Pythonで画像処理を行う際は、OpenCVというライブラリがよく使われます。ディープラーニングが登場する前は、検品や自動運転で使われる物体検出、セキュリティで使われる顔認証は、全てOpenCVを使った画像処理が使われていました。
現在において、これらの処理はディープラーニングに置き換わりましたが、OpenCVに取って代わったという事ではなく、むしろディープラーニングによる認識精度を向上させるための前処理に、積極的に使われています。
そこで、今回はディープラーニングの前処理を念頭に、OpenCVの機能とサンプルを紹介したいと思います。
OpenCVとは
OpenCVは、画像処理やパターン認識などのタスクをサポートするオープンソースのライブラリです。OpenCVは、コンピュータがデジタル画像を扱い、画像に含まれる特徴を抽出したり、物体を検出したりすることができるように設計されています。
具体的には、OpenCVは以下の機能が用意されています。
- 画像の読み込み、表示、保存
- 画像処理(リサイズ、回転、フィルタリングなど)
- 特徴抽出(SIFT、SURF、ORBなどのアルゴリズム)
- 物体検出(Haar Cascade、DNNモジュール)
- カメラキャプチャと動画処理
- モーション分析(オプティカルフロー、背景差分など)
OpenCVは、C++、Python、Javaなど複数のプログラミング言語で利用できるため、幅広いプラットフォームで使用されています。また、ディープラーニングのサポートもあり、ディープラーニングモデルを組み込むことで高度な画像処理タスクも可能です。
詳しくは、OpenCV公式ページのチュートリアルをご参照ください。
OpenCVのインストール方法
OpenCVを使う場合は、あらかじめ pip 又は conda コマンドで OpenCVのライブラリをインストールする必要があります。
#Python公式サイトからPythonをインストールしている場合
pip install opencv-python
#anaconda経由でPythonをインストールしている場合
conda install -c conda-forge opencv
また、OpenCVを利用するプログラムには、 import cv2 を記述しておきます。本記事のサンプルでは、 numpy を使っている場合もあるため、下記の2行をプログラム冒頭に記載しておいてください。
import cv2
import numpy as npOpenCVの機能
ここからは、ディープラーニングの前処理として使えそうなOpenCVの機能についてサンプルを交えて紹介したいと思います。
画像の読み込み/表示/保存
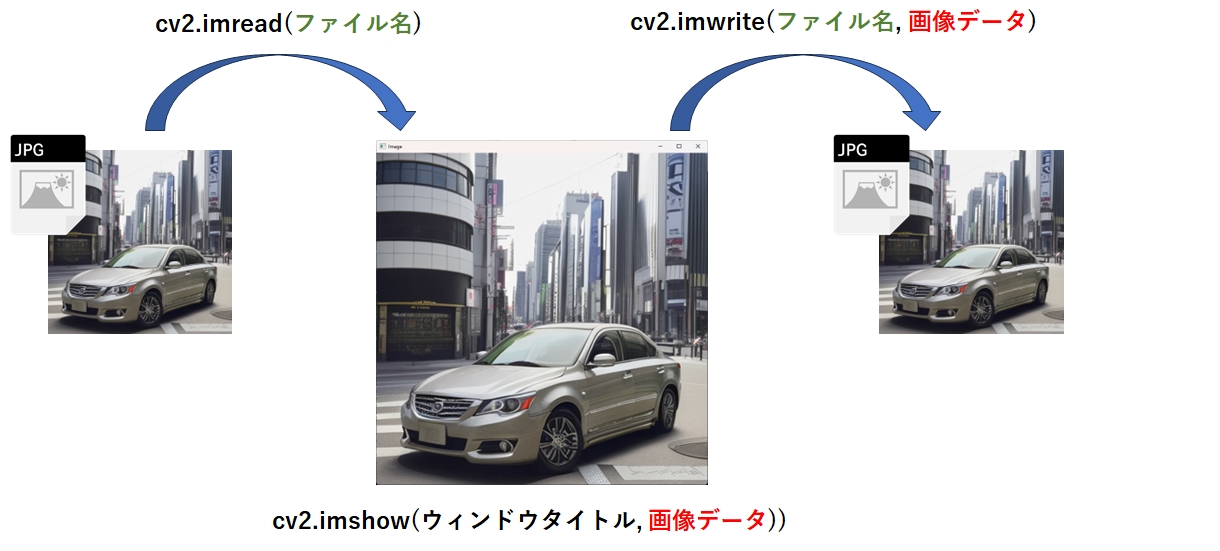
画像の読み込み
画像を読み込みます。
#カラーで画像を読み込む
image = cv2.imread('path/to/your/image.jpg')
#グレイスケールで画像を読み込む
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)画像の表示
画像をウィンドウ表示し、キーが押されるとウィンドウを閉じます。
# 画像を表示
cv2.imshow('Image', image)
# キー入力待機
cv2.waitKey(0)
# ウィンドウを閉じる
cv2.destroyAllWindows()画像の保存
画像をファイルに書き出します。
cv2.imwrite('path/to/your/image.jpg', image)画像のリサイズ
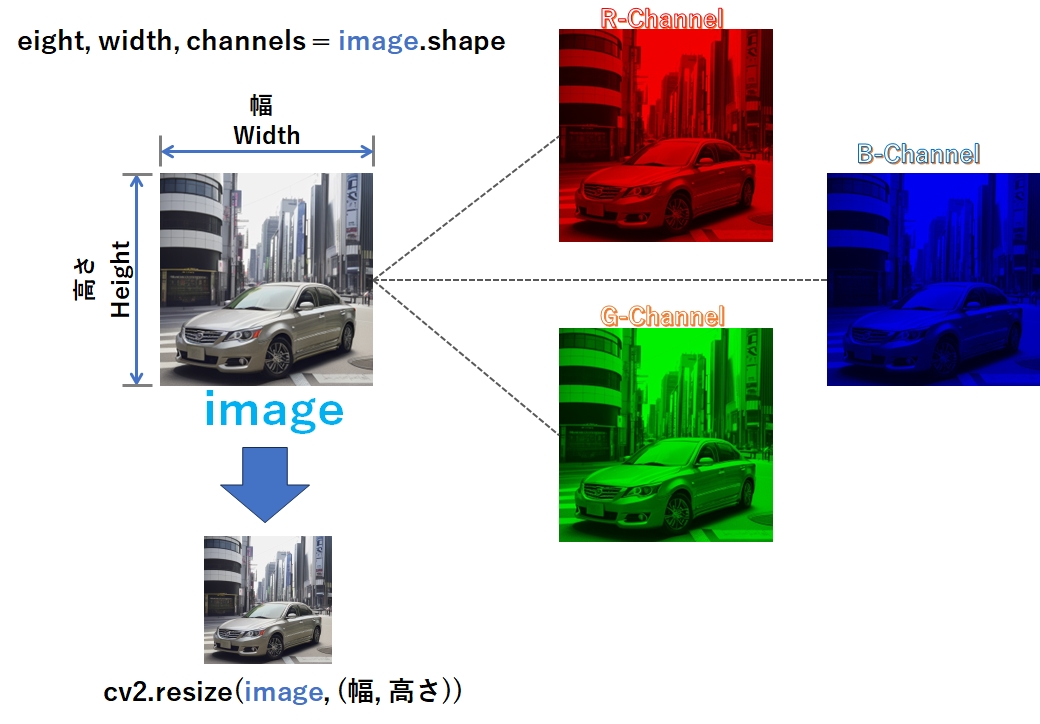
画像の幅・高さの取得
画像の高さ、幅、チャンネル数を取得します。
#高さ、幅、チャンネル数の取得
height, width, channels = image.shape
#高さ、幅の取得
height, width = image.shape[:2]画像のリサイズ
画像をリサイズします。
# リサイズ後の幅と高さを指定する
width = 300
height = 200
resized_image = cv2.resize(image, (width, height))図形の描画
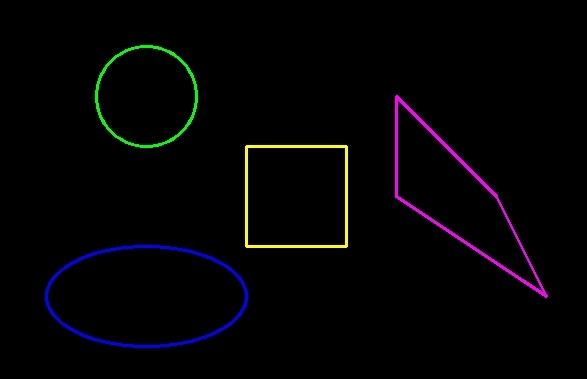
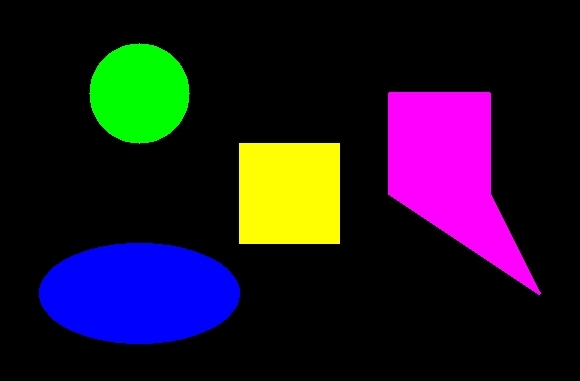
import cv2
import numpy as np
#真っ黒の画像を作成
width, height,channels = 400, 400, 3
image = np.zeros((height, width, channels ), dtype=np.uint8)
# ~描画したいコードをここに記述する~
# 画像を表示
cv2.imshow('Image', image)
# キー入力待機
cv2.waitKey(0)
# ウィンドウを閉じる
cv2.destroyAllWindows()四角形の描画
# 四角形を描画する
pt1 = (width // 2 - 50, height // 2 - 50) # 四角形の左上の頂点座標
pt2 = (width // 2 + 50, height // 2 + 50) # 四角形の右下の頂点座標
color = (0, 255, 255) # 枠の色(イエロー)
thickness = 2 # 枠の太さ。図形を塗りつぶしたい場合は-1を指定
cv2.rectangle(image, pt1, pt2, color, thickness)円の描画
# 円を描画する
center = (width // 4, height // 4) # 円の中心座標
radius = 50 # 円の半径
color = (0, 255, 0) # 枠の色(緑)
thickness = 2 # 枠の太さ。図形を塗りつぶしたい場合は-1を指定
cv2.circle(image, center, radius, color, thickness)楕円の描画
# 楕円を描画する
center = (width // 4, height // 4 * 3) # 楕円の中心座標
axes = (100, 50) # 楕円の長軸と短軸の長さ
angle = 0 # 楕円の回転角度
start_angle = 0 # 楕円の開始角度
end_angle = 360 # 楕円の終了角度
color = (255, 0, 0) # 枠の色(青)
thickness = 2 # 枠の太さ。図形を塗りつぶしたい場合は-1を指定
cv2.ellipse(image, center, axes, angle, start_angle, end_angle, color, thickness)多角形の描画
# 多角形の頂点を定義する
pts = np.array([[400, 100], [500, 100], [500, 200], [550, 300], [400, 200]], np.int32)
pts = pts.reshape((-1, 1, 2))
# 多角形を描画する
color = (255, 0, 255) # 枠の色(マゼンタ)
thickness = 2 # 枠の太さ。図形を塗りつぶしたい場合は-1を指定
cv2.polylines(image, [pts], isClosed=True, color=color, thickness=thickness)前処理(標準化/ノイズ除去)
ここから前処理に関する機能の概要とサンプルソースコードを記載していますが、画像の読み込みや表示に関する部分は省略しています。ご自身の環境で試される場合は、下記ソースコードを参考に画像の読み込みと表示を追加の上、実行して下さい。
# 画像の元のサイズを取得
import cv2
import numpy as np
#カラーで画像を読み込む
image = cv2.imread('o:/image.jpg')
# ~ここに画像処理のコードを記述する~
# 画像を表示
cv2.imshow('Image', image)
# キー入力待機
cv2.waitKey(0)
# ウィンドウを閉じる
cv2.destroyAllWindows()画像の正規化
画像のピクセル値を0から1の範囲にスケーリングします。

normalized_image = image.astype(float) / 255.0正規化された画像は、正規化に対応した表示方法(OpenCVのimshowメソッドなど)だと元画像と同じ結果が表示されますが、非対応のアプリ(WindowsのペイントやPhotoShopなど)だと真っ黒に表示されます。
画像の標準化
画像のピクセル値を平均0、標準偏差1になるようにスケーリングします。

standardized_image = (image.astype(float) - image.mean()) / image.std()標準化された画像は、Windowsのペイントだと真っ黒に映りますが、imshowメソッドだと画像として表示できます。ただし、見た目の色合いが随分変わります。
ノイズ除去(非局所的平均平滑化)
画像に含まれるノイズを除去します。画像全体の情報を使用してノイズを推定し、それに基づいてノイズ除去を行うため、局所的な情報だけを使用する従来の平滑化手法よりも高品質なノイズ除去が可能です。

h = 10 # フィルタリング強度。大きい値ほどフィルタリングが強くなる。
hForColorComponents = 10 # 色成分のフィルタリング強度。通常、hと同じ値を使用する。
templateWindowSize = 7 # 非局所的平均平滑化のテンプレートウィンドウサイズを指定する。
searchWindowSize = 21 # 非局所的平均平滑化の探索ウィンドウサイズを指定する。
# ノイズ除去を実行する
denoised_image = cv2.fastNlMeansDenoisingColored(image, None, h, hForColorComponents, templateWindowSize, searchWindowSize)
ノイズ除去(加重平均による平滑化手法=ガウシアンぼかし)
各ピクセルの値を周囲のピクセルの加重平均で置き換えることでノイズを除去します。計算速度は高速ですが、非局所的平均平滑化に比べて性能は低くなる場合があります。ちなみに、デジカメで高感度撮影した時に発生するノイズは、ガウシアンノイズとポアソンノイズの混合です。

# ガウシアンぼかしを行うためのパラメータを設定する
kernel_size = (5, 5) # カーネルサイズを指定する。大きい値ほどぼかしが強くなる。
sigmaX = 0 # X方向の標準偏差を指定する。0の場合、カーネルサイズから自動的に計算される。
# ガウシアンぼかしを実行する
blurred_image = cv2.GaussianBlur(image, kernel_size, sigmaX)| ガウシアンノイズ | 画像にランダムに加わる正規分布に従うノイズ |
| サルト・ペッパーノイズ | 画像の一部のピクセルが極端に明るくなる、又は暗くなるノイズ |
| ポアソンノイズ | 光子のランダム性により生じた明るさの変動で発生する点状のノイズ |
ノイズ除去(中央値による平滑化手法)
画像の各ピクセルに対して周囲のピクセル値をソートし、中央値を取ることでノイズを除去します。ノイズが極端に外れ値の場合でも、ノイズの影響を抑えることができます。

# 中央値ぼかしを行うためのカーネルサイズを指定する(奇数である必要があります)
kernel_size = 3 # 例として3x3のカーネルを使用します
# 中央値ぼかしを実行する
blurred_image = cv2.medianBlur(image, kernel_size)エッジに対しても比較的良好な結果が得られる場合がありますが、ガウシアンぼかしに比べるとエッジの滑らか化効果は強くなります。
グレイスケール化
グレースケール化は、データ量の削減、計算の効率化、色情報の排除、カラーノイズの低減に効果があります。

grayscale_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)カラー情報ではなく輝度情報を必要とするエッジ検出、物体検出、顔認識、テクスチャ情報や、SIFT(Scale-Invariant Feature Transform)やSURF(Speeded-Up Robust Features)などの特徴点抽出アルゴリズムなどで効力が発揮します。
ヒストグラム均等化
ヒストグラム均等化は、画像のコントラストを改善し、画像の輝度値をより広い範囲に分布させるための手法であり、視覚的な品質や特徴抽出の精度向上が期待できます。

#グレイスケール化
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#ヒストグラム均等化
equalized_image = cv2.equalizeHist(image)ヒストグラム均等化は、カラー画像に対しても行うことができますが、通常はRGBカラースペースではなく、グレースケール画像に対して適用します。
カラー画像の場合、RGBチャンネルごとにヒストグラム均等化を行うと色のバランスが崩れる可能性があるため、別のカラースペース(例:YUV、HSV)でチャンネルごとにヒストグラム均等化を行うことが一般的です。
画像処理
画像の拡大と縮小
元画像に対して、指定した倍率で拡大、縮小を行います。
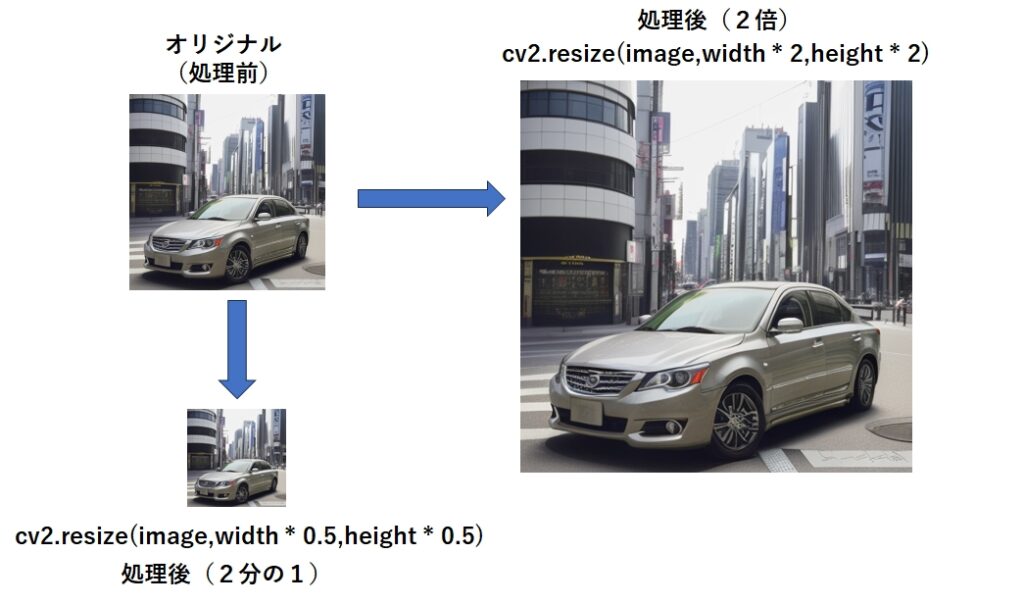
# 画像の元のサイズを取得
height, width = image.shape[:2]
# 拡大する場合
scale_factor = 2.0 # 拡大率を指定
image = cv2.resize(image, (int(width * scale_factor), int(height * scale_factor)))
# 縮小する場合
scale_factor = 0.5 # 縮小率を指定
image = cv2.resize(image, (int(width * scale_factor), int(height * scale_factor)))エッジ検出
画像のエッジ(輪郭)を検出します。物体検出やセグメンテーションの前処理として利用できます。
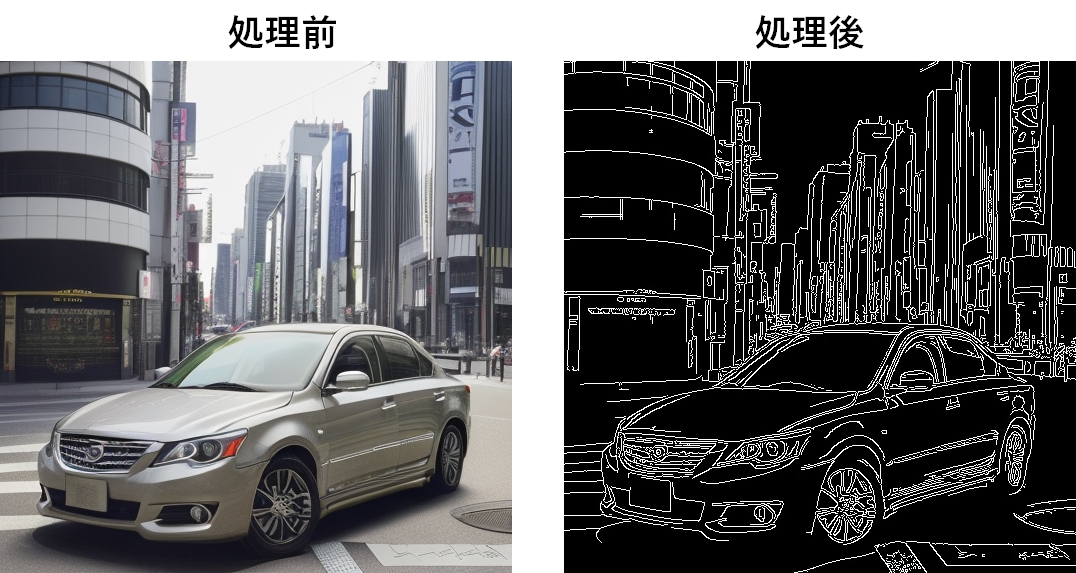
#グレイスケール化
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Cannyエッジ検出を行うためのパラメータを設定する
threshold1 = 100 # 閾値の下限。強度勾配がこの値より高いエッジが候補
threshold2 = 200 # 閾値の上限。強度勾配がこの値より高いエッジを実際のエッジとして確定
# Cannyエッジ検出を実行する
image= cv2.Canny(image, threshold1, threshold2)RGBの色情報の分離
RGB(赤、緑、青)画像から色情報を分離します。

blue_channel, green_channel, red_channel = cv2.split(image)R、G、B、に分解はされますが、色情報が欠落するため、そのままでは全チャンネルともグレースケールとして表示されます。
カラー画像のまま、表示したいチャンネル以外は値を0にしてしまうことで、そのチャンネルだけを持たせることが出来ます。
特定のチャンネルのデータを取り出す方法は、次の通りです。
#特定のチャンネルだけ取得する
blue_channel = image[:, :, 0] # Bチャンネルのデータを取得
green_channel = image[:, :, 1] # Gチャンネルのデータを取得
red_channel = image[:, :, 2] # Rチャンネルのデータを取得 特定のチャンネルを0にしてしまうには、 np.zeros_like() が利用できます。これは、引数に渡されたデータと同じサイズで、中身が0のデータを生成するものです。
最後に、cv2.merge() メソッドで3つのチャンネルを結合すれば、分離された色だけが残ったカラー画像が生成できます。
以上の内容を元に、指定した画像からR,G,Bのカラー画像を分離する関数を作ってみました。

def split_channel(image):
# Rチャンネルのみを抽出
red_channel = image[:, :, 2]
blue_channel = np.zeros_like(red_channel)
green_channel = np.zeros_like(red_channel)
red = cv2.merge([blue_channel, green_channel, red_channel])
# Gチャネルのみを抽出
green_channel = image[:, :, 1]
blue_channel = np.zeros_like(green_channel)
red_channel = np.zeros_like(green_channel)
green = cv2.merge([blue_channel, green_channel, red_channel])
# Bチャンネルのみを抽出
blue_channel = image[:, :, 0]
green_channel = np.zeros_like(blue_channel)
red_channel = np.zeros_like(blue_channel)
blue = cv2.merge([blue_channel, green_channel, red_channel])
return blue,green,red2値化(閾値を使う場合)
指定した閾値で2値化を行います。。threshold() の戻り値は2つあり、1つ目は指定した閾値が返され、2つ目に2値化の画像か返されます。

#グレイスケール化
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#2値化(閾値を自分で決める)
threshold_value = 128 # 2値化の閾値(0から255の値を指定)
max_value = 255 # 閾値を超えた場合の値(通常は255で白を指定)
threshold_method = cv2.THRESH_BINARY # 2値化の方法(この場合は閾値を超えたら白にする)
_, image = cv2.threshold(image, threshold_value, max_value, threshold_method)通常、1つ目の戻り値は使わないので、 _ で破棄しています。
2値化(閾値を自動で求める)
閾値は輝度の分布から自動で決定(オーバーサムプリング)することも出来ます。

#グレイスケール化
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#2値化(輝度の分布から閾値を自動で決める)
_, image = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)2値化(適応的閾値処理)
画像の局所領域ごとに異なる閾値を適用して2値化する手法です。通常の固定閾値処理では、画像全体に同じ閾値を適用しますが、適応的閾値処理では、画像の明るさやコントラストの違いに対応して、各ピクセルの周囲の領域に基づいて動的に閾値を設定します。

#グレイスケール化
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 適応的閾値処理を行う
maxValue = 255 # 閾値を超えた場合に割り当てる値(通常は255)。
block_size = 11 # 近傍領域のサイズ (奇数である必要があります)
C = 2 # 平均値または重み付け平均値から引く定数
image = cv2.adaptiveThreshold(image, maxValue, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, block_size, C)これにより、異なる部分の適切な閾値が得られ、光の変動が大きい画像や影のある画像などに対しても効果的に2値化が行えます。
回転
画像を回転します。

# 回転の中心座標と回転角度を指定
center = (image.shape[1] // 2, image.shape[0] // 2)
angle = 30 # 回転角度(度数法)
# 回転行列を取得
rotation_matrix = cv2.getRotationMatrix2D(center, angle, scale=1.0)
# 画像を回転する
image = cv2.warpAffine(image, rotation_matrix, (image.shape[1], image.shape[0]))画像平行移動
画像を平行移動します。

# 平行移動の変換行列を作成する
tx = 50 # X軸方向の平行移動量
ty = 30 # Y軸方向の平行移動量
translation_matrix = np.array([[1, 0, tx], [0, 1, ty]], dtype=np.float32)
# 画像の高さと幅を取得
height, width = image.shape[:2] # height: 画像の高さ, width: 画像の幅
# 画像を平行移動する
image = cv2.warpAffine(image, translation_matrix, (width, height))反転
画像のピクセル値を反転させます。カラー画像でも反転は出来ますが、通常はグレイスケールもしくは2値化したものを反転して使うことが多いです。

#グレイスケール化
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#画像を反転する
image = cv2.bitwise_not(image)明度と鮮明度
コントラストや画像の鮮明度を調整します。

alpha = 1.5 # 明度の倍率(1.0より大きいと明るくなり、1.0より小さいと暗くなります)
beta = 30 # 鮮明度の調整(0より大きいと鮮明になり、0より小さいとぼやけます)
image = cv2.convertScaleAbs(image, alpha=alpha, beta=beta)色空間変換
画像の色空間を変換します。

# BGRからHSVへの変換
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)| 変換元の色空間 | 変換先の色空間 | 変換コード |
|---|---|---|
| BGR (青緑赤) | RGB (赤緑青) | cv2.COLOR_BGR2RGB |
| BGR (青緑赤) | LAB (色相、緑赤成分、青黄成分) | cv2.COLOR_BGR2LAB |
| BGR (青緑赤) | YUV (輝度、色差) | cv2.COLOR_BGR2YUV |
| BGR (青緑赤) | HLS (色相、彩度、明度) | cv2.COLOR_BGR2HLS |
| BGR (青緑赤) | XYZ (CIE 1931 XYZ) | cv2.COLOR_BGR2XYZ |
| BGR (青緑赤) | YCrCb (輝度、赤色差、青色差) | cv2.COLOR_BGR2YCrCb |
| グレースケール | BGR (青緑赤) | cv2.COLOR_GRAY2BGR |
| HSV (色相、彩度、明度) | BGR (青緑赤) | cv2.COLOR_HSV2BGR |
| LAB (色相、緑赤成分、青黄成分) | BGR (青緑赤) | cv2.COLOR_LAB2BGR |
| YUV (輝度、色差) | BGR (青緑赤) | cv2.COLOR_YUV2BGR |
| HLS (色相、彩度、明度) | BGR (青緑赤) | cv2.COLOR_HLS2BGR |
| XYZ (CIE 1931 XYZ) | BGR (青緑赤) | cv2.COLOR_XYZ2BGR |
| YCrCb (輝度、赤色差、青色差) | BGR (青緑赤) | cv2.COLOR_YCrCb2BGR |
フーリエ変換(グレイスケール)
フーリエ変換は、画像を空間領域から周波数領域に変換する方法です。画像の空間領域では、ピクセルの輝度値が座標によって表現されていますが、フーリエ変換を適用することで、画像内の周波数成分を表現することができます。周波数領域では、画像の高周波成分がエッジや細部などの細かい特徴を表し、低周波成分が画像全体の大まかな構造や背景などを表します。
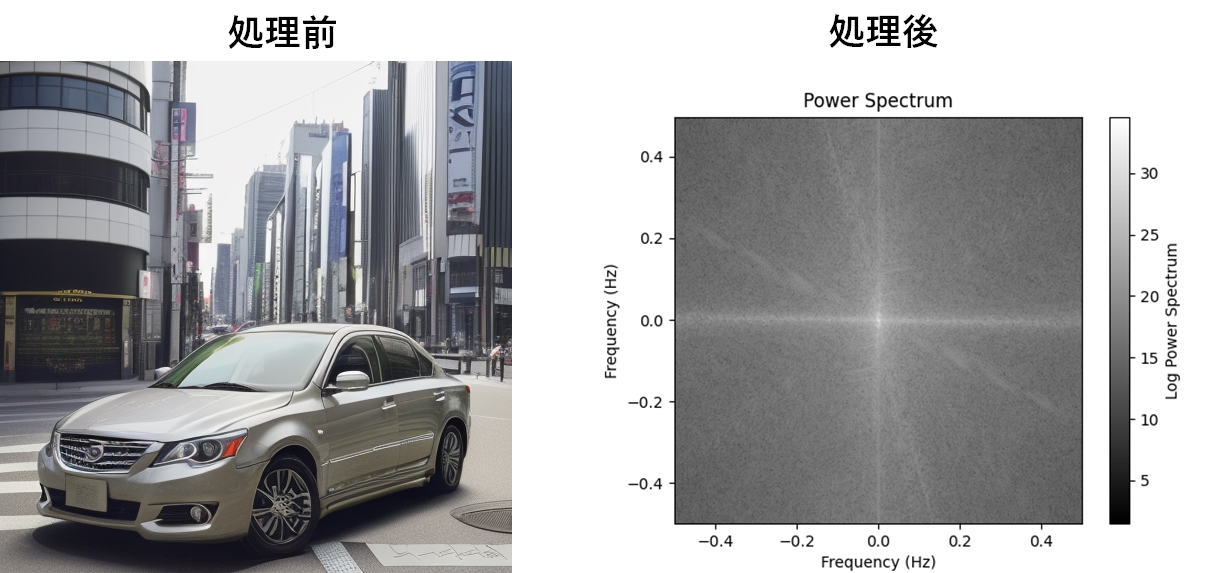
# 2次元離散フーリエ変換を行う
f_transform = np.fft.fft2(image)
# 零周波数成分を中心に持ってくる
f_transform_shifted = np.fft.fftshift(f_transform)
# パワースペクトル(周波数成分の強度)を取得する
power_spectrum = np.abs(f_transform_shifted)**2
# フーリエ逆変換して元の空間領域に戻す
f_transform_inverse_shifted = np.fft.ifftshift(f_transform_shifted)
image_reconstructed = np.fft.ifft2(f_transform_inverse_shifted).realimport cv2
import numpy as np
import matplotlib.pyplot as plt
# 画像をグレイスケールとして読み込む
image = cv2.imread('path/to/your/image.jpg', cv2.IMREAD_GRAYSCALE)
# 2次元離散フーリエ変換を行う
f_transform = np.fft.fft2(image)
# 零周波数成分を中心に持ってくる
f_transform_shifted = np.fft.fftshift(f_transform)
# パワースペクトル(周波数成分の強度)を取得する
power_spectrum = np.abs(f_transform_shifted)**2
#---------------------------------------------------------
# 以下はパワースペクトルを可視化するソースコード
#---------------------------------------------------------
height, width = power_spectrum.shape
frequencies_x = np.fft.fftfreq(width, 1)
frequencies_y = np.fft.fftfreq(height, 1)
mesh_x, mesh_y = np.meshgrid(frequencies_x, frequencies_y)
plt.figure()
plt.imshow(np.log(1 + power_spectrum), cmap='gray', extent=(frequencies_x.min(), frequencies_x.max(), frequencies_y.min(), frequencies_y.max()))
plt.xlabel('Frequency (Hz)')
plt.ylabel('Frequency (Hz)')
plt.colorbar(label='Log Power Spectrum')
plt.title('Power Spectrum')
plt.show()フーリエ変換は、画像処理の前処理として以下のような効果があります:
- ノイズ除去: 周波数領域でのフィルタリングを行うことで、ノイズを除去することができます。
- エッジ検出: 高周波成分を強調することで、エッジを検出することができます。
- テクスチャ解析: テクスチャ情報を抽出し、画像の細部やパターンを解析することができます。
- 画像の分析と特徴抽出: 周波数情報を分析することで、画像の特徴を理解し、特定のパターンや構造を抽出します。
- 画像の圧縮: 周波数成分を利用して画像の情報を圧縮することができます。
フーリエ変換(カラー画像)
カラー画像の場合、チャンネルごとにパワースペクトルを求める必要があります。チャンネルを渡すとパワースペクトルを計算する部分を関数化したサンプルを作ったので、紹介しておきます。
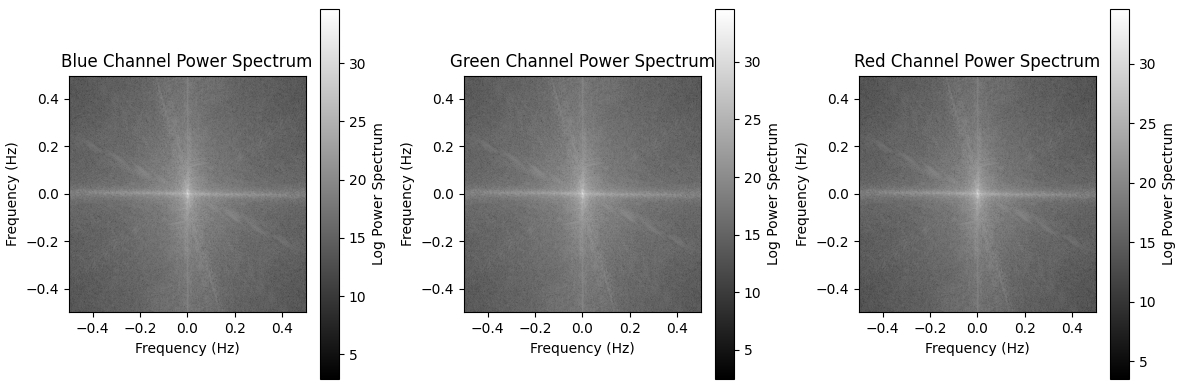
import cv2
import numpy as np
import matplotlib.pyplot as plt
def calculate_power_spectrum(channel):
# 2次元離散フーリエ変換を行う
f_transform = np.fft.fft2(channel)
# 零周波数成分を中心に持ってくる
f_transform_shifted = np.fft.fftshift(f_transform)
# パワースペクトル(周波数成分の強度)を取得する
power_spectrum = np.abs(f_transform_shifted)**2
return power_spectrum
# カラーで画像を読み込む
image = cv2.imread('O:/00016-2302964825.png')
# RGBチャンネルに分解する
blue_channel, green_channel, red_channel = cv2.split(image)
# R、G、Bのパワースペクトルを計算する
power_spectrum_blue = calculate_power_spectrum(blue_channel)
power_spectrum_green = calculate_power_spectrum(green_channel)
power_spectrum_red = calculate_power_spectrum(red_channel)
#---------------------------------------------------------
# 以下はパワースペクトルを可視化するソースコード
#---------------------------------------------------------
# パワースペクトルをグラフ化する
height, width = power_spectrum_blue.shape
frequencies_x = np.fft.fftfreq(width, 1)
frequencies_y = np.fft.fftfreq(height, 1)
mesh_x, mesh_y = np.meshgrid(frequencies_x, frequencies_y)
plt.figure(figsize=(12, 4))
plt.subplot(131)
plt.imshow(np.log(1 + power_spectrum_blue), cmap='gray', extent=(frequencies_x.min(), frequencies_x.max(), frequencies_y.min(), frequencies_y.max()))
plt.xlabel('Frequency (Hz)')
plt.ylabel('Frequency (Hz)')
plt.colorbar(label='Log Power Spectrum')
plt.title('Blue Channel Power Spectrum')
plt.subplot(132)
plt.imshow(np.log(1 + power_spectrum_green), cmap='gray', extent=(frequencies_x.min(), frequencies_x.max(), frequencies_y.min(), frequencies_y.max()))
plt.xlabel('Frequency (Hz)')
plt.ylabel('Frequency (Hz)')
plt.colorbar(label='Log Power Spectrum')
plt.title('Green Channel Power Spectrum')
plt.subplot(133)
plt.imshow(np.log(1 + power_spectrum_red), cmap='gray', extent=(frequencies_x.min(), frequencies_x.max(), frequencies_y.min(), frequencies_y.max()))
plt.xlabel('Frequency (Hz)')
plt.ylabel('Frequency (Hz)')
plt.colorbar(label='Log Power Spectrum')
plt.title('Red Channel Power Spectrum')
plt.tight_layout()
plt.show()コーナー検出
コーナー検出(Corner Detection)は、画像内のコーナー(角の部分)を自動的に検出するための画像処理手法です。コーナーは、周囲との色や輝度の変化が大きいポイントであり、画像内の重要な特徴点の一つとして扱われます。コーナー検出は、コンピュータビジョンや画像処理のさまざまなタスクに応用されます。

# グレースケールに変換
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Harrisコーナー検出のためのパラメータ
block_size = 2 # コーナー検出の際の近傍領域のサイズ
ksize = 3 # Sobelオペレータのカーネルサイズ(側微分のカーネルサイズ)
k = 0.04 # Harrisコーナー検出の重み係数
# Harrisコーナー検出を適用する
corner_response = cv2.cornerHarris(image, blockSize=block_size, ksize=ksize, k=k)
# コーナーを強調するために色を変更する
image_with_corners = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
threshold = 0.01 * corner_response.max() # コーナーと判定する閾値
image_with_corners[corner_response > threshold] = [0, 0, 255]少し分かり難いですが、処理後の画像には判定箇所に赤い点がプロットされています。
特徴抽出
HOG特徴抽出
コンピュータビジョンや画像処理において、物体検出や特徴抽出に利用される手法の一つです。HOG特徴抽出は、画像内の局所領域における勾配方向と強度をヒストグラムとして表現し、これを特徴ベクトルとして用いることで、物体の形状や輪郭を抽出する効果的な手法です。
# HOG特徴抽出を行う
hog = cv2.HOGDescriptor()
features = hog.compute(image)
# 特徴ベクトルを表示する
print("HOG Feature Vector:")
print(features)HOG特徴抽出の手順は以下の通りです:
- グレースケール画像に変換する: HOG特徴抽出は、グレースケール画像を入力として処理します。カラー画像の場合は、事前にグレースケールに変換する必要があります。
- 画像を小領域(セル)に分割する: 画像を小領域に分割し、それぞれの領域で勾配方向と強度を計算します。
- 勾配方向と強度のヒストグラムを作成する: 各セル内のピクセルに対して、勾配方向と強度を計算し、これらの値を複数の方向のビンに分割してヒストグラムを作成します。
- ブロック正規化: 作成したヒストグラムをブロックとして結合し、ブロック内の特徴ベクトルを正規化します。
HOG特徴抽出は主に物体検出や人物検出などのタスクに利用されます。SVM(Support Vector Machine)などの機械学習アルゴリズムと組み合わせることで、高い精度で物体を検出することが可能です。
SIFT特徴抽出
SIFT(Scale-Invariant Feature Transform)は、コンピュータビジョンや画像処理において、スケール不変性を持つ特徴点を抽出するための手法です。SIFT特徴抽出は、画像内の局所領域における特徴点を検出し、それらの特徴点の位置、スケール、方向などを記述します。

# SIFT特徴抽出器を作成する
sift = cv2.SIFT_create()
# 特徴点の検出だけを行い、特徴記述子の計算は行わない
keypoints = sift.detectAndCompute(image, None)
# 特徴点を描画する(keypoints 特徴点と特徴記述子がタプルで返される)
output_image = cv2.drawKeypoints(image, keypoints[0], None)SIFT特徴抽出の主な手順は以下の通りです:
- スケール空間極大値検出: 画像の異なるスケールにおける特徴点を検出するため、スケール空間において特徴点の極大値を見つけます。
- キーポイントの位置とスケールの精緻化: 特徴点の位置とスケールをさらに精緻化し、重複する特徴点を削除します。
- 特徴点の向きの決定: 各特徴点における特徴の向きを計算します。これにより、特徴点の回転不変性を得ることができます。
- 特徴記述子の計算: 各特徴点周辺の局所領域における勾配方向をヒストグラムとして表現し、これを特徴ベクトルとして記述します。
SIFT特徴抽出は、特にスケール変化や回転、一部の視点変化に対してロバスト(環境の変化を受けにくい)であるため、物体認識や画像マッチングなどのタスクに非常に有用です。
データ拡張のサンプル
学習データを増やす手法をデータ拡張(Data Augmentation)と呼んでいます。
データ拡張は、入力データに画像処理を施すことで学習データのバリエーションを増やし、過学習の防止や汎化性能の向上を図りたい場合に行われます。
以下は、PythonとOpenCVを使用して、データ拡張を行う簡単なサンプルコードです。
画像の明るさ、ノイズの混入、画像の回転、上下左右の水平移動をランダムに実行し、データ拡張を行っています。
import os
import cv2
import numpy as np
# データ拡張関数を定義
def data_augmentation(image, num_augmented_images):
augmented_images = []
height, width = image.shape[:2]
for i in range(num_augmented_images):
# ランダムに明るさを増減する
brightness_factor = np.random.uniform(0.7, 1.3)
brightened_image = np.clip(image * brightness_factor, 0, 255).astype(np.uint8)
# 画像にノイズを入れる
noise = np.random.normal(loc=0, scale=30, size=image.shape)
noisy_image = np.clip(image + noise, 0, 255).astype(np.uint8)
# 画像を回転させる
angle = np.random.uniform(-30, 30)
rotation_matrix = cv2.getRotationMatrix2D((width / 2, height / 2), angle, 1)
rotated_image = cv2.warpAffine(image, rotation_matrix, (width, height))
# 画像を上下左右に移動する
x_shift = np.random.randint(-50, 50)
y_shift = np.random.randint(-50, 50)
translation_matrix = np.float32([[1, 0, x_shift], [0, 1, y_shift]])
translated_image = cv2.warpAffine(image, translation_matrix, (width, height))
# 画像を拡大する
scale_factor = np.random.uniform(1.2, 1.5) # 拡大率を指定
enlarged_image = cv2.resize(image, (int(width * scale_factor), int(height * scale_factor)))
# 画像を縮小する
scale_factor = np.random.uniform(0.5, 0.8) # 縮小率を指定
shrunken_image = cv2.resize(image, (int(width * scale_factor), int(height * scale_factor)))
augmented_images.extend([brightened_image, noisy_image, rotated_image, translated_image,
enlarged_image, shrunken_image])
return augmented_images
# 画像を読み込む
image_path = 'path/to/your/image.jpg'
image = cv2.imread(image_path)
# データ拡張を行う
output_folder = 'path/to/output/folder' # 出力フォルダを指定
num_augmented_images = 5 # 生成する画像の枚数
augmented_images = data_augmentation(image, num_augmented_images)
# 画像を連番で出力する
os.makedirs(output_folder, exist_ok=True)
for i, augmented_image in enumerate(augmented_images):
output_path = os.path.join(output_folder, f'augmented_image_{i + 1}.jpg')
cv2.imwrite(output_path, augmented_image)
print(f'{num_augmented_images}枚の画像を {output_folder} に保存しました。')
まとめ
今回は OpenCVのインストール方法、画像の読み込みと保存、ディープラーニングの前処理で使えそうな機能とサンプルプログラムを一通り紹介しました。
画像認識ではディープラーニングが主流になっていますが、OpenCVで前処理を行うことで、飛躍的に精度を高めることが可能です。
今回紹介した機能以外にも、まだまだ沢山の機能があります。本記事でOpenCVに興味を持たれた方、本記事に掲載されていない機能を使いたい方は、是非公式サイトのチュートリアルをご参照ください。
きっと色々な発見があると思います。








コメント