしょう。
あっという間にサーバに負荷がかかり、最悪の場合はサーバがダウンしてしまいます。
実際、2010年に「岡崎市立中央図書館事件」が発生し、逮捕となった事例もあります。
これを期に、スクレイプの際は1ページにつき1秒程度のウエイト時間を設けることが暗黙のルールとなっていますので、この点だけはご注意下さい。
対象Webサイトはスクレイピングを許可しているか
スクレイピングによるデータ収集を許可していないサイトが数多く存在します。
たとえば、Amazonはその一例です。
スクレイプして良いかの判断は利用規約を参照するか、Webサイトのルートにある robots.txt の中身を確認することで判断できます。
利用規約を確認する
例えば、Amazon の利用規約(抜粋)には次の様に書かれています。

Webサイトの robots.txt を確認する
方法は次の通りです。
WebサイトのURLのルート/robots.txt
例えば、メルカリの場合、URLは https://jp.mercari.com なので、その直後に robots.txt を付けて
https://jp.mercari.com/robots.txt
とブラウザのアドレス欄に入力します。
結果、以下の通りとなりました。

ただ、全てのサイトでこの方法が使えるわけではなく、robots.txt 自身が参照できない場合もあります。
スクレイプしたいサイトが不許可だった場合
不許可だった場合は諦めるしか方法はありません。
但し、Webブラウザでの閲覧は可能なわけであり、閲覧した結果はHTMLとしてブラウザ内に存在するわけですから、これを使うことは可能です。
ただ極端な話ですが、人が操作する時と同じタイムラグを作り出せればWebサイト側はパソコンでやっているか人がやっているか判断が出来ない訳ですから、ウェイト時間を長くしてあげれば良いかと思います。
ただ、あくまでも自己責任でお願いします。
スクレイピング用ライブラリの使い方(基礎編)
では、最初にスクレイピングに必要な知識について解説していきたいと思います。
スクレイプに必要な3種の神器
Pythonでスクレイプする場合は、次の3つのライブラリが有名です。
| Requests | 対象となるWebサイトにHTTPリクエストを送信し、結果をHTMLとして受取る |
| BeautifulSoup | HTMLの中から指定した要素名や属性のデータを検索し、取り出す |
| Selenium | IEやChromeなどのブラウザを操作する |
この3つを図で表すと、以下の様な位置づけになります。
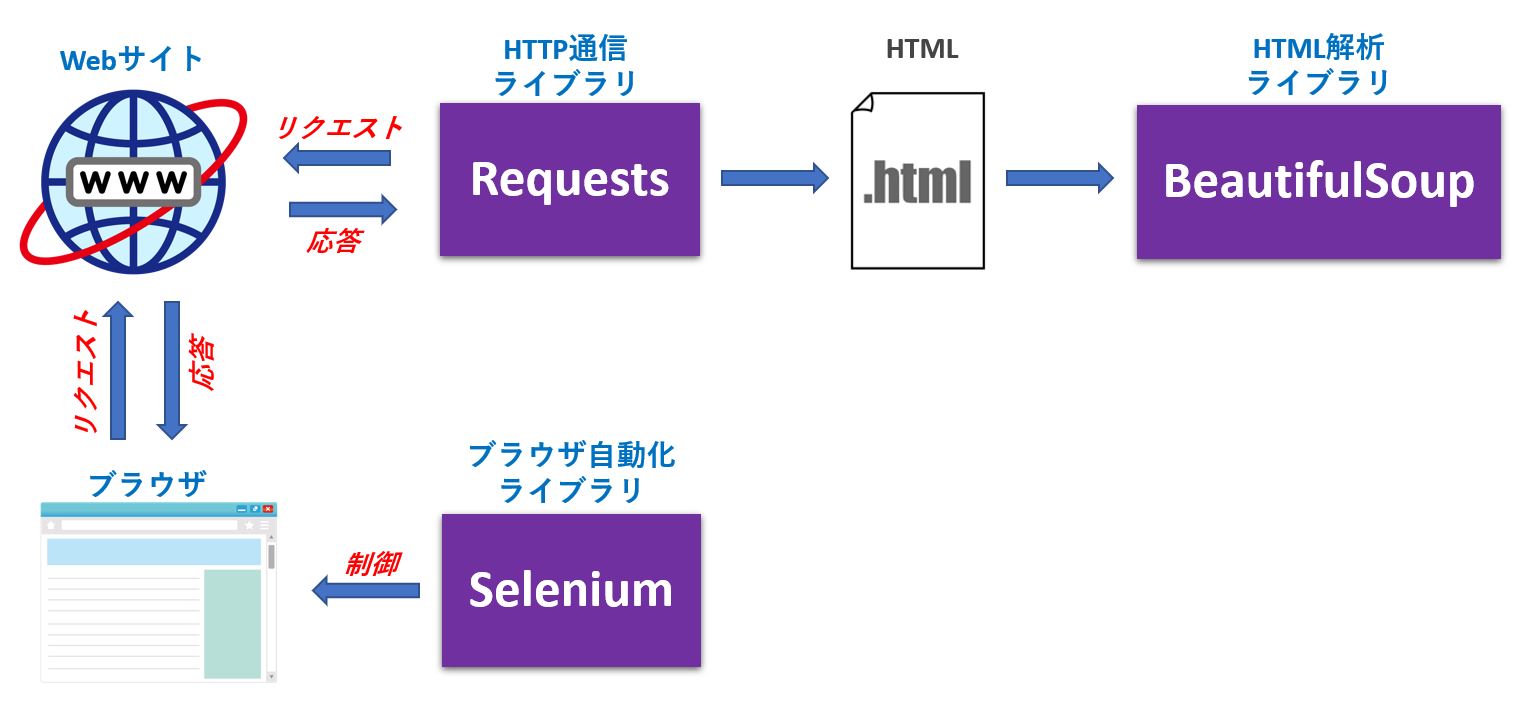
もちろん、同じ様な機能を持つライブラリはこれ以外にも存在しますが、ここでは割愛します。
また、Webスクレイピングでは Requests と BeautifulSoup で用が足りるため、この記事ではこの2つだけを取り扱います。
ページの取得
ページを取得するには requests ライブラリを使います。
Python には標準でHTTP通信用ライブラリも存在しますが、こちらの方が使いやすいので今回はこれを使います。
あらかじめ、requests をインポートして下さい。
import requests使い方は簡単で、次の様に記述します。
response = requests.get(URL)
戻り値に requests.models.Response クラスのオブジェクト(response)が返って来ます。
このオブジェクトにある contents プロパティにはバイト型のHTMLが格納されていますが、テキストとして取り出したい場合は、textプロパティを参照することで取り出せます。
HTMLの解析と要素、属性を使った検索
次は BeautifulSoup の出番です。
あらかじめ、BeautifulSoup を インポートして下さい。
from bs4 import BeautifulSoup次に requests.get で取得したオブジェクト(response)のcontent プロパティを BeautifulSoup の引数に渡します。
soup = BeautifulSoup(response.content, "html.parser")
第2引数は、第一引数で渡されたコンテンツ(今回はHTML)を解析するための「解析器」の種類を指定するものです。
| パーサー | 引数の値 | 内容・特徴 |
|---|---|---|
| Python’s html.parser | html.parser | HTMLの解析器であり、標準搭載されている |
| lxml’s HTML parser | lxml | html.parserより高速だが、追加でインストールが必要 |
| lxml’s XML parser | xml | XMLの解析器 |
| html5lib | html5lib | HTML5に対応した解析器 |
BeautifulSoupの戻り値として、bs4.BeautifulSoup オブジェクトが返されます。
このオブジェクトに対して、find や find_all メソッドを使って、任意のHTMLタグを取り出します。
| メソッド名 | 機能 | 書式 |
|---|---|---|
| find | 条件に一致した1件目の値を返す 戻り値の型:bs4.element.Tag | find(要素名) find(要素名,属性名='値') find(要素名,attrs={'属性名':'値'}) |
| find_all | 条件に一致した全ての値をリスト形式で返す 戻り値の型: bs4.element.ResultSet | find_all(要素名) find_all(要素名,属性名='値') find_all(要素名,attrs={'属性名':'値'}) |
find は最初に見つかった1件を返すのに対し、find_all は複数の結果が返されるため、たとえ1件しか見つからなくてもリスト形式(厳密には bs4.element.ResultSet クラスのオブジェクトだが、添え字が使える) で返されます。
下記は find_all ですが、引数は find と同じなので、必要に応じて読み替えてください。
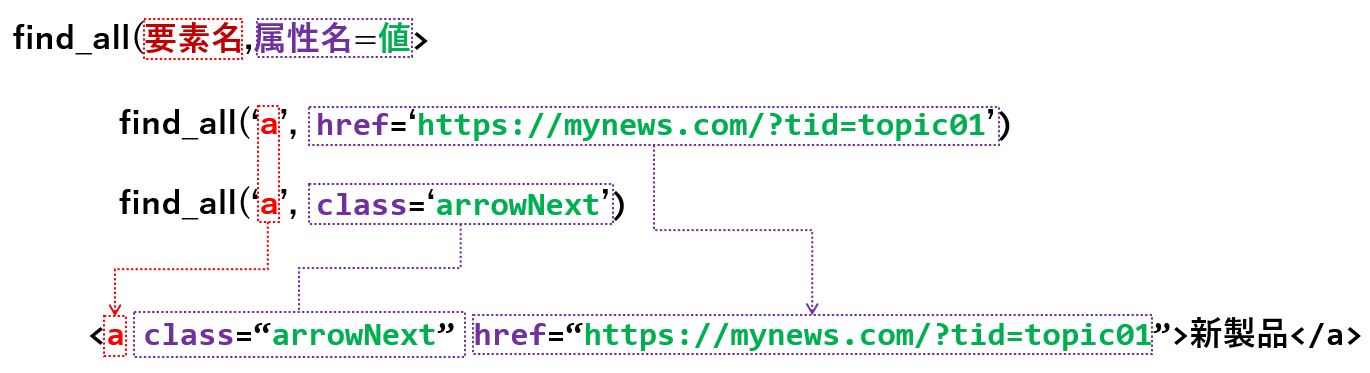
#アンカータグを全て取得
tr = soup.find_all('a')
#クラス名が tblBorderGray mTop15 のtableタグを取得
table = soup.find_all('table',class_='tblBorderGray mTop15')属性にclassやname を使う場合、Pythonのキーワードと被るため、末尾にアンダースコアを付加する必要があります。
例: class → class_ , name → name_
また、find_all の結果から、更に find や find_all でタグを取り出す事も可能です。
#クラス名が tblBorderGray mTop15 のtableタグを取得
table = soup.find_all('table',class_='tblBorderGray mTop15')
#返されるリストの0番目のtableタグから更にtrを取り出す
trs = table[0].find_all('tr') 取り出したタグからテキストを取り出すには text プロパティを使います。
find又はfind_allの戻り値.text
例えば次のようになります。
#タイトルタグからタイトルの文字列を取得
soup.find('title').text
#テーブルタグの中身を文字列として取得(複数のテーブルタグが返される可能性があるので
#添え字の先頭[0]を指定
soup.find_all('table')[0].text検索結果から要素を取得
検索した結果に対して、要素名を使って値を取り出す事が可能です。
find 又は find_all の戻り値に対して、次のメソッドを使います。
| メソッド名 | 機能 | 書式 |
|---|---|---|
| get | 指定した属性名の値を取得する | get(属性名) |
| attrs | 指定した属性名の値を取得する | attrs[属性名] |
これら2つは書き方が異なるだけで、同じ動作になります。
find の戻り値に対しては単にメソッドを呼ぶだけで済みますが、find_all の場合は複数の値が返されるため、添え字の番号を使って行を特定する必要があります。

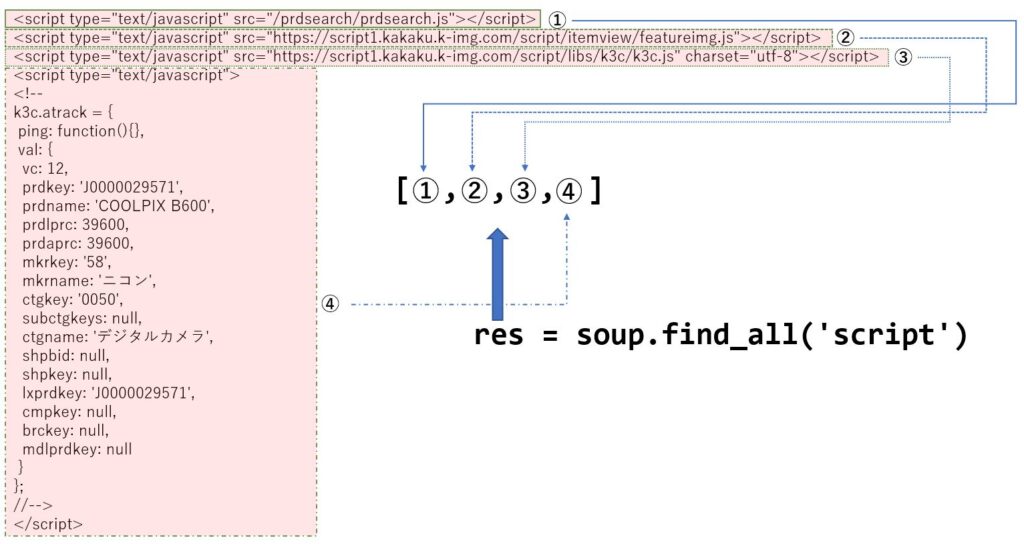
スクリプトを取得
HTMLに埋め込まれているスクリプトを取得する場合は、次の様に記述できます。
find_all('script')
結果は、次の様になります。
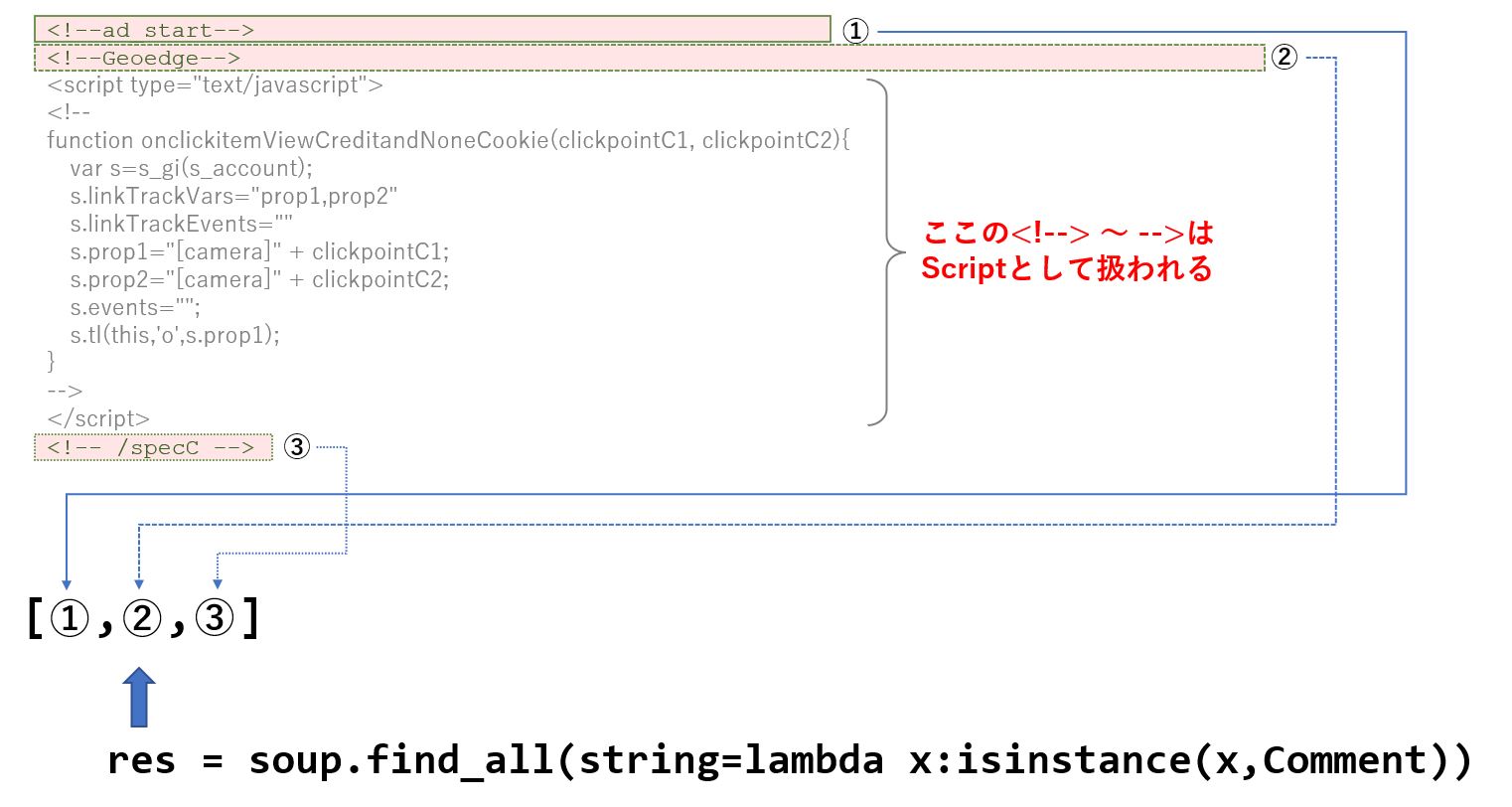
コメントを取得
HTMLに埋め込まれているコメントを取得する場合は、次の様に記述できます。
ただ、あらかじめ from bs4 import Comment が必要になります。
from bs4 import Comment
find_all(string=lambda x:isinstance(x,Comment))
結果は、次の様になります。
スクレイピングの手順(実践編)
ここからは実践編です。
価格.comに登録されているデジタルカメラのスペックを取り出すというシナリオで、スクレイピングの手順について解説してきます。
スクレイピングの方針を立てる
価格.comには221製品のデジタルカメラが掲載されています。
まず、どのようにすれば目的が達成できるかについて、ターゲットのサイトの動きやURLの変化を見ながら検討します。
まず、今回スクレイピングしたいページは下記の商品詳細ページの「スペック情報」です。
ただ、掲載されているデジタルカメラは200台以上あるため、最初に製品のリストを取得し、それを使って個々の製品詳細ページにジャンプするというやり方が良さそうです。

商品は221製品あり、商品一覧ページは1ページ当たり40製品の複数ページで構成されています。
ここには、個々の商品詳細ページにジャンプするためのURLが含まれているはずなので、まずそれを取得することを考えます。
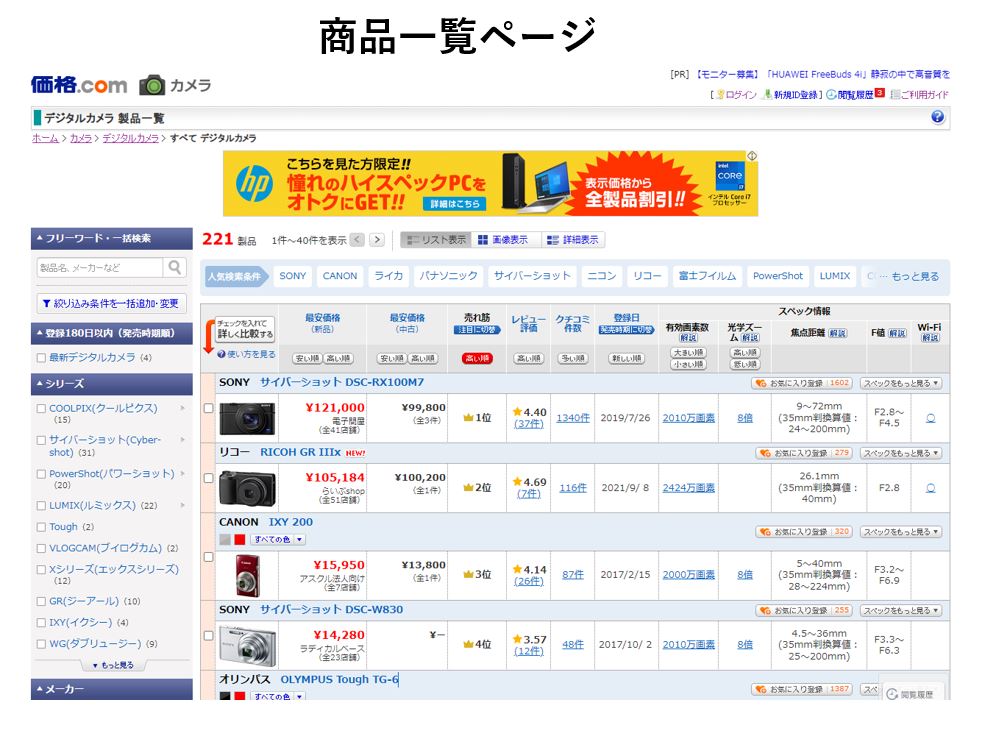
商品一覧のHTMLを解析する
商品一覧の動きを調べたところ、
https://kakaku.com/camera/digital-camera/itemlist.aspx?pdf_pg=ページ番号
というURLのフォーマットになっていて、末尾のページ番号を変えることで任意のページを表示できることが分かりました。
また、ブラウザを右クリックし「ページのソースを表示」を選択するとHTMLが表示できますので、画面とHTMLを見比べながら解析してみると、赤枠で囲ったところが商品詳細ページに行くための元となるURLだと分かりました。

一方、商品詳細のURLは、"https://kakaku.com/item/J0000030692/spec/#tab" となっているので、赤枠のURLの末尾に "/spec/#tab" を付けるだけで、商品詳細ページにジャンプできます。
詳細ページのHTMLを解析する
次に、詳細ページの「スペック情報」からどのようにデータを取得するかを考えます。
ブラウザ右クリックでHTMLのソースを確認すると、スペック表は次の様な構造になっていることが分かりました。
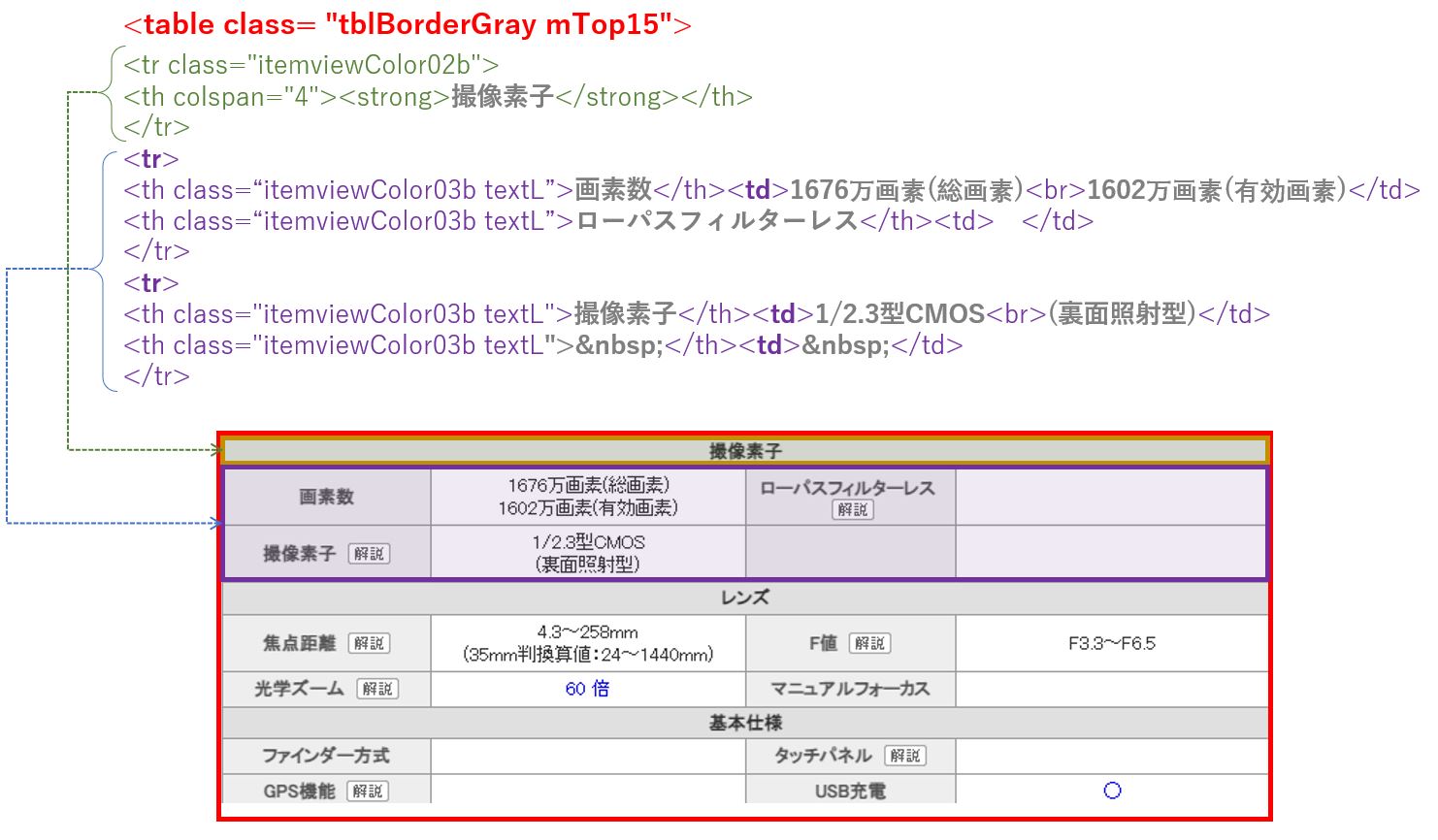
となると、次の手順で取得できそうです。
- find 又は find_all で 要素名が "table" クラス名が "tblBorderGraymTop15" をタグを検索、
- その結果から "tr" タグを検索
- その結果から "th" と "tr" を取り出す
サンプルソース
以上のことを踏まえ、次の様なスクレイピングのサンプルプログラムを作りました。
念のため、1ページスクレイプするごとに、2秒のウェイトを入れています。
商品一覧ページは6ページあるので、それぞれのページに記載されている商品詳細ページを取得し、テーブルタグの中身を抽出し、DataFrameに格納の上、CSV出力しています。
# pip install requests
# pip install beautifulsoup4
import requests
from bs4 import BeautifulSoup
from bs4 import Comment
import time
import pandas as pd
df = None
for page in range(6):
#商品一覧ページを取得
response = requests.get(f'https://kakaku.com/camera/digital-camera/itemlist.aspx?pdf_pg={page + 1}')
#商品一覧に含まれるurlを全て取得
soup = BeautifulSoup(response.content, "html.parser")
links = [x for x in [url.get('href') for url in soup.find_all('a')] if x is not None]
#重複しているurlを削除
links = list(set(links))
#取得したurlの数だけループ
for link in links:
#商品詳細ページのurlか否かを判定
if 'https://kakaku.com/item/' in link:
#ウェイト処理
time.sleep(2)
#商品詳細ページのurlからスペック情報のurlを作成し、ページ内容を取得
response = requests.get(f'{link}spec/#tab')
#取得したHTMLからtableタグを検索
soup = BeautifulSoup(response.content, "html.parser")
table = soup.find_all('table',class_='tblBorderGray mTop15')
#指定したクラスのtableタグが無ければ何もしない
if table == []:
continue
#商品ID,商品名,発売日を取得
columns = ['商品ID','商品名','発売日']
values = [
link[-12:-1],
soup.find('h2',itemprop='name').text,
soup.find('span',class_='releaseDate').text
]
#tableタグの中身からスペック情報を取り出す
trs = table[0].find_all('tr')
for tr in trs:
ths = tr.find_all('th')
tds = tr.find_all('td')
for th,td in zip(ths,tds):
columns.append(th.text)
values.append('' if td is None else td.text)
#df が None ならDataFrameを作成
if df is None:
df = pd.DataFrame([values],columns=columns)
#DataFrameにスペック情報を格納
df = df.append(pd.Series(values,index=columns),ignore_index=True)
cnt += 1
#カラム名が'/xa0'で値が空の列が7列作られるので、削除する
df.drop('\xa0',axis=1,inplace=True)
#CSVにシフトJISで書き込む。シフトJISに変換できないコードが含まれていても無視する。
df.to_csv('d:/digicame.csv',index=False,encoding="shift-jis",errors="ignore")
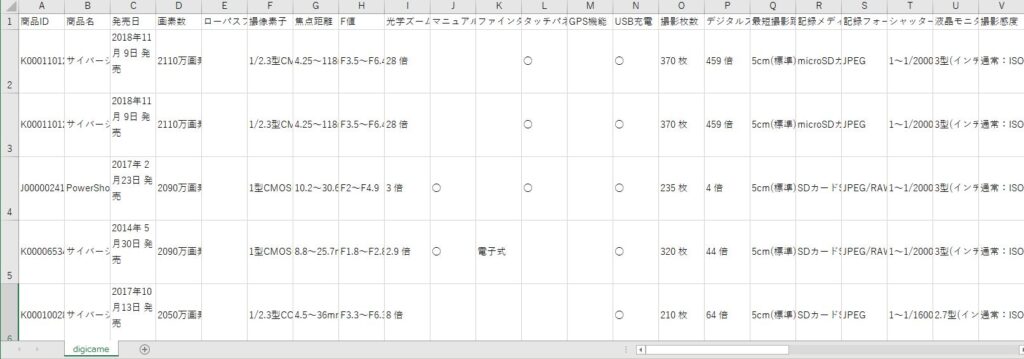
下記の図は、スクレイピングによりCSVに出力された結果を、EXCELで開いたものになります。
まとめ
今回はスクレイピングで使うライブライの基本的な使い方と、これらライブラリを使って実際にスクレイピングする手順について、価格.com を題材としたシナリオで解説致しました。
スクレイピングは禁止されているサイトも多いですが、公開されているものも多いので、是非ご活用下さい。
ただ、スクレイピングする上に置いて、相手のサイトの迷惑にならないよう、十分なウェイト時間を入れることをお忘れなく。
この記事が皆さんの役に立てば幸いです。








コメント