「【最短&簡単】Stable diffusion web UI インストール方法(AUTOMATIC1111版)」の記事では、stable diffusion のインストール方法について解説しました。
今回は使い方について解説したいと思います。
とはいえ stable diffusion Web UI の機能は非常に多く、日々バージョンアップされているため、全てを網羅することはできません。
そこで、本記事では、入門者が最初に知っておきたい機能について、一通り紹介したいと思います。
本記事の内容で大枠と基本的な使い方を理解してから、必要に応じて個々の機能の詳細について、深堀していただければ効率的です。
stable diffusion の画面構成
ここでは、画面全体の項目についてザックリと紹介します。
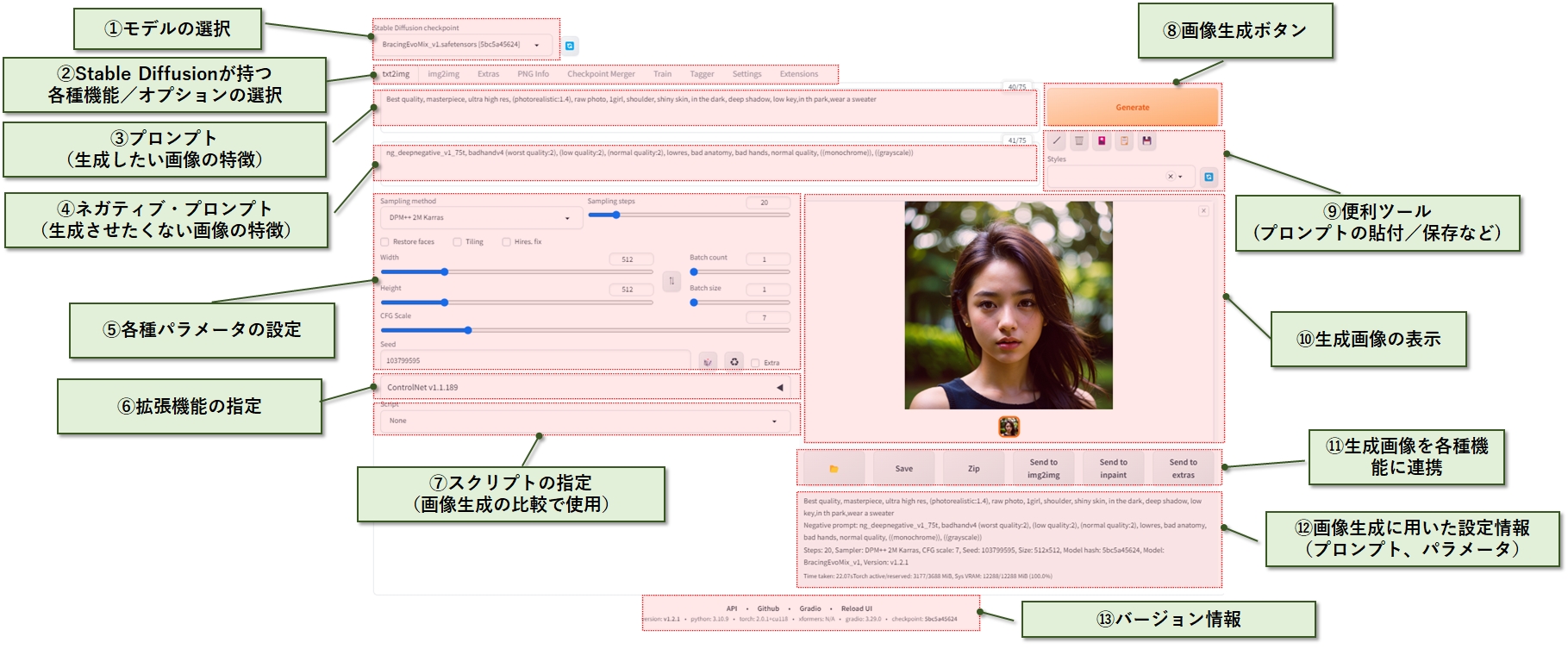
| ①モデルの選択 | 画像生成で使いたいモデルを選択します。 初期状態は1つだけなので、必要に応じて追加します。アニメキャラやフォトリアルなど、各ジャンルに特化した数多くのモデルが用意されています。 |
| ②Stable Diffusionが持つ 各種機能/オプションの選択 | 画像生成の補助機能を選択します。 例えば、テキストから画像生成、既存の画像を元に画像生成、生成画像の高解像度化、複数モデルの統合、 拡張機能のインストールなどがあります。 |
| ③プロンプト (生成したい画像の特徴) | 生成したい画像の特徴を英文又は英単語の列挙で指示します。(例:a red sports car,at the beach,the shining sun.) |
| ④ネガティブ・プロンプト (生成させたくない画像の特徴) | AIは人間や動物の手足、顔などの生物学的特徴を理解していません。これにより、手や足の本数や、位置が崩れる場合があるので、禁止したい特徴として記述します。 (例:low quality,bad anatomy,missing fingers,bad hands) |
| ⑤各種パラメータの設定 | 生成する画像のサイズや、1度に生成する画像の枚数、画像サイズ、その他品質や処理速度に関する値を設定します。 |
| ⑥拡張機能の指定 | stable diffusion 用に作られた拡張機能をインストールした際、ここから選択できるようになります。 |
| ⑦スクリプトの指定 (画像生成の比較で使用) | 指定したバラメータを少しづつ変更しながら画像を生成し、1枚の画像に並べて比較する時に使用します。 |
| ⑧画像生成ボタン | 画面の設定内容(プロンプト、パラメター)に従って画像生成します。 |
| ⑨便利ツール (プロンプトの貼付/保存など) | 現在のプロンプトの内容をファイルに保存したり、逆に読み出すことができます。また、プロンプトの内容を消去したり、LoRAなどの一覧管理 ができます。 |
| ⑩生成画像の表示 | 生成された画像が表示され、クリックすると拡大できます。 |
| ⑪生成画像を各種機能に連携 | 生成された画像の保存フォルダを開いたり、現在表示されているプロンプトや画像をstable diffusion内の他の機能(画面)に転記することが出来ます。 |
| ⑫画像生成に用いた設定情報 (プロンプト、パラメータ) | 現在表示中の画像に関する設定情報が表示されています。 |
| ⑬バージョン情報 | stable diffusionや、Pythonのバージョンが表示されています。 |
最小限の設定例
インストール直後であればモデルは変更できないので、とりあえず画面項目の①プロンプト、②ネガティブプロンプト、③Sampling method の3項目に対して、それぞれ以下の通り入力(設定)し、Generateボタンをクリックしてみてください。
| ① | Best quality, masterpiece, ultra high res, (photorealistic:1.4), raw photo, 1girl |
| ② | (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, normal quality, ((monochrome)), ((grayscale)) |
| ③ | DPM2 |

各パラメータの意味・役割
画像生成の品質や条件を設定するためのパラメータには、次のものがあります。

| ①ノイズを除去するアルゴリズムの選択 (Sampling method) | アルゴリズムを変更すると、生成される画像の雰囲気や画質が大幅に変わる |
| ②顔の補正や高解像化の設定 (Restore face,Tiling,Hires.fix) | Restore face:顔の左右対称の崩れを補正する Tiling:画像をタイル状に表示する Hires.fix:画像の解像度を上げ、かつ細部を作りこむ |
| ③生成する画像の横幅 (Width) | 画像の横幅。stable diffusion Ver1 は512x512の画像を学習しているため、横幅を広げ過ぎると画像が破綻する。 |
| ④生成する画像の高さ (Height) | 画像の高さ。stable diffusion Ver1 は512x512の画像を学習しているため、横幅を広げ過ぎると画像が破綻する。 |
| ⑤プロンプトの指示にどれだけ従うかの指定 (CFG Scale) | 値を高くするほどプロンプトの指示に従うが、上げ過ぎると画像が破綻する。 |
| ⑥画像生成で使用する乱数の種(seed) (Seed) | 学習で用いる乱数の種(seed値)。-1にすると1画像づつ変化する。以前生成させた画像のseed値を入力すると、ほぼ同じ画像が生成される。 |
| ⑦ノイズ除去の回数 (Sampling steps) | ①で選択したノイズ除去アルゴリズムを何回実行するかを指定する。数が多いほど高画質になるが、時間が掛かる。 |
| ⑧1回のGenerate で生成させたい画像の枚数 (batch count) | 1回のGenerateボタンで複数の画像を生成させたい場合、その枚数を指定する。 |
| ⑨画像生成の処理ステップ(Batch)を何個づつ行わせるかの指定(batch size) | 処理ステップはGPUのメモリに読み込まれて並列処理される個数。GPUが12GBの場合、4が上限。 |
設定のポイント
変更する箇所はたくさんありますが、①ノイズを除去するアルゴリズム(Sampling method)によって、生成される画像の雰囲気(細部の描画)や画質が大きく左右されます。
Sampling method使うモデルによって相性が存在するため、そのモデルが公開しているサンプル画像のアルゴリズムを指定するのが無難ですが、あえて異なるアルゴリズムにすることで、違った画像を生成してみるというのも良いと思います。
注意点としては、横幅(Width)と高さ(Height)の指定を、あまり大きくしない方が良いという点です。stable diffusion 1.0 は 512x512 の画像を学習しているため、2048x1024 などの巨大なサイズを指定すると、生成に時間が掛かるだけでなく、生成される画像が破綻します。
高画質が欲しい場合は、Hires.fix にチェックを入れるか、後述する Extrasを使用(txt2imgタブから2つ右のタブ)して下さい。
stable diffusion が持つ各種機能
Stable Diffusionが持つ各種機能/オプションには次のものがあります。

| ①テキストから画像を生成 | stable diffusion 起動時の初期画面です。 |
| ②画像を元に画像を生成 | 既にある画像の一部を指定して、その部分だけ画像生成するなどが出来ます。 |
| ③生成済み画像の高解像化 | 生成済みの画像を高解像化します。Hires.fixにチェックを入れるより画質は劣りますが、高速に処理できます。 |
| ④生成済み画像から設定情報 (プロンプト、パラメータ)の読み出し | 生成済み画像の設定情報(プロンプト、パラメータ)を読み出します。ボタン1つでtxt2img に反映できます。 |
| ⑤複数モデルの配合 | 複数の学習済みモデルを融合して、新しいモデルを生成します。 |
| ⑥モデルのトレーニング | 既存のモデルに追加学習します。 |
| ⑦オプション項目の設定 | 画面項目の表示/非表示から動作に関することまで細かく設定できます。 |
| ⑧拡張機能のインストールと管理 | stable diffusion 専用の拡張機能のインストールと管理が出来ます。 |
よく使う機能
ここでは、簡単に使える便利な機能について紹介しておきます。
プロンプトの消去、保存、読み込み
Generateボタンの下にある5つのアイコンは、プロンプトへの入力に関する便利な機能です。私も最初にstable diffusion を触り始めたときは、プロンプトの保存と読み込み方法を知らなかったので苦労しました。
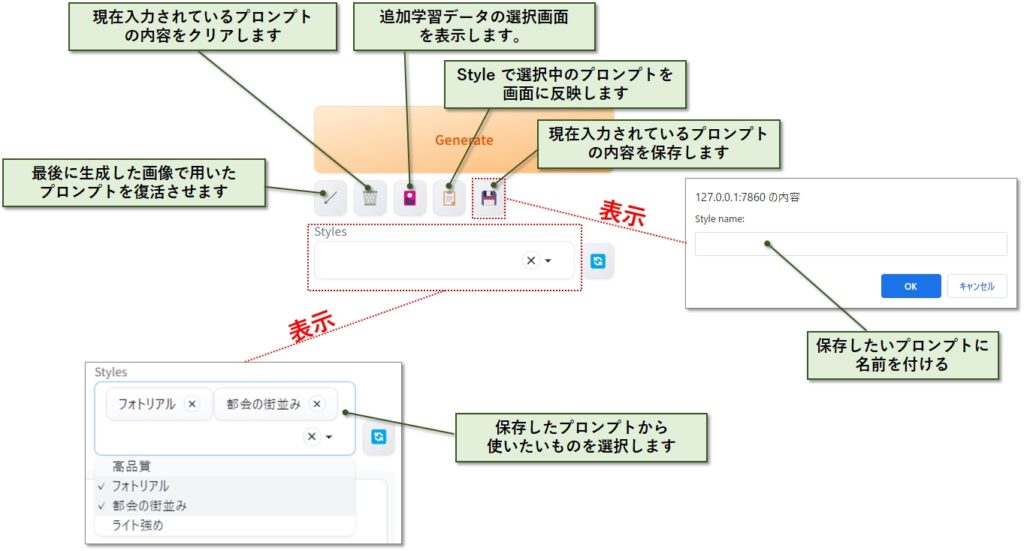
プロンプトに関する便利機能の中に、なぜ追加学習データの選択アイコンがあるのか不思議に思われるかもしれません。
詳しくは「【詳しく解説】Stable diffusion モデルのダウンロードと便利機能の紹介」で紹介していますが、追加学習データを使う際はプロンプトに記述する必要があるため、ここにアイコンが用意されています。
画像の高解像化
stable diffusion は 512x512 の解像度で画像を学習しているため、Width と Height に 2000を超える値を指定すると、膨大な処理時間が掛かったにも関わらず期待した画像が生成されない、あるいは画像が破綻するなどの問題が発生します。
そこで、一旦生成した画像を別の手法で高解像化することになります。高解像化にもいくつかの方法がありますが、ここでは標準搭載されていて、かつ簡単に利用できる2つの方法についてご紹介します。
Hires.fixを使う
いちばん簡単に高解像化する方法で、Hires.fix にチェックを入れるだけです。単に画像を拡大するだけではなく、拡大して荒くなった部分の画像を再生成してくれるため、高品質な拡大画像が得られます。
デメリットとしては、再生成に掛かる時間が掛かることと、再生成によって細部が元画像と変わってしまうことです。
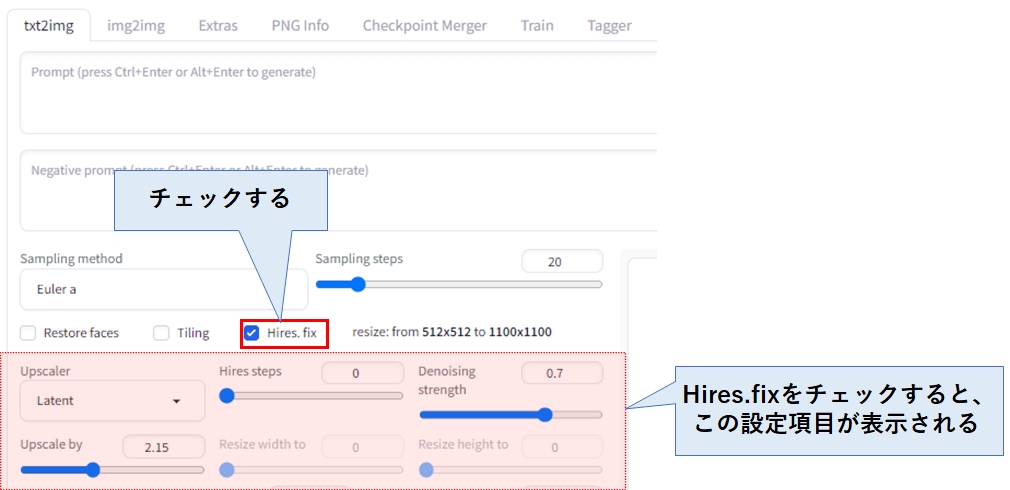
Hires.fixにチェックを入れると、下記の設定項目が表示されます。初期状態のままだと縦横2倍に拡大されます。
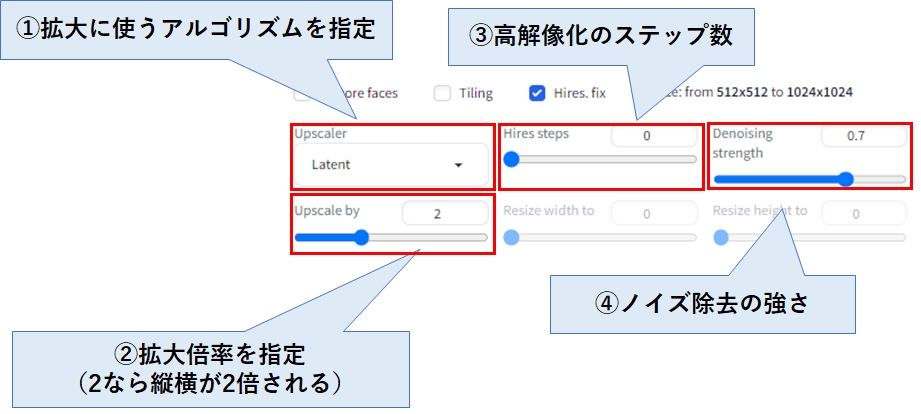
| ①拡大に使うアルゴリズムを指定 | 初期状態(Latent)のままでも綺麗に拡大してくれますが、画像のジャンルによって結果も変わってくるので、試行錯誤が必要となります。 例えば、以下のアルゴリズムがよく使われているようです。 R-ESRGAN-4x+ R-ESRGAN-4x+-Anime6B |
| ②拡大倍率を指定 | 初期状態は2になっているので、縦横2倍に拡大されます。値を大きくすると生成時間が長くなっていくのでご注意ください。 |
| ③高解像化のステップ数 | 特に理由がない限り、初期状態のままで問題ありません。 |
| ④ノイズ除去の強さ | ノイズ除去=再生成と解釈して下さい。値を上げると再生成の量が増えるため、元画像と異なった絵になりやすいです。 |
Extrasタブを使う
Extrasタブにファイルをドラッグ&ドロップし、拡大倍率と拡大アルゴリズムを指定したら、Generateボタンをクリックするだけです。
Hires. fix と違って、こちらは画像の再生成は行われないため圧倒的に速いです。元画像をできるだけ変えないで、単に解像度だけをアップしたい場合はこちらを利用します。

Extrasタブの中に用意されている Batch from Directory を選択すると、フォルダに格納されている画像をまとめて拡大してくれるので、とりあえず512x512 で画像を生成し、気に入った画像をまとめて拡大する場合は非常に重宝します。
画像から設定情報の読み取り(PNG Info)
PNG Infoタブを選択し、生成した画像をドラッグ&ドロップすることで、この画像を生成したときの設定情報(プロンプト、パラメータ)が表示されます。
Extrasで拡大した画像であっても、問題なく設定情報を読み出すことが出来ます。
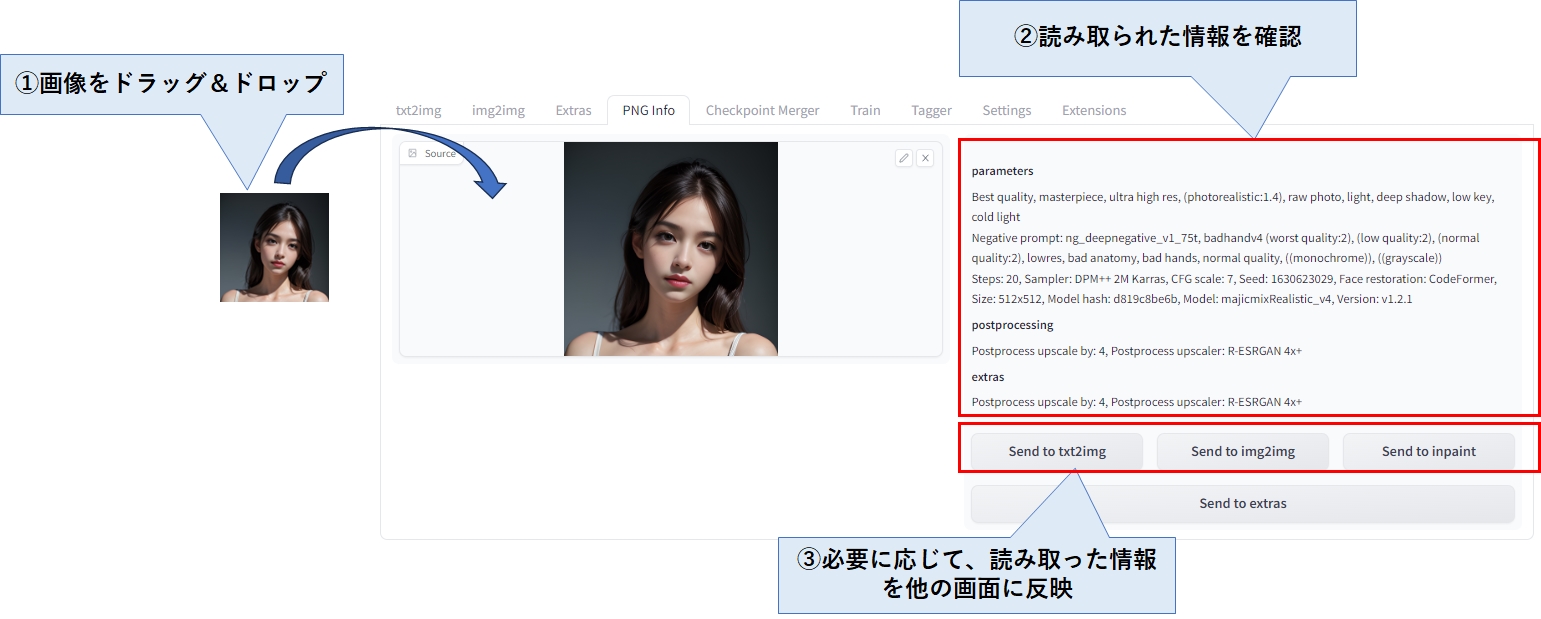
読み取った設定情報は、ボタン1つで簡単に txt2img や img2img 画面に反映することができます。
画像からプロンプトを生成する(img2img)
手元にある画像からプロンプトを生成したい場合は、Img2Imgタブの中にある Interrogate CLIP、または Interrogate DeepBooru ボタンを使用します。
Interrogate CLIP は英文でプロンプトを生成するのに対し、Interrogate DeepBooru はカンマ区切りで単語を列記してくれます。
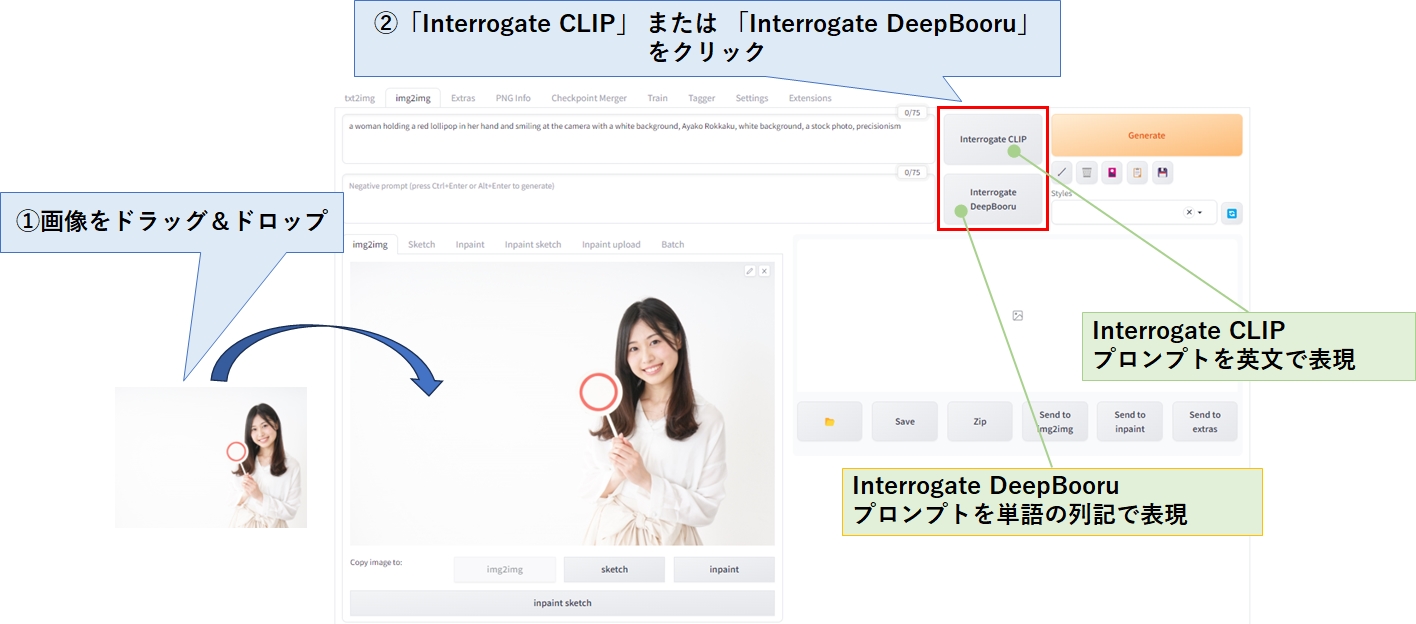
| ボタン | プロンプトの生成結果 |
|---|---|
| Interrogate CLIP | a woman holding a red lollipop in her hand and smiling at the camera with a white background, Ayako Rokkaku, white background, a stock photo, precisionism (赤いロリポップを手に持ち、白い背景でカメラに向かって微笑む女性、六角彩子、白背景、写真素材、精密主義) |
| Interrogate DeepBooru | 1girl, brown_hair, gradient, gradient_background, holding, lips, long_hair, long_sleeves, looking_at_viewer, nose, realistic, smile, solo, teeth, upper_body, white_dress (女の子1人、茶髪、グラデーション、グラデーション背景、ホールディング、唇、ロングヘア、長袖、ビューア視点、鼻、リアル、笑顔、ソロ、歯、上半身、白いドレス) |
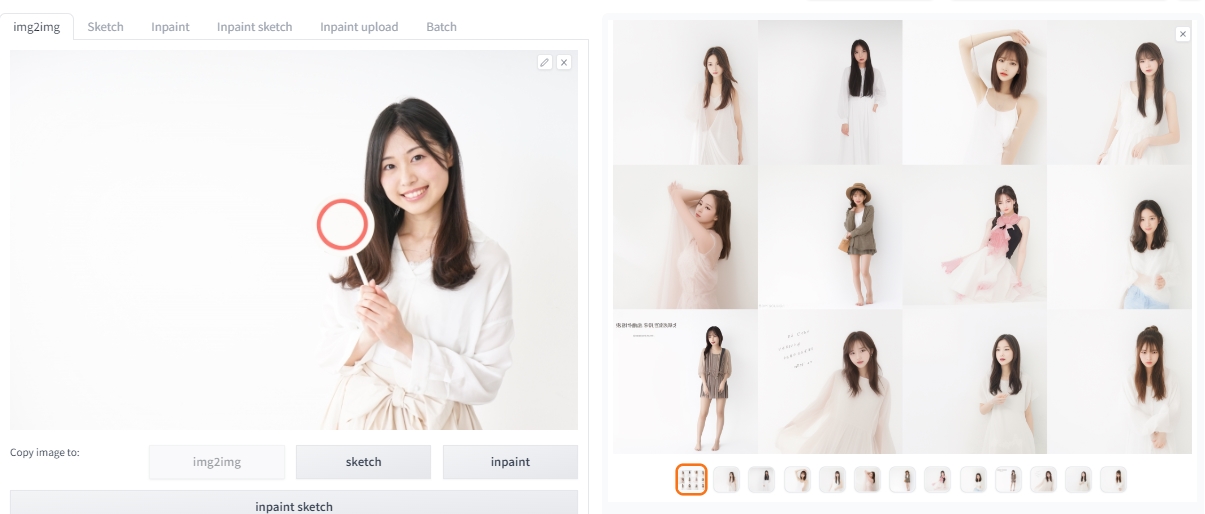
画像を元に新しい画像を生成する(img2img)
Img2Imgタブに画像をドラッグ&ドロップしてから、Genelateボタンをクリックすると、構図や雰囲気を読み取って、新しい画像を生成してくれます。

試しに12枚ほど生成してみましたが、左側にスペースを取り、右に立った女性を配置、背景や服装は白を基調とするなど、写真から雰囲気をくみ取って生成していることが分かります。
画像の一部を生成しなおす(img2img)
img2imgタブの inpaint を使えば、画像の一部を生成し直すことが可能です。
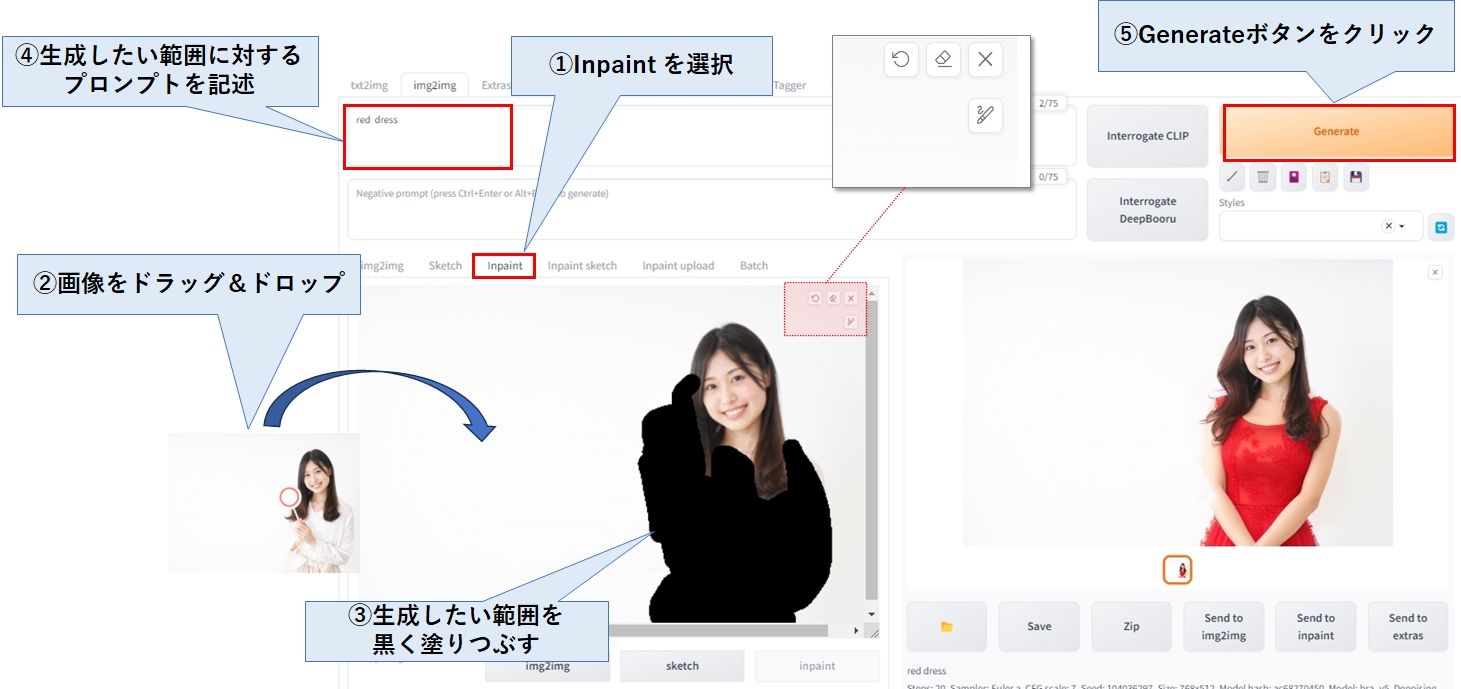
ドラッグ&ドロップした画像の右上に下記の編集用アイコンが表示されているので、これを使って生成したい箇所を塗りつぶします。
その際、生成させた範囲を少し広めに塗り潰すと、成功しやすいようです。
是非やっておきたいこと
インストールというひと手間が必要ですが、stable diffusion でより良い画像生成を行う場合、やっておきたいことについて紹介しておきます。
Clip skipの表示
stable diffusion は複数のステップを踏んで最終的な画像を生成しています。
各ステップごとに画質の向上が図られていますが、同時に人物のポーズや構図、人物や背景の描写なども変化させながら最終的な画像に仕上げています。
言い換えると、途中経過の中には「自分の意図通りで画質も十分」な画像が隠れていることも多く、たとえ最終結果が良くなくても、途中経過で満足な結果が得られる可能性があるのです。
そのため、ステップのどの段階で止めておくかを指定する機能が用意されており、これが Clip skipです。
Clip skipに関する詳細は、「【早分かり】隠れた救世主!clip skip の設定方法と使い方(Stable Diffution Web UI)」で紹介しています。
モデルのダウンロード
stable diffusion 向けに数多くのモデルが公開されています。
モデルはアニメ系、リアルフォト系、風景や建造物など、画像のジャンルごとに用意されています。無料で利用できますので、自分が生成したい画像のジャンルに合わせてダウンロードしましょう。
モデルに関する詳細は「【詳しく解説】Stable diffusion モデルのダウンロードと便利機能の紹介」で紹介しています。
VAEの導入
品質の高い(綺麗な)画像を生成する方法として、VAEというものがあります。インストール方法や使い方については「【図解明解】Stable Diffusion で簡単に画質を上げるVAE、EasyNegative、NegativeHandの極意」で紹介しています。
Control Net の導入
画像生成はプロンプトで指示を出すため、任意のポーズを指定することが非常に難しいです。また生成される画像ごとに顔が変わるため、同じ人物の顔を引き継いで様々な画像を生成することも困難です。
しかし、Control Net を使えば、これらのことが簡単に出来るようになります。
インストール方法と使い方については「【入門】画像生成の革命!Control-Netの使い方(Stable Diffusion Web UI)」で詳しく紹介しています。
ADetailer の導入
Hires.fixなどの高解像機能を使わず、512×512や512×768 などの推奨サイズで全身を使ったポーズを描画させた場合、顔が崩れてしまうことが多々あります。また、手を使ったポーズでは、手や指の描写がおかしくなることが多いです。
こんな時、自動で顔や手を認識して、顔や手の描画崩れを補正してくれる拡張機能がADetailer です。
インストール方法と使い方については、「【必見】stable diffusion で顔が崩れる、手が変になる問題を解決!ADetailerの使い方」で詳しく紹介しています。
まとめ
今回は、stable diffusion をこれから使い始める方に対して、最初に知っておきたい機能に絞って紹介しました。
個々の機能については数多くのサイトで説明されていますが、そもそもどんな機能が備わっていて、どこまで出来るのかが分からなければ、その機能を検索することすらできません。
初心者にとっては「個々の詳細情報」ではなく、「最低限使えるようになるための一通りの機能を網羅する」方が、やりたいことがより速く実現できます。
本記事を参考にしていただき、よりよい stable diffusion ライフを楽しんでいただけたら幸いです。



コメント