この記事では、Pythonを使ったファイル操作の基礎から、メモリに収まらない巨大ファイルの処理方法までを解説します。具体的には、以下のトピックをカバーします:
- テキストファイルの読み書き
- バイナリファイルの読み書き
- ランダムアクセス
これらについて、他の記事ではあまり触れられていない内容を含め、サンプルコードを使って詳しく紹介しています。
さらに、記事の最後には実践的なサンプルをいくつかご用意しました。これらのサンプルは関数化されており、コピーしてすぐに使えるようになっています。ファイル操作が必要になった際には、ぜひこの記事をご活用ください。
尚、本記事はファイル読み書きに限定しているため、ファイルやフォルダに関する操作については「【図で解説】Pythonファイル/フォルダ操作術。コピペで使えるサンプルコード付き。」で詳しく解説しています。
ファイルのオープンとクローズ
書籍を読むときやノートに書き込むときは、表紙を開き、用が済んだら表紙を閉じるという手順を踏みます。ファイル操作も同様に、読み書きする場合にはファイルを開き(オープン)、処理が終わったら閉じる(クローズ)必要があります。
プログラムの中でファイルをオープンしたままプログラムを終了すると、そのファイルは開かれた状態となり、OSを再起動しないと中を参照することができなくなります。
ファイルを開く(オープン)、閉じる(クローズ)

ファイルを開く(オープンする)には、open 関数を、閉じる(クローズする)には close 関数を使います。
どちらもPythonの標準関数であるため、インストールや import は必要ありません。
ファイルのクローズを明示的に書く方法は一般的ですが、withを使うと処理終了後に自動でcloseが行なわれることや、ファイルをオープンしている範囲が分かりやすくなることから、右の書き方もよく使われています。
明示的にcloseを呼び出す書き方
f = open("p:/hoge.txt")
print(f.read())
f.close()withを使って自動的にcloseを呼び出させる書き方
with open("p:/hoge.txt") as f:
print(f.read())ファイルオープン(open)関数の全体図
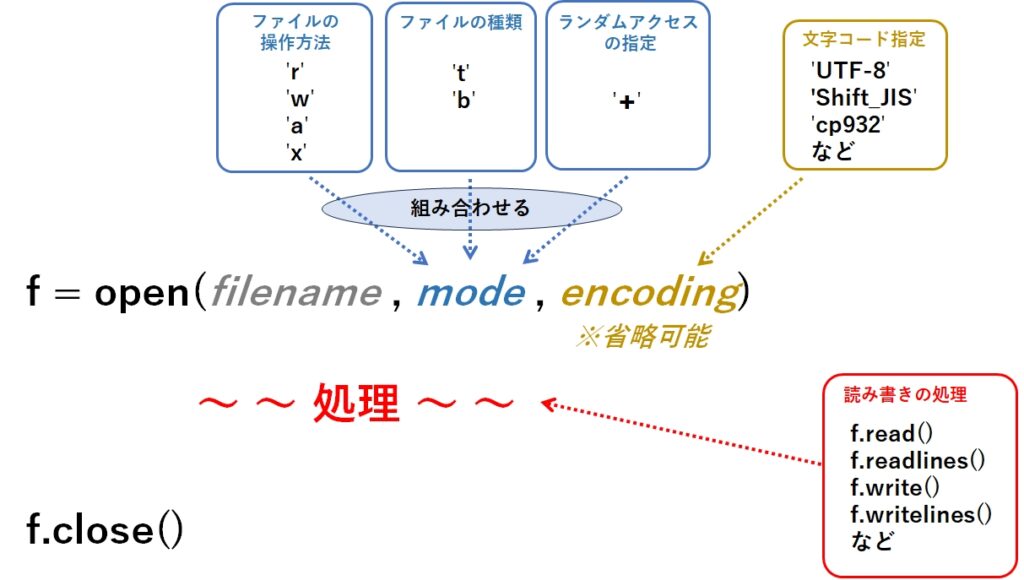
ファイルをオープンする際、操作方法(読込、書込、追加)、オープンするファイルの種類(テキストファイル、バイナリファイル)、ランダムアクセス(ファイルの場所を指定して読み書き)を行います。
また、テキストファイルの場合は文字コード(Shift-JIS、UTF-8など)も必要に応じて指定します。
encoding 、mode については省略可能です。ただし、modeを省略した場合は "r"が指定されたことになりますが、文字コードについてはOSやPythonのインストール方法によって異なりますので、省略しないことが推奨されています。
ファイルパスの指定方法
オープンするファイルを指定する際、ディレクトリやファイルの区切りとしてバックスラッシュ(¥)が使われます。
Pythonの場合は文字列に¥を記載すると続く1文字と組み合わされて異なる意味に解釈されるため、¥¥という具合に2個連ねる必要があります。
open("p:\\mydir\\myfile.txt")Pythonでは 区切り文字にスラッシュ(/)が使えますので、バックスラッシュを2個連ねるのは面倒という方は次のように記述すると少しだけ楽になります。
open("p:/mydir/myfile.txt")テキストファイルの読み込み、書き込み
テキストファイルの読み込み(read,readline,readlines)
テキストファイルを読み込む場合の基本形は次の通りです。第2引数に "r" を指定していますが、省略可能です。
with open("p:/hoge.txt","r") as f:
print(f.read())ファイルを読み込むメソッドには次のもの用意されています。
| read() read(size) | ファイルを全て読み込み、1つの文字列として返します。 sizeを指定した場合、先頭から size で指定した文字数分を読み込みます。 |
|---|---|
| readline() readline(size) | ファイルを1行だけ読み込みます。 sizeを指定した場合、先頭から size で指定した文字数分を読み込みます。 "aaaaa\n" 戻り値の末尾に改行キーが含まれるので、必要に応じて strip() で改行を削除します。 |
| readlines() | ファイルを全て読み込み、全ての行をリスト形式で返します。 ["aaaa\n" , "bbbb\n" , "cccc\n"] 各要素の末尾に改行キーが含まれるので、必要に応じて strip() で改行を削除します。 |
read()や readlines() はファイルの中身を全てメモリに読み込むため、比較的小さなファイルを処理する場合に使用します。
一方、メモリに収まらないサイズのファイルについては、readline()で1行ずつ読み込んで処理します。
次のサンプルは、ファイルを1行づつ読み込んでprint で出力するサンプルです。open() の戻り値であるファイルオブジェクトを for で使うと行が取得でき、左の様にシンプルに記述できます。右は readline()を使った場合の例です。
with open("p:/hoge.txt") as f:
for line in f:
print(line.strip())with open(file_path, 'r') as file:
while True:
line = file.readline()
if not line:
break
print(line.strip()) テキストファイルの書き込み(write,writelines)
テキストファイルを書き込む場合の基本形は次の通りです。第2引数に上書きモード、追加モード、排他モードのいずれかを指定します。
with open("p:/hoge.txt","w") as f:
f.write("abcdefg")"w","a","x" はいづれもファイルが存在しなければ新規作成するところは同じですが、存在した場合の動作が異なります。
| "w" | 上書モード | ファイルが存在しなければ新規作成、存在すれば既存ファイルを上書き(削除して新規作成)します。 |
|---|---|---|
| "a" | 追加モード | ファイルが存在しなければ新規作成、存在すればファイル末尾に追加します。 |
| "x" | 排他作成モード | ファイルが存在しなければ新規作成、存在すれば FileExistsError というエラーを発生させます。 |
ファイルを書き込むメソッドには次の2種類が用意されています。
| write(data) | 引数に指定した文字列を全てファイルに書き込みます。 |
|---|---|
| writelines(datas) | 引数にリスト形式のデータを渡すと、その中身を全てファイルに書き込みます。 ["aaaa","bbbb","cccc"] ⇒ "aaaabbbbcccc" 改行コードが自動で入らないため、各要素の末尾に改行コードを入れる必要があります。 [x+"\n" for x in ["aaaa","bbbb","cccc"] ⇒ "aaaa\nbbbb\ncccc" |
リスト形式のデータを改行付きで書き込む場合、 writelines だと各要素の末尾に改行コードを付加しなければなりません(左側)。それなら、いっそ join を使って1つに連結してから write で書き出すという方法(右側)の方がシンプルです。
lines = ["aaaa","bbbb","ccccc"]
with open("p:/hoge.txt","w") as f:
f.writelines([x +"\n" for x in lines])lines = ["aaaa","bbbb","ccccc"]
with open("p:/hoge.txt","w") as f:
f.write("\n".join(lines))write、writelines は、書き込むデータは全てメモリ上に用意しておく必要があります。これは、例えばメモリ上で大量データを生成し、それをファイルに書き込むような場合は使えません。
この場合は、writeメソッドとループを組み合わせるなどして、データを生成しながら随時ファイルに書き込む方法を行います。
下記は、連番+ "data" + 連番というフォーマットのデータを1万件生成するため、ループ処理の中で write を使って書き込む例です。末尾に改行コードを付加することで、行として書き込んでいます。
with open("p:/hoge2.txt","w") as f:
for i in range(10000):
f.write(f"{i} data{i}\n")writeの代わりに print 関数の file 引数にファイルオブジェクトを渡す方法でも、ファイルに書き込むことが可能です。
with open("p:/hoge2.txt","w") as f:
for i in range(10000):
print(f"{i} data{i}",file=f)print は1行出力するごとに、自動で改行を付加してくれるので、自分で改行コードを追加する必要はありません。
バイナリファイルの読み込み、書き込み
バイナリファイルの読み込み(read,readline,readlines)
バイナリファイルを読み込む場合の基本形は次の通りです。第2引数に "rb" を指定します。
with open("p:/hoge.txt","rb") as f:
print(f.read())バイナリファイルにおいても、テキストファイルと同じメソッドが使えますが、size は文字数ではなくバイト数の指定になります。
| read() read(size) | ファイルを全て読み込み、1つの文字列として返します。 sizeを指定した場合、先頭から size で指定したバイト数分を読み込みます。 |
|---|---|
| readline() readline(size) | ファイルを1行だけ読み込みます。 sizeを指定した場合、先頭から size で指定したバイト数分を読み込みます。 "[b'aaaa\r\n', b'\xe3\x81\x8\r\n]" |
| readlines() | ファイルを全て読み込み、全ての行をリスト形式で返します。 ["aaaa\r\n" , "bbbb\r\n" , "cccc\r\n"] |
注意点として、readline や readlines は改行コード単位でデータを取り出してくれますが、文字としてではなくバイト列として返されます。
# テキストファイルとしてオープン (r)
with open("p:/hoge.txt","r") as f:
print(f.readlines())['aaaa\n', 'ああああ\n', 'cccc\n']
# バイナリファイルとしてオープン (rb)
with open("p:/hoge.txt","rb") as f:
print(f.readlines())[b'aaaa\r\n', b'\xe3\x81\x82\xe3\x81\x82\xe3\x81\x82\xe3\x81\x82\r\n', b'cccc\r\n']
そもそもバイナリファイルは改行コード(\n) を改行として取り扱っていないため、readlinesで読み込んでも意図した位置で改行されません。従ってバイナリファイルで readlines を使うことはほぼ無いと言えます。
バイナリファイルの書き込み(write,writelines)
バイナリファイルを書き込む場合の基本形は次の通りです。テキストファイルと同様に、第2引数に上書きモード、追加モード、排他モードのいずれかを指定しますが、バイナリであることを現す "b" を末尾に付ける必要があります。
具体的には、上書きモードは "wb"、追加モードは "ab"、排他作成モードは "xb" を指定します。
with open("p:/hoge.txt","wb") as f:
f.write("abcdefg")ファイルを書き込むメソッドは次の2種類が用意されています。
| write(data) | 引数に指定した文字列を全てファイルに書き込みます。 |
|---|---|
| writelines(datas) | 引数にリスト形式のデータを渡すと、その中身を全てファイルに書き込みます。 ["aaa","bbbb","cccc"] ⇒ "aaaabbbbcccc" |
一般的には、画像や音声などのバイナリファイルを読み込み、何らかの処理を行った結果をバイナリファイルとして出力することが大半です。通常この様な用途では write を使うことになります。
writelines の使用ついては、バイナリデータがリスト形式でメモリ上に格納されている場合のみという、かなりレアなケースになります。
ランダムアクセスを使った読み込み、書き込み
ランダムアクセスにおけるアクセス位置の指定
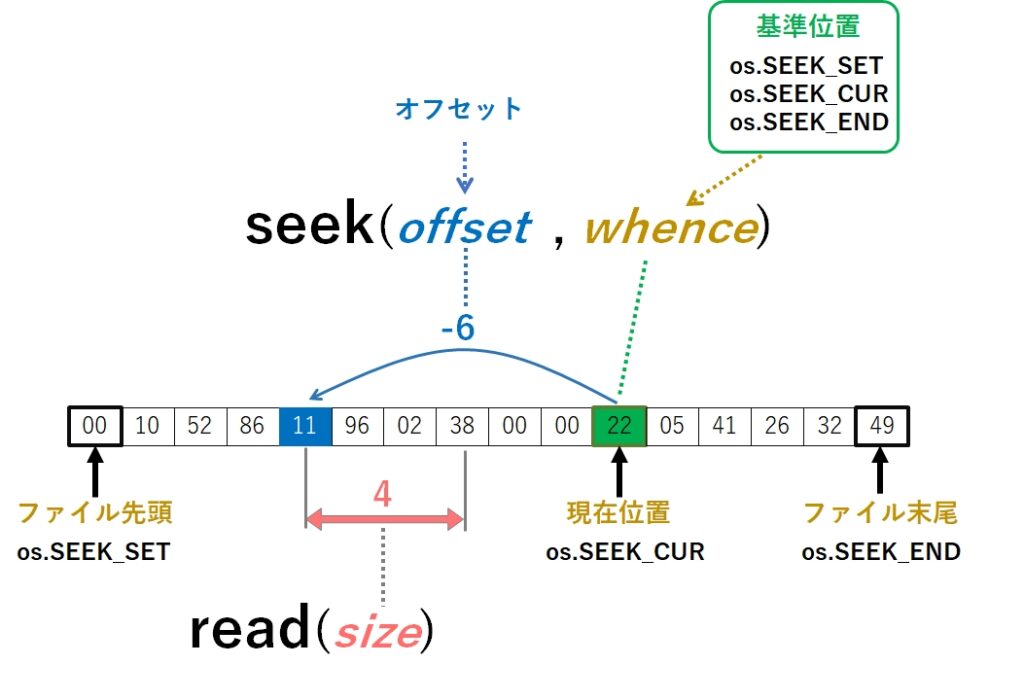
ランダムアクセスにおいて、データを読み書きする位置を指定する方法は seek メソッドを使います。
seek の第2引数(whence)に基準となる場所を起点に、第1引数(offset)で指定した値が加算され、最終的なアクセス位置が決まります。また、seek を実行した時点で、その位置がカレント位置となります。
尚、whence は省略可能で、省略した場合は os.SEEK_SET が指定されたことになります。
| os.SEEK_SET | ファイルの先頭を基準にする。 offsetは必ず正の値であること(例:150)。 |
|---|---|
| os.SEEK_CUR | 現在のカレント位置を基準にする。 offset は正と負のどちらも指定可能。 |
| os.SEEK_END | ファイルの末尾を基準にする。 offsetは必ず負の値であること(例:-150)。 |
アクセス位置に関連するメソッドは次の3種類があります。
| seek(offset,whence) | アクセス位置(カレント位置)を設定する。 whence で指定した場所を起点に、offsetで指定した値を加算した位置がアクセス位置となる。 |
|---|---|
| tell() | 現在のアクセス位置(カレント位置)を取得する。 |
| seekable() | ファイルがランダムアクセス可能かを確認する。可能ならTrueが返される。 標準入出力やパイプ、ソケットからのストリーム、一部のファイルシステムの場合はFalseとなる。 |
カレント位置は seek だけでなく、read による読み込みや write による書き込みにおいてもカレント位置が移動します。読み込んだ位置に上書きしたい場合は、もう一度 seek により位置を指定し直す必要があります。
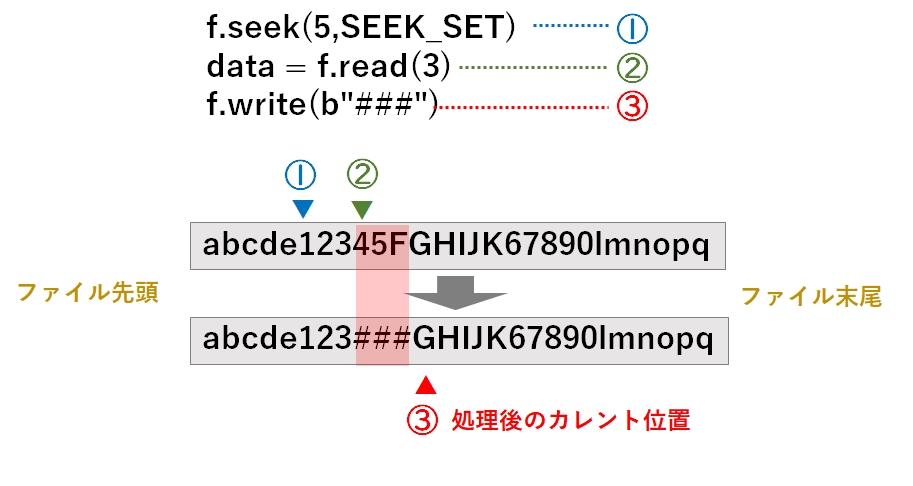
例えば、ファイルの先頭から5バイト目の位置から3バイト取得し、再びその位置(先頭から5バイト目)に '###' を書き込む場合は、次のように記述します。
import os
with open("p:/hoge.txt","rb+") as f:
f.seek(5,os.SEEK_SET)
data = f.read(3)
f.seek(5,os.SEEK_SET)
f.write(bytes(b"###"))テキストファイルをランダムアクセスで開く
ランダムアクセスとしてテキストファイルを開くには、第2引数の "r","w","a","x" に続けてランダムアクセスを現す "+" を付けます。
import os
with open("p:/hoge.txt","r+") as f:
f.seek(15,os.SEEK_SET)
print(f.read(2))
f.write("QQQ")ただし、テキストファイルをランダムアクセスする場合、任意の位置からデータを読み込むことは可能ですが、書き込む場合は常にファイル末尾に追加され、os.SEEK_SET 以外は使えないという制約があるため、通常はほとんど使うことは有りません。
| "r+" | 読み書きモード | 既存のファイルに対して読み書きモードで開きます。 seek により指定した位置から readで指定したサイズ分読み込むことが出来ますが、writeによる書き込みは常にファイル末尾に追加されます。 ファイルが存在しない場合は FileNotFoundError になります。 |
|---|---|---|
| "w+" | 上書モード | 既存ファイルを上書き(削除して新規作成)して、seek で指定し位置まで空白を出力し、その後にデータを書き込みます。 |
| "a+" | 追加モード | seek で指定した位置は無視され、常にファイル末尾に追加します。 ファイルが存在しなければ新規作成します。 |
| "x+" | 排他作成モード | ファイルが存在しなければ "w+"と同じ動作を行います。 ファイルが存在すれば FileExistsError というエラーを発生させます。 |
バイナリファイルをランダムアクセスで開く
ランダムアクセスとしてバイナリファイルを開くには、第2引数 に "rb+" を指定します。この指定だけで読み書きができるようになります。
書き込みたいからと言って "wb+","ab+","xb+" を指定するとエラーにはなりませんが、既存のファイルが壊れてしまう可能性が高いのでご注意ください。
import os
with open("p:/hoge.txt","rb+") as f:
f.seek(25,os.SEEK_SET)
data = f.read(3)
f.seek(-3,os.SEEK_CUR)
f.write(data)バイナリファイルにおいても、テキストファイルと同じメソッドが使えますが、size を指定すると文字数ではなくバイト数の指定になります。
| "rb+" | 読み書きモード | 既存のファイルに対して読み書きモードで開きます。 seek により指定した位置から readで指定したサイズ分読み込んだり、指定位置にwrite で書き込むことが可能です。 ファイルが存在しない場合は FileNotFoundError になります。 |
|---|---|---|
| "wb+" | 上書モード | 既存ファイルを上書き(削除して新規作成)して、write で指定した値を書き込みます。 既存ファイルの一部を更新するために "wb+" を使うと、既存ファイルが壊されますのでご注意ください。 |
| "ab+" | 追加モード | seek で指定した位置は無視され、常にファイル末尾に追加します。 "wb+"のようにファイルが壊れることはありませんが、指定位置のデータを更新することが出来ません。 |
| "xb+" | 排他作成モード | ファイルが存在しなければ "wb+"と同じ動作を行います。 ファイルが存在すれば FileExistsError というエラーを発生させます。 |
巨大なファイルの扱い
巨大なファイルを取り扱う場合、全ての内容をメモリに読み込むことが出来ません。
「メモリが許す範囲のデータサイズだけ読み込んで処理し、結果をファイルに書き出す」という処理をループで繰り返しながら、ファイル全体を処理することになります。
この章では、下記の4つのケースについてテンプレートとなるプログラムを紹介しておきます。
- 1つのファイルを加工して別のファイルとして出力する
- 1つのファイルを指定行数ごとに分割する
- 複数のファイルを1つのファイルに結合する
- 通常のテキストエディタでは開けない巨大なファイルの一部を表示する。
1つのファイルを加工して別のファイルとして出力する
input_fileで指定されたファイルの中身を func 関数で編集し、結果をoutput_fileに書き出すサンプルです。func を省略すると、単なる文字コード変換として動作します。
func の戻り値がそのまま output_file に書き出されますので、 func 内で必要な編集を行なって下さい。
特定の条件に合致する行だけをoutput_file に抜き出したい、あるいは逆にそれ以外をoutput_file に書き出したい場合は、戻り値に None を指定します。
def trans_file(input_file, output_file, input_encoding, output_encoding, func=None):
"""
指定された入力ファイルからテキストを読み込み、指定された関数を各行に適用してから出力ファイルに書き込む。
Args:
input_file (str): 入力ファイルのパス。
output_file (str): 出力ファイルのパス。
input_encoding (str): 入力ファイルの文字エンコーディング。
output_encoding (str): 出力ファイルの文字エンコーディング。
func (function, optional): 各行に適用される関数。デフォルトはNone。
Returns:
None
"""
# 読み込むファイルをオープン
with open(input_file, 'r', encoding=input_encoding) as input_fp:
# 書き込むファイルをオープン
with open(output_file, 'w', encoding=output_encoding) as output_fp:
# 1行づつ読み込む
for i,line in enumerate(input_fp) :
# 関数が None でなければ実行
if func is not None :
# 関数の戻り値を取得
line = func(i,line)
# line が Noneでなければファイルに書き込む
if line != None :
output_fp.write(line)
if __name__ == '__main__':
# 5行目以降のアルファベットについて小文字を大文字に変換する関数
def myfunc(i,line) :
if i > 5 :
line = line.upper()
return None if "10" in line else line
trans_file("p:/hoge.txt","p:/out.txt","shift-jis","utf-8",myfunc)1つのファイルを指定行数ごとに分割する
指定した行数でファイルを分割するサンプルです。分割するファイルがCSVファイルの場合、ヘッダを指定することで、分割されたファイルにもヘッダを含めることが出来ます。
import os
def split_file(input_file, output_file, line_max, input_encoding,output_encoding,header_count=0):
"""
指定されたファイルを指定された行数ごとに分割します。
Args:
input_file (str): 入力ファイルのパス。
output_file (str): 出力ファイルのベースパス。
line_max (int): 1ファイルあたりの最大行数。
input_encoding (str): 入力ファイルのエンコーディング。
output_encoding (str): 出力ファイルのエンコーディング。
header_count (int, optional): 先頭のヘッダーの行数。デフォルトは0。
Returns:
None
"""
headers = [] # ヘッダーを格納するリスト
file_no = 0 # 出力ファイルの連番
line_no = 0 # 行番号
body_count = 0 # ボディの行数カウンタ
output_fp = open(output_file, "w",encoding=output_encoding) # 出力ファイルポインタ
with open(input_file, 'r', encoding=input_encoding) as input_fp:
for line in input_fp:
# ヘッダをリストに保存する
if line_no < header_count :
headers.append(line)
else :
# ボディの行数が分割数に達すると新しいファイルを作成
if body_count >= line_max :
output_fp.close()
name,ext = os.path.splitext(output_file)
output_fp = open(f"{name}_{file_no}{ext}", 'w', encoding=output_encoding)
# ヘッダを書き込む
output_fp.writelines(headers)
file_no += 1
body_count = 0
# ボディのカウントを1つ増やす
body_count += 1
# ファイルに書き込む
output_fp.write(line)
# 行番号を1つ増やす
line_no += 1
if output_fp is not None:
output_fp.close()
if __name__ == '__main__':
split_file("p:/hoge.txt","p:/out.txt",12,"shift-jis","utf-8",2)複数のファイルを1つのファイルに結合する
input_file で指定されたファイル名末尾が連番のファイルを output_file に結合するサンプルです。
CSVファイルの結合にも利用できるよう、 2つ目以降のファイルについては、header_count で指定した行数分を読み飛ばすようにしています。
input_file は、例えば "hoge.txt" を指定すると、 "hoge*.txt" のワイルドカードでヒットするファイルが結合されますので、その点はご注意ください。
import os
import glob
def merge_files(input_file, output_file, input_encoding, output_encoding,header_count = 0):
"""
指定されたファイル名の連番で、同じ拡張子を持つCSVファイルを抽出し、それらをソートしてマージします。
Args:
input_file (str): ベースとなる入力ファイル名。連番の部分は「_数字.csv」の形式である必要があります。
output_file (str): 出力ファイル名。
input_encoding (str): 入力ファイルのエンコーディング。
output_encoding (str): 出力ファイルのエンコーディング。
header_count (int): CSVファイルのヘッダーの行数。0の場合はヘッダーがないと見なします。
Returns:
None
"""
# ファイル名の拡張子部分を取得
name, ext = os.path.splitext(input_file)
# 同じ拡張子を持つCSVファイルを抽出し、ソートする
mearge_files = sorted(f for f in glob.glob(f"{name}**{ext}"))
# マージするファイルが存在しない場合は処理を終了
if not mearge_files:
print("マージするファイルが見つかりませんでした。")
return
# 出力ファイルを開く
with open(output_file, 'w', encoding=output_encoding) as output_fp:
# 各ファイルを順番に開いて内容をマージする
for file_no, file_name in enumerate(mearge_files):
with open(file_name, 'r', encoding=input_encoding) as input_fp:
for line_num, line in enumerate(input_fp):
# 2番目以降のファイルのヘッダはスキップする
if file_no > 0 and line_num < header_count :
continue
# ファイルに書き込む
output_fp.write(line)
# テスト用の呼び出し例
if __name__ == '__main__':
merge_files("p:/hoge.txt", "p:/out.txt", "shift-jis", "utf-8",0)通常のテキストエディタでは開けない巨大なファイルの一部を表示する。
メモリに読み込めないようなファイルに対して、中身を確認するためのサンプルです。
ランダムアクセスの際に指定する基準位置は、import os すると os.SEEK_SET、os.SEEK_CUT、os.SEEK_END で指定できますが、それぞれ数値の 0,1,2 に対応しているので、直接数値で指定しています。
def display_partial_binary(file_path, start_position, size, chunk_size=16):
"""
指定された位置から指定されたサイズ分のバイトを読み取り、16進数と文字列の形式で表示します。
Args:
file_path (str): ファイルのパス。
start_position (int): 読み取りを開始する位置(バイト単位)。
size (int): 読み取るバイト数。
chunk_size (int): バイト列を表示する際のチャンクサイズ。デフォルトは16。
Returns:
None
"""
with open(file_path, 'rb') as file:
# ファイルの末尾まで移動して、サイズを取得
file.seek(0, 2)
file_size = file.tell()
# 指定された位置がファイルサイズを超えている場合は処理を終了
if start_position >= file_size:
print("指定された位置がファイルの範囲を超えています。")
return
# 指定された位置から読み取るサイズを計算
remaining_size = min(size, file_size - start_position)
# ファイルの指定された位置に移動
file.seek(start_position)
# 読み取りと表示
bytes_read = 0
while bytes_read < remaining_size:
chunk = file.read(chunk_size)
display_chunk(chunk, start_position + bytes_read,chunk_size)
bytes_read += len(chunk)
def display_chunk(chunk, start_position,chunk_size):
"""
バイト列を16進数と文字列の形式で表示します。
Args:
chunk (bytes): 表示するバイト列。
start_position (int): バイト列の開始位置(ファイル内の絶対位置)。
chunk_size : 16進数部分の表示桁数
Returns:
None
"""
hex_chunk = ' '.join(f"{byte:02X}" for byte in chunk)
text_chunk = ''.join(chr(byte) if 32 <= byte <= 126 else '.' for byte in chunk)
print(f"{start_position:08X} | {hex_chunk.ljust(chunk_size*3)} | {text_chunk}")
# テスト用の呼び出し例
if __name__ == '__main__':
display_partial_binary("P:/hoge.txt", 0, 256)
実行結果は次のようになります
00000000 | 48 65 61 64 65 72 31 0D 0A 48 65 61 64 65 72 32 | Header1..Header2
00000010 | 0D 0A 31 20 43 43 43 43 30 0D 0A 32 20 43 43 43 | ..1 CCCC0..2 CCC
00000020 | 43 31 0D 0A 33 20 43 43 43 43 32 0D 0A 34 20 43 | C1..3 CCCC2..4 C
00000030 | 43 43 43 33 0D 0A 35 20 43 43 43 43 34 0D 0A 36 | CCC3..5 CCCC4..6
00000040 | 20 43 43 43 43 35 0D 0A 37 20 43 43 43 43 36 0D | CCCC5..7 CCCC6.
00000050 | 0A 38 20 43 43 43 43 37 0D 0A 39 20 43 43 43 43 | .8 CCCC7..9 CCCC
00000060 | 38 0D 0A | 8..
まとめ
今回は、ファイルの読み書きをテーマにして、テキストファイル、バイナリファイル、そしてランダムアクセスについて、関数の使い方とその注意点を含め、詳しく解説しました。
ファイル操作においては、引数の使い方を誤るとファイルが壊れるリスクがあるため、その部分についても注意点として盛り込みました。
さらに、最後の章では、巨大なファイルを扱うためにメモリを極力使わない方法を用いて、ファイルの分割および結合を行うサンプルを紹介しました。また、通常のテキストエディタでは開けないような大きなファイルに対して、ランダムアクセスで指定した部分のみを取り出して表示するサンプルも掲載しています。
サンプルはコピペして使えるように関数化しており、手を加えやすいようにコメントも多めに書いてあります。皆さんのニーズに合わせて修正し、ご利用いただければ幸いです。








コメント