stable diffusion web ui には数多くのモデルがあり、プロンプトを工夫することで、意図するものに近い画像を生成することは可能ですが、それでも限界はあります。
たとえば、特定の衣装やキャラクター、画風、手元にある写真や画像の特徴を生成画像に反映させたい場合、プロンプトでは表現しづらい場合も少なくありません。
そんな時、既存のモデルに対して、手元にある画像を追加学習させると、プロンプトでは表現しずらい特徴を生成画像に反映できるようになります。
今回は、stable diffusion 向け生成モデルに対しての追加学習で最近注目されている LoRA学習 について、その環境構築から実際の追加学習に至るまでの手順を、図をつかって詳しく解説したいと思います。
LoRAとは
生成モデルは膨大な学習データと膨大な計算コストを用いて作成されており、後から追加で学習させる場合においても、相応の学習データと計算コストが必要でした。
LoRAとは、Low-Rank Adaptationの頭文字を取った略語で、追加学習の際に必要となるメモリと計算量を大幅に削減し、かつ数十枚という少ない画像データでも良好な結果が得られるという、画期的な手法です。
このLoRAはChatGPTをはじめとする大規模言語モデルや、Stable Diffusionなどの画像生成モデルへの追加学習方法として応用されています。
とはいえ、stable diffusion で LoRA学習する場合は、最低でも6GBのメモリを搭載したGPU(グラボ)が必要となります。
もし、お使いのパソコン環境において、搭載されているGPU(グラボ)がこれに満たないのであれば、「【実験】stable diffusion でおすすめのGPU(グラボ)は?(RTX-3060 vs RTX-4070)」の記事を参考に、ご購入を検討して頂ければと思います。
説明はこのくらいにして、本記事では「LoRA学習環境の構築」と「LoRAモデルの作成」の2章に分けて説明していきます。
LoRA学習環境の構築
LoRA学習の方法にはいくつかありますが、今回は「DreamBooth、キャプション方式」と呼ばれる方法を使用します。
理由は、同じ画像から追加学習させたい部位を指定できることと、もっとも広く普及しているからです。
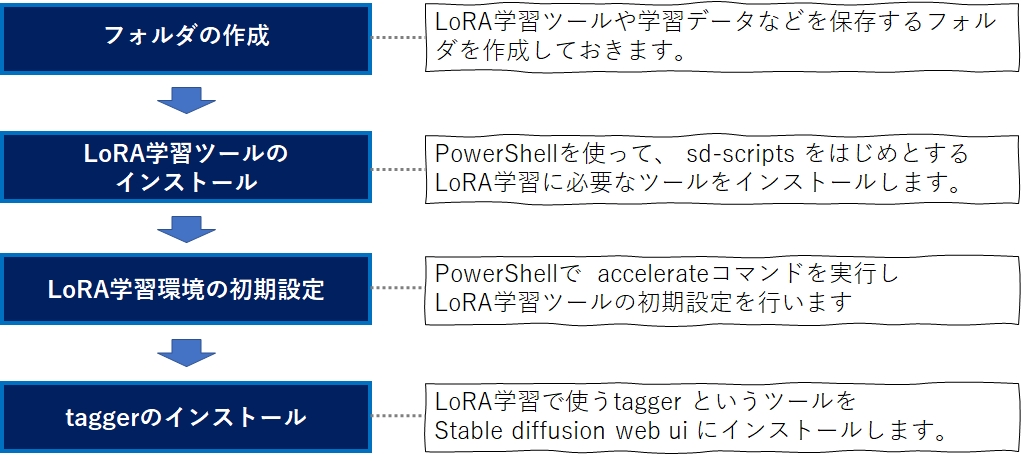
さて、LoRA学習の環境を作るには、Kohya-ssさんが作った sd-script というツールと、taggerと呼ばれる拡張機能をインストールしなければなりません。
Kohya-ss はコマンドプロンプトでいくつかのコマンドを実行することで、tagger は stable diffusion web ui の extensionタブからインストールすることが可能です。
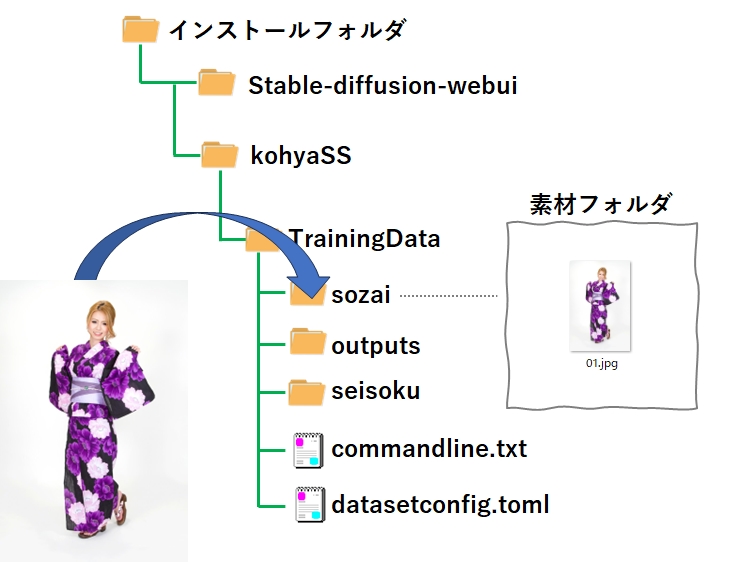
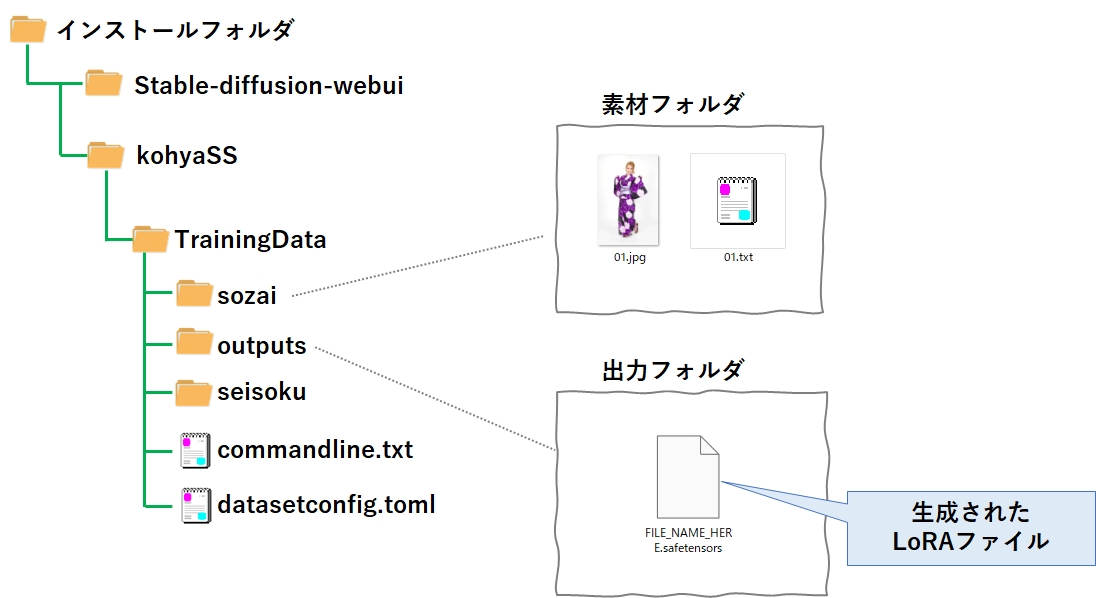
フォルダの作成
sd-scriptは GitHub のこちらのページで公開されており、git コマンドでローカルに持ってくるので、それを格納するフォルダが必要です。
また、LoRA学習させるための学習データ(素材データ)を格納する場所や、出来上がったLoRAモデルの出力先を確保しておく必要があるため、このタイミングでフォルダを作成しておきましょう。
エクスプローラーで空のフォルダや空のファイルを作成するのが面倒な方は、次の章で紹介するコマンドを入力して頂いてもOKです。
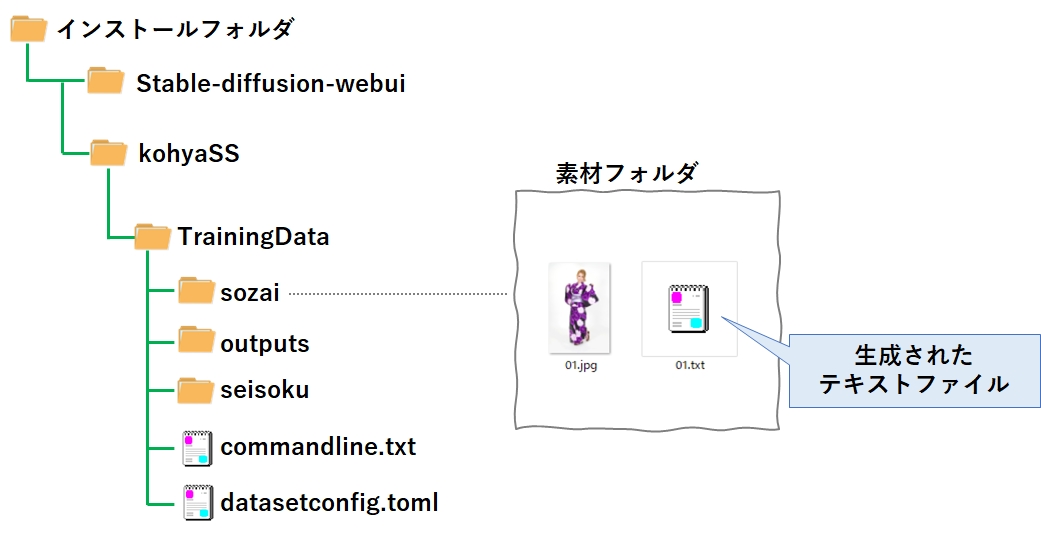
場所とフォルダ階層は特に決められていませんので、今回は下記のフォルダ階層で作成しました。
ついでに、LoRA学習時に必要となる2つのファイルも、中身は空で良いので作成しておきます。
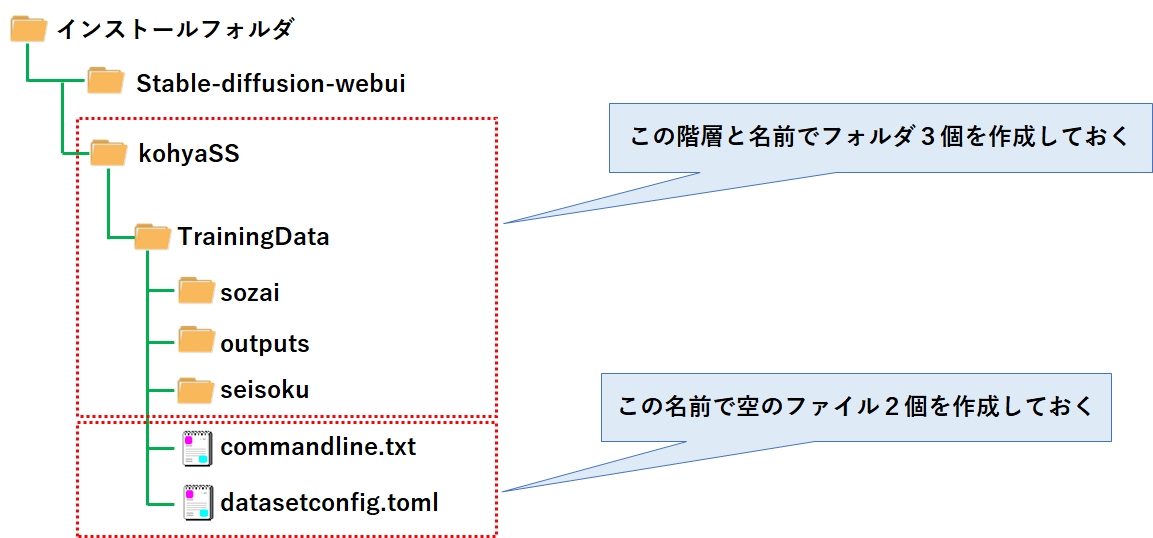
| フォルダ/ファイル | 役割 |
|---|---|
| sozai | 学習データ(素材データ)の格納場所フォルダ |
| outputs | 出来上がったLoRAファイルの出力先フォルダ |
| seisoku | 「チワワ」と「犬」で画像を学習させたとき、プロンプトに「犬」と入力すると、「チワワ」しか出てこなくなる現象(過剰適合)が発生する。 これを防ぐには、ランダムな犬の画像を学習させて「チワワ」と「犬」を切り離させる方法を使うが、このための学習データを格納するフォルダ。 LoRAはプロンプトにテキストで入力することで発動するため、プロンプトから消すことでも解決できる。従って今回はフォルダは作るが使わない。 |
| commandline.txt | LoRA学習時のコマンドに指定するパラメータを記述したファイル。 |
| datasetconfig.toml | LoRA学習で使う学習データ(素材データ)の場所や、学習の繰り返し回数などを記述したファイル |
LoRA学習ツールのインストール
以前、「【最短&簡単】Stable diffusion web UI インストール方法(AUTOMATIC1111版)」で紹介した「WinPython+Portable Gitでお手軽Python環境を構築しようよ」の記事で作られたPython環境を前提に説明していきます。独自で環境を構築されている方は、ご自身の環境に読み替えてください。
まず、コマンドプロンプトを起動するために、@CommandPrompt.bat を実行(ダブルクリック)して下さい。

開いたコマンドプロンプトに、以下のコマンドを1行づつ入力し、エンターキーを押して実行していきます。その作業が面倒という方は、まとめてコピーしてコマンドプロンプトに一気に張り付けて、エンターキーを数回叩くという荒業をしていただいても、だぶん大丈夫だとは思います。
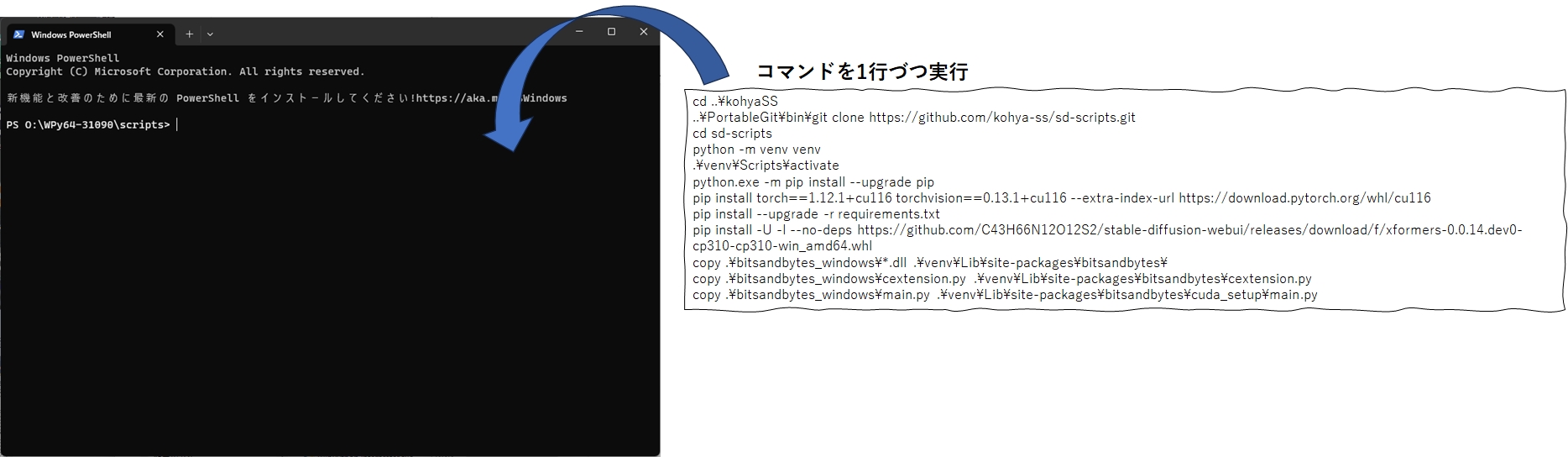
まだフォルダを作成していない方は、次のコマンドをコマンドプロンプトに張り付けて実行して下さい。自動的に空のフォルダと空のファイルが出来上がります。
md ..\kohyaSS
md ..\kohyaSS\TrainingData
md ..\kohyaSS\TrainingData\sozai
md ..\kohyaSS\TrainingData\outputs
md ..\kohyaSS\TrainingData\seisoku
type nul > ..\kohyaSS\TrainingData\commandline.txt
type nul > ..\kohyaSS\TrainingData\datasetconfig.toml次に、GitからkohyaSS 一式、その他インストールするコマンドを実行します。
以降の操作はkohyaSSの公式ページに記載されている内容から必要な部分を抜粋したものになります。
コマンドプロンプトに下記のコマンドを張り付けて実行して下さい。
cd ..\kohyaSS
..\PortableGit\bin\git clone https://github.com/kohya-ss/sd-scripts.git
cd sd-scripts
python -m venv venv
.\venv\Scripts\activate
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --index-url https://download.pytorch.org/whl/cu118
pip install --upgrade -r requirements.txt
pip install xformers==0.0.20Lora学習環境の初期設定
実行し終えたら、次のコマンドを入力し、画面の質問(英語)に答えてください。
accelerate config
全部で7つの質問があります。最初にエンターを2回、次にnoを3回、次にエンターを1回、最後にfp16 と入力すればOKです。

何度でもやり直せますので、間違って矢印やエンターを入力してしまった、あるいはエラーになった場合は、再び accelerate config コマンドを実行して下さい。
最後に、次のコマンドを実行します。
python -m pip install bitsandbytes==0.41.1 --prefer-binary --extra-index-url=https://jllllll.github.io/bitsandbytes-windows-webuiTaggerのインストール
次に、Taggerをインストールします。TaggerもGitHubのこちらのページで公開されていますので、こちらからインストールします。
まず @CommandPrompt.bat をダブルクリックして、コマンドプロンプトから次のコマンドを入力します。
cd ..\stable-diffusion-webui\extensions
git clone https://github.com/picobyte/stable-diffusion-webui-wd14-tagger.git taggerコマンドプロンプトを一旦閉じて、@SD.bat をダブルクリップで実行して下さい。
しばらくすると stable diffusion が起動し、Tagger タブが表示されているはずです。
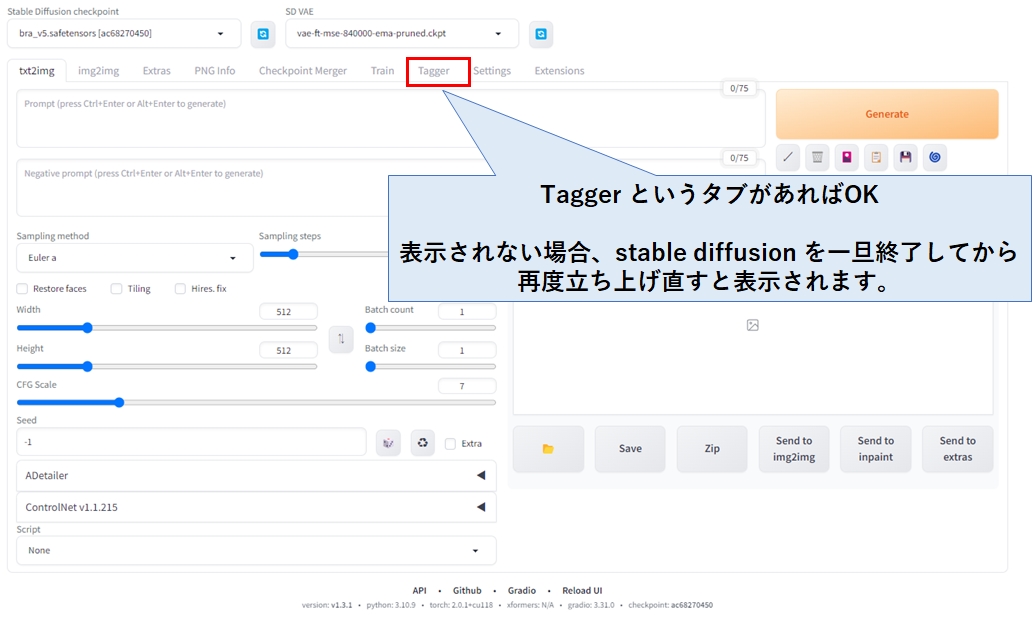
以下は動作確認ですので、飛ばしてもらっても構いません。
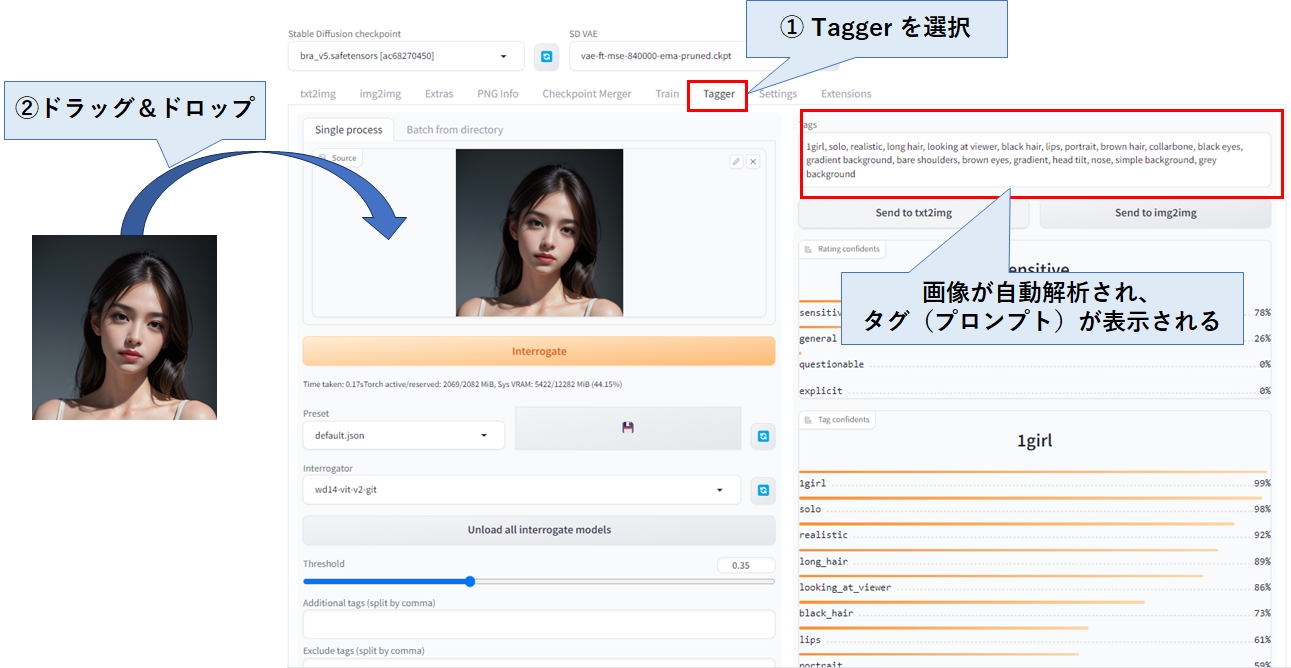
Taggerタブをクリックし、任意の画像をドラッグ&ドロップすると、タグの一覧(プロンプトのこと)が表示されます。
Taggerは画像に埋め込まれたタグ(プロンプト)を参照しているのではなく、画像の中身を認識して適切なタグを生成してくれるため、stable diffusion で生成されていない、普通のデジカメで撮影した画像でもOKです。
LoRAモデルの作成
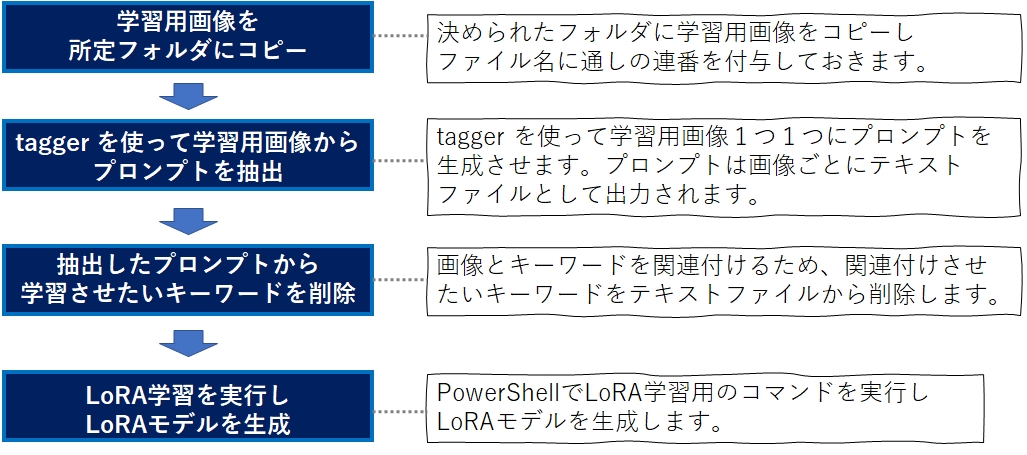
LoRAモデルを作るには、次の4つの手順が必要になります。今回は試しに学習画像を1枚だけ使ってLoRAモデルの作成方法を説明します。実際にLoRAモデルを作成する際は、20枚くらいは用意して下さい。
ちなみに、学習画像は多いほど良いようで、50枚より500枚の方が、品質の高い結果が得られるようです。
学習用画像を所定フォルダにコピー
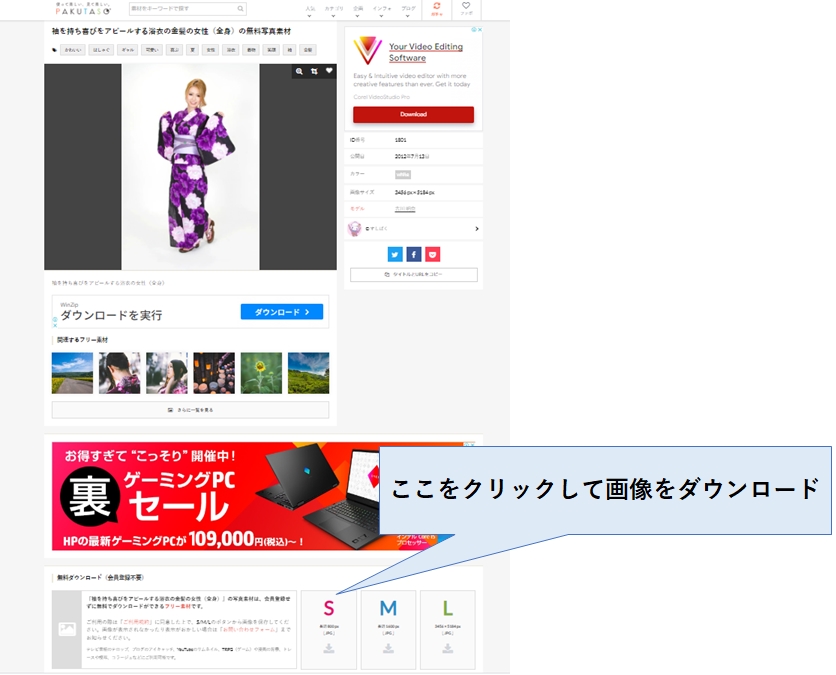
まず最初に、今回の学習で使う画像を、フリー素材「ぱくたそ」からダウンロードしましょう。
下の画像をクリックすると該当ページにジャンプしますので、少しスクロールして「S」の箇所をクリックするとダウンロードできます。
次に、ダウンロードしたファイルのファイル名を「01.jpg」に変更して下さい。学習データ(素材データ)として使う画像ファイルは、必ずファイル名を連番にして下さい。
Tagger を使って学習用画像からプロンプトを抽出
前述のTaggerの説明では1枚だけ処理しましたが、LoRA学習では複数枚の画像(20枚~)を学習させる必要があるため、指定したフォルダの画像をまとめて処理します。
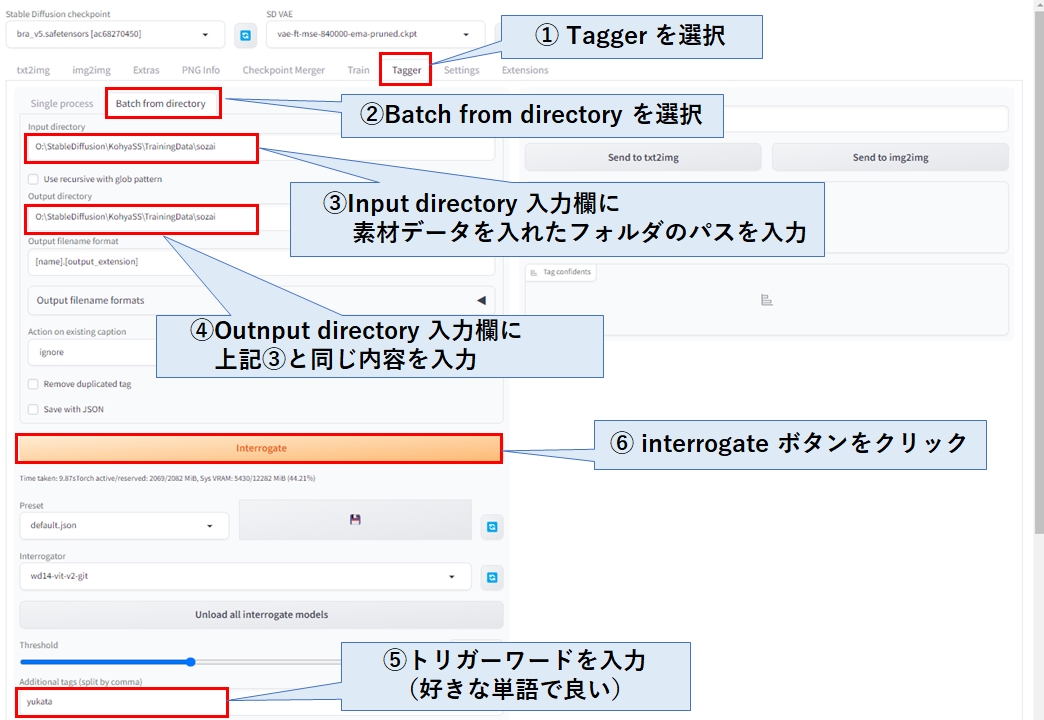
Taggerタブ→Batch from directory タブを選択し、学習データ(素材データ)を格納したフォルダのパスを②と③に張り付けてください。
こうすることで、学習データ(素材データ)と同じフォルダに、画像枚数の数だけタグ(プロンプト)が格納されたファイルが生成されます。
最後に、任意のトリガーワードを入力し、interrogate ボタンをくリックします。
トリガーワードは LoRAを発動させるためのキーワードになりますので、作成するLoRAにちなんだ名前を付けましょう。
抽出したプロンプトから学習させたいキーワードを削除
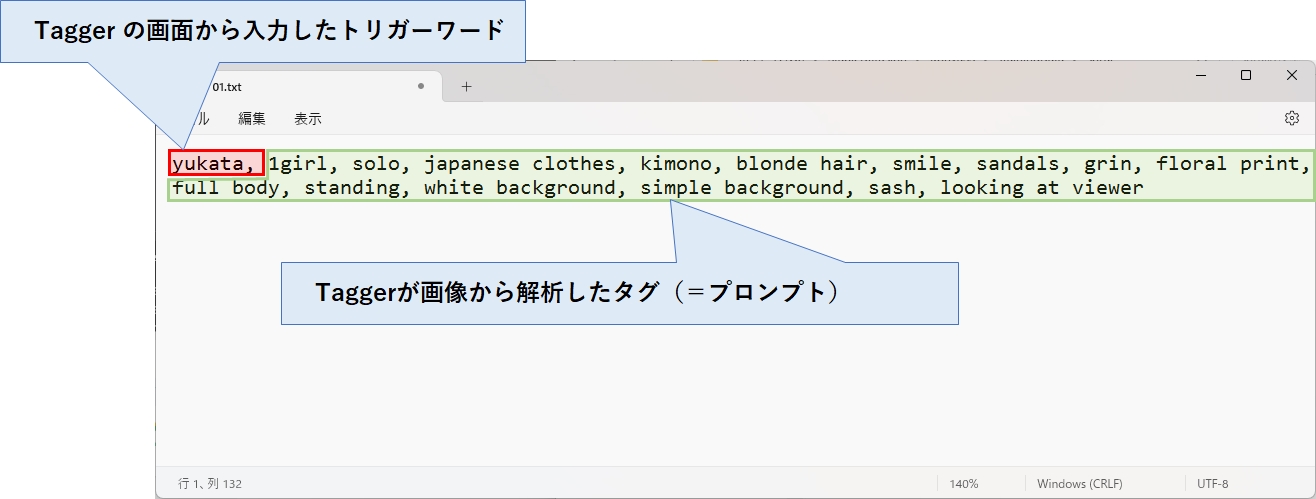
次に生成されたテキストファイル(今回は01.txt)をメモ帳などのテキストエディタで開いてください。
先頭にはトリガーワードが格納されており、続けて解析結果のタグ(プロンプト)がカンマ区切りで列挙されています。
ここから、学習させたいキーワードを削除(残すのではなく、削除)します。
今回は、kimono というキーワドを削除しました。japanese clothes (和服)も削除した方がよかったかもしれませんが、とりあえず残しておきました。
もし、女性として学習させたいなら、1girl を、人物の顔を学習させたいなら、smile や looking at、grin など顔に関するキーワードを、髪型なら blonde hair などを削除します。
逆にトリガーワード以外を全て削除すると、この写真全体が学習対象となります。
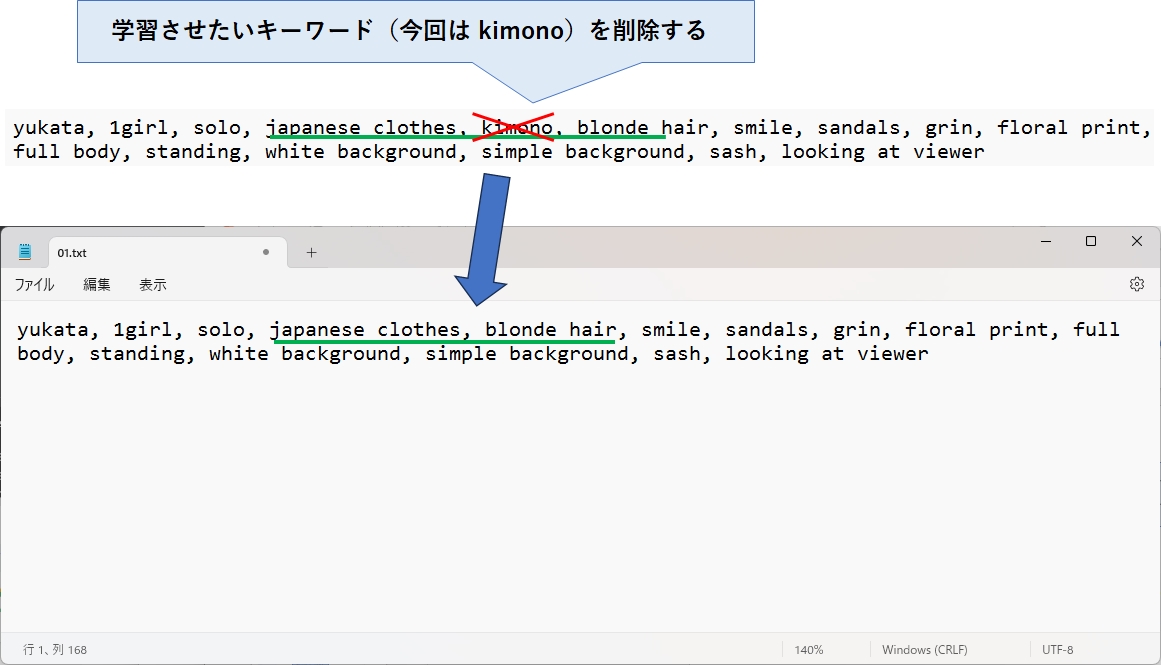
学習させたいキーワドを削除したら、ファイルを保存して下さい。学習データ(素材データ)が複数ある場合、全てのテキストファイルにこの操作を行う必要があります。
LoRA学習を実行しLoRAモデルを生成
いよいよLoRA学習の開始です。その前に最初に空で作った commandline.txt と datasetconfig.toml の中身を記述しておきましょう。
まず、commandline.txt をメモ帳で開いて、下記の内容を貼り付けます。
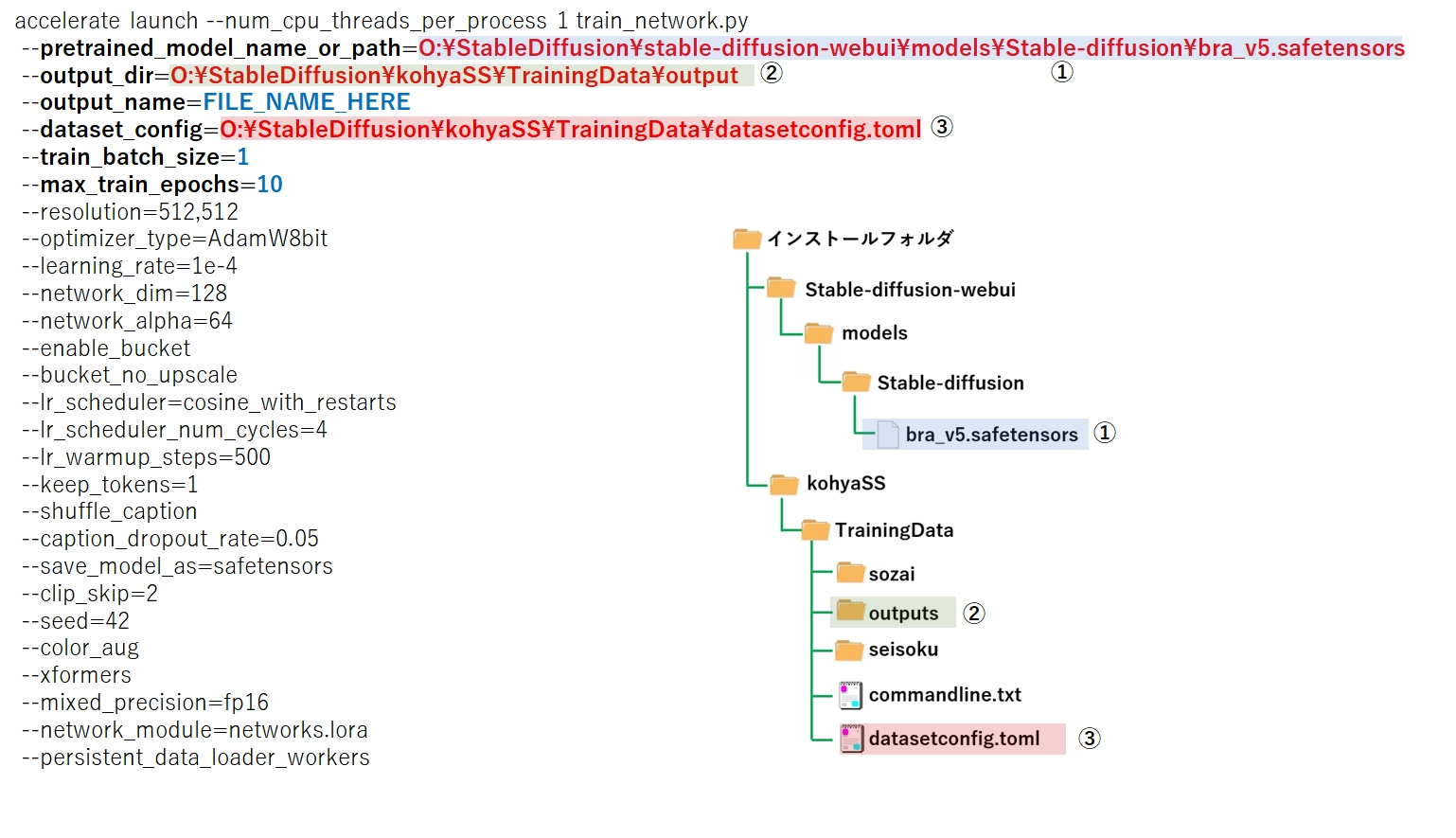
accelerate launch --num_cpu_threads_per_process 1 train_network.py
--pretrained_model_name_or_path=****モデルファイルのパス****
--output_dir=****LoRAファイルの出力先フォルダのパス****
--output_name=FILE_NAME_HERE
--dataset_config=****datasetconfig.tomlファイルのパス****
--train_batch_size=1
--max_train_epochs=10
--resolution=512,512
--optimizer_type=AdamW8bit
--learning_rate=1e-4
--network_dim=128
--network_alpha=64
--enable_bucket
--bucket_no_upscale
--lr_scheduler=cosine_with_restarts
--lr_scheduler_num_cycles=4
--lr_warmup_steps=500
--keep_tokens=1
--shuffle_caption
--caption_dropout_rate=0.05
--save_model_as=safetensors
--clip_skip=2
--seed=42
--color_aug
--xformers
--mixed_precision=fp16
--network_module=networks.lora
--persistent_data_loader_workers次に、pretrained_model_name_or_path、output_dir、dataset.config の部分、をご自身の環境に変更して下さい。
私の場合は、Oドライブ直下に StableDiffusion というフォルダを作り、その中に諸々の環境を格納しておりますので、読み替えて修正をお願いします。
変更が完了したら、保存して下さい。
次に datasetconfig.toml をメモ帳で開いて、下記の内容を貼り付けます。
[general]
[[datasets]]
[[datasets.subsets]]
image_dir = '****学習ファイル(素材ファイル)を格納したフォルダのパス****'
caption_extension = '.txt'
num_repeats = 10
次に、image_dir の箇所を、ご自身の環境に合わせて書き換えて、保存して下さい。この時、フォルダパスの前後はシングルクォート ( ’ ) で括っておいてください。

ここまでの作業が完了したら、再びコマンドプロンプトを開いて、次のコマンドを入力、実行します。
cd ..\kohyass\sd-scripts
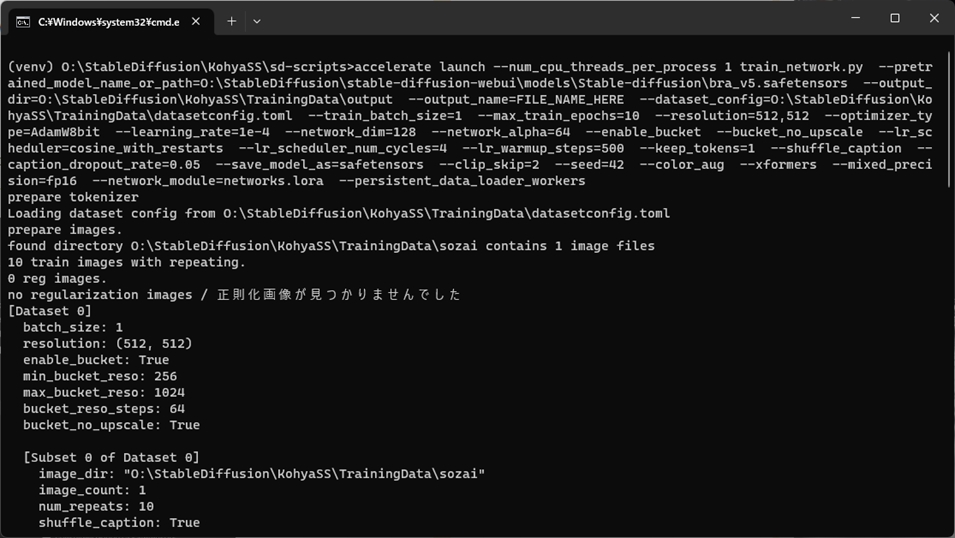
.\venv\scripts\activate次に、commandline.txt をメモ帳で開いて、各行の改行コードを削除し、1つの長い文字列に編集してから、全選択(Ctrl+A)し、コマンドプロンプトに 貼り付け(Ctrl+V)して、エンターキーを押します。
このコマンドを実行すると、下記のような画面になり、LoRA学習が始まります。
GPU(グラボ)の性能にもよりますが、数十分~数時間掛かります。
進行状況が画面に表示されますが、以下の様になれば学習が完了です。
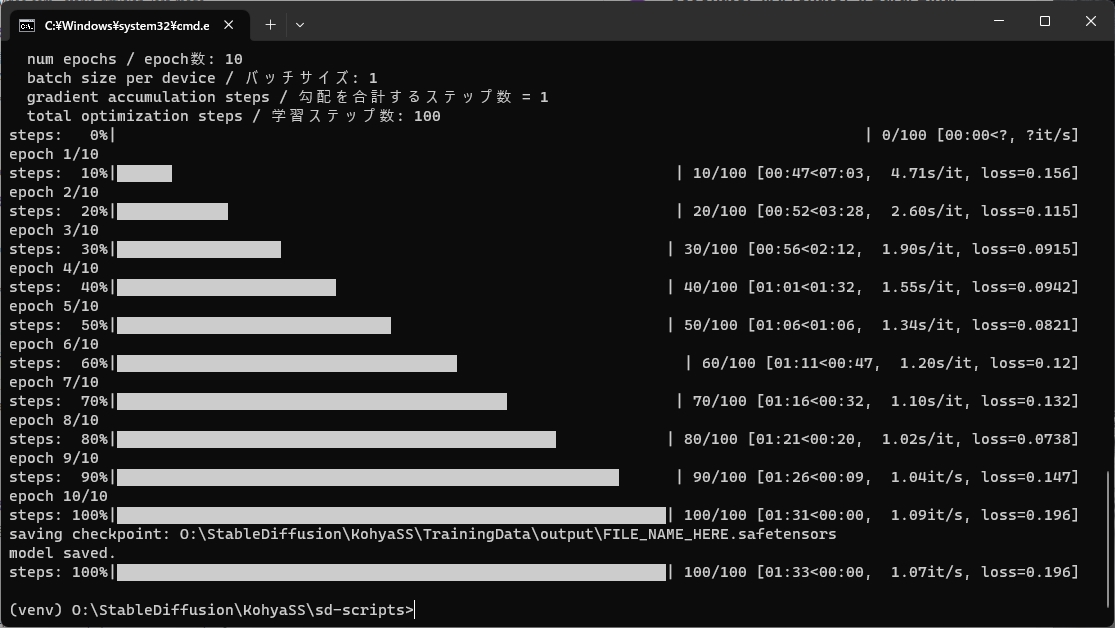
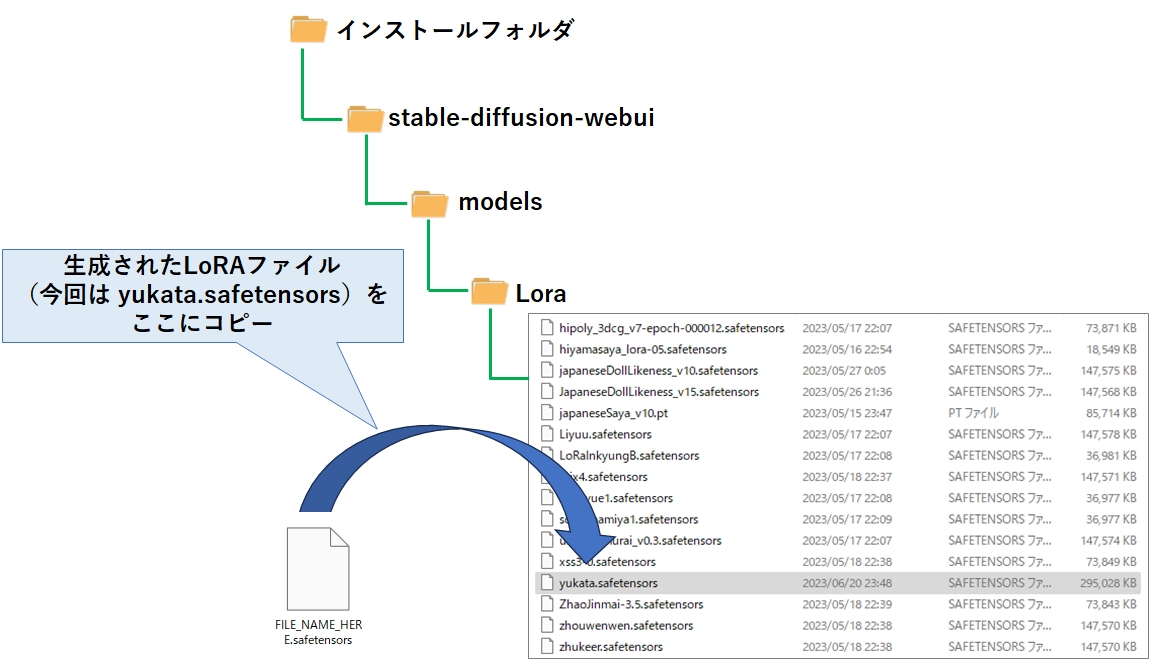
無事完了したら、output フォルダに FILE_NAME_HEAR.safetensors というファイルが出来上がっています。これがLoRAファイル(モデルファイル)になります。
LoRAファイルの名前は commandline.txt の上から4行目にある --output_name=~ を書き換えることで指定できますが、出来上がったファイル名を直接書き換える方が楽なので、今回はあえてそのままにしています。
後は、これを stable-diffusion-web→models→Lora フォルダにコピーすれば、使えるようになります。
stable diffusion web ui を立ち上げて、プロンプトに <lora:yukata:1>,yukata と入力し、Genarateボタンをクリックすると、Loraが適用された画像が生成されます。
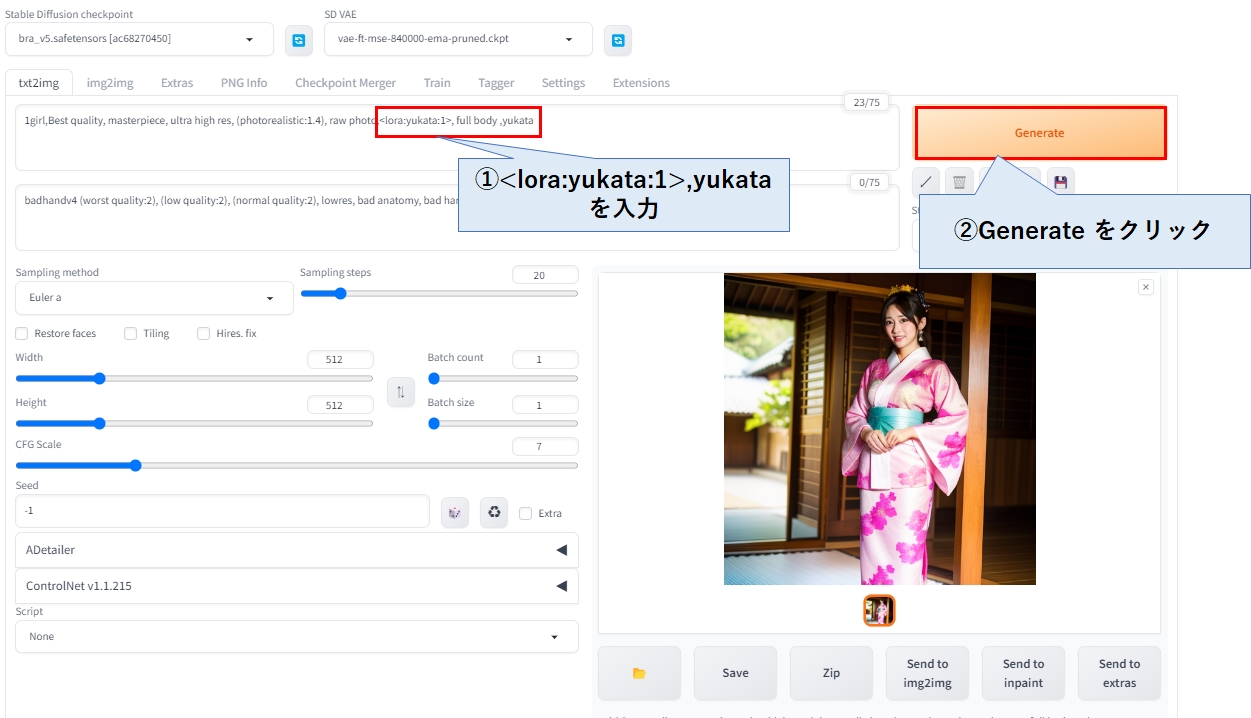
今回は1枚のみの学習だったので、上記のな綺麗な画像は生成できません。実は上記の画像は、lora ではなく、単純に yukata で生成されているだけなのです。私も驚いたのですが、bra_v5 の生成モデルは、yukata というキーワードでも学習されており、和服姿の画像が生成されます。
まあ、今回はLoraの作り方を解説したかったので、これで良しとして下さいw。
num_repeats 、max_train_epochs、 train_batch_size の目安
LoRAの画質について重要なパラメータが3つあります。
datasetconfig.toml の num_repeats と train_batch_size
commandline.txt のmax_train_epochs
それぞれの役割は以下の通りです。
| パラメータ名 | 役割 |
|---|---|
| num_repeats | 学習データ(素材データ)の水増しのため、同じ画像を複製する回数。 正則化に使う画像に比べて学習データ(素材データ)の枚数が少なすぎる 場合、num_repeats を指定して学習画像を水増し、両者のバランスを取る 時に使用。 |
| max_train_epochs | 学習全体を繰り返す回数。 少なすぎても多すぎても良くないので、丁度よい回数を探す必要あり。 |
| train_batch_size | GPUの中で学習を並行で走らせる際の同時並行数。 GPUのメモリに依存するが、12GB搭載していれば4は指定可能。 |
学習の進み具合はステップ数という値で表現され、以下の計算式で計算されます。
ステップ数=(学習画像の数 × num_repeats × max_train_epochs) ÷ train_batch_size
学習画像は、様々な表情を含むバリエーションの多い画像を出来るだけ多く用意する方が、画像の特徴を効率よく学習し、生成画像にその特徴を反映しやすくなります。
また、学習画像は出来るだけノイズが少なく綺麗な画像で、正面に近い画像が望ましいです。
では、max_train_epochs にはどれくらいの値を指定すればよいのでしょう?
画像の中身や画質によって異なるため一概には言えませんが、人物系フォトリアルのLoRAを作成する場合における、私の肌感の目安を、train_batch_size が4,2,1それぞれについて提示しておきます。
| 学習データ (素材データ) の枚数 | max_train_epochs (train_batch_size=4) | max_train_epochs (train_batch_size=2) | max_train_epochs (train_batch_size=1) |
|---|---|---|---|
| ~200枚 | 50 | 100 | 200 |
| 200枚~600枚 | 30 | 60 | 120 |
| 600枚~ | 25 | 50 | 100 |
| 1000枚~ | 15 | 30 | 60 |
| 2000枚~ | 10 | 20 | 40 |
繰り返しますが、LoRAモデルの品質は学習データ(素材データ)の画質によって左右されるため、あくまでも目安ですが、おおよそ3000~4000ステップくらいで、そこそこ良い結果が得られるようです。
注意としては、ステップ数は多ければ多いほど良いというものでもなく、ある一定上を超えると頭打ちになり、逆に品質が低下する(過学習の状態)こともあるため、どれくらいで良い結果が得られるかはご自身の環境で試行錯誤が必要です。
画像ファイルのリネームとタグ(プロンプト)編集の便利ツール
ここからはおまけです。実は、学習で使う画像ファイルを連番でリネームする作業と、タグ(プロンプト)テキストから学習させたいキーワードを削除する作業は、学習データが多いほど面倒です。
そこで、この2つの作業が楽になるようにPythonでプログラムを組んでみました。
ChatGPTに依頼して出来上がったプログラムをデバッグし、少々手を加えて一通り動作することが確認できたので、紹介しておきます。
画面はチープですし、プログラムの組み方も良いとは言えませんが、迅速に公開したかったので、ご了承ください。
なお、指定したフォルダの画像ファイルを強制的にリネームし、かつTaggerで生成されたテキストファイルを直接書き換えてしまうため、使うときには注意が必要です。
私も実際に使って動作確認していますが、バグが残っている可能性はあります。このプログラムを利用することで何らかの被害を被ったとしても責任は負えませんので、あくまでも自己責任での利用といことでお願いします。
画面の説明
実行すると、次のような画面が表示されます。
この画面で出来ることは次の通りです。
- 指定したフォルダ内の画像ファイルについて、名前を4桁の連番にリネーム
- 指定したフォルダ内のタグ(プロンプト)テキストを読み出し、画面に一覧表示
- 一覧表示したタグをマウス操作で選択/選択解除
- 翻訳結果を用意することで、一覧表示のタグの右横に翻訳結果を合わせて表示
- 選択したタグを元のタグ(プロンプト)テキストから削除
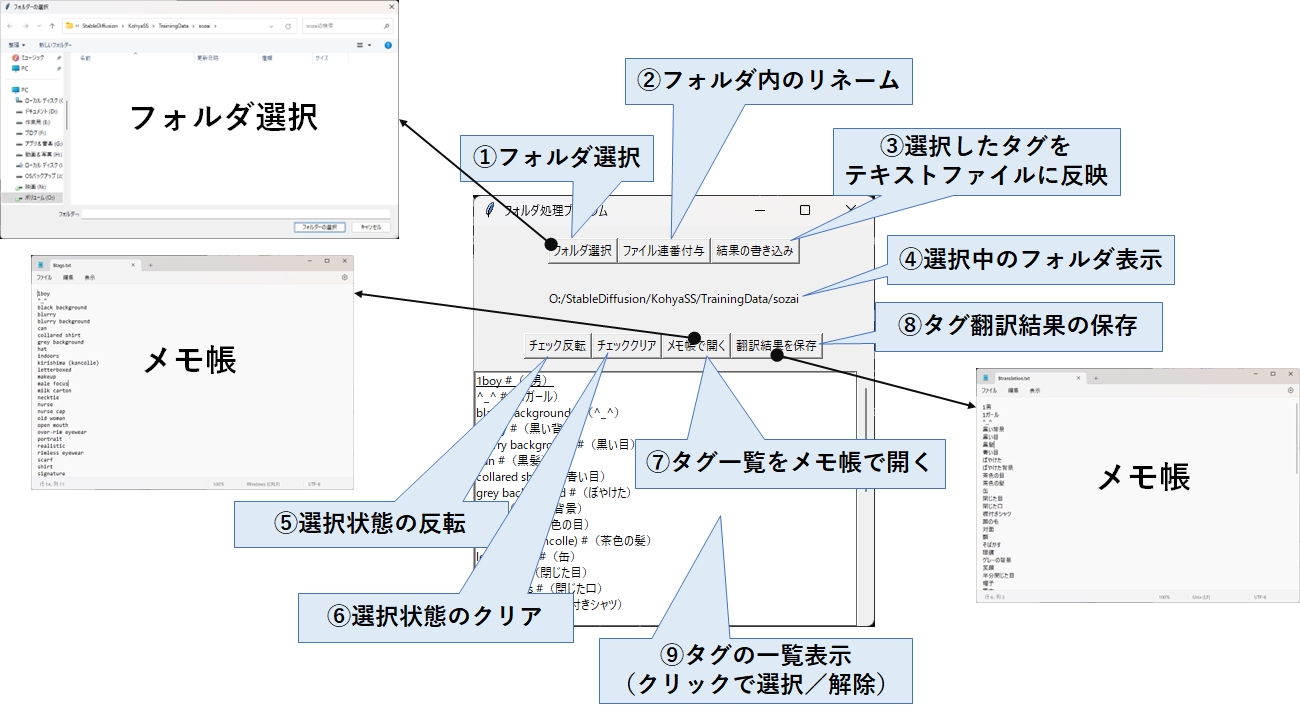
| ①フォルダ選択 | フォルダ選択ダイアログが表示されますので、学習データ(素材データ)が 置かれているフォルダを指定します。 フォルダを指定した瞬間、Taggerが出力したテキストファイルを全て読み込み、 画面に一覧表示します。 |
|---|---|
| ②フォルダ内のリネーム | 選択したフォルダ内にある画像ファイル(拡張子png,jpg,jpeg, gif,bmp) について、0001~の連番でリネームします。 |
| ③選択したタグを テキストファイルに反映 | 選択状態(チェック状態)のタグを、Taggerが出力したテキストファイル から削除します。 この時、Oldというフォルダが自動で生成され、変更前のテキストファイルが そこに退避されます。また、Oldは次に③を実行した時上書きされます。 |
| ④選択中のフォルダ表示 | ①で選択したフォルダのパスが表示されます。 |
| ⑤選択状態の反転 | 一覧表示されているタグにおいて、選択状態(チェック状態)を 反転させます。 |
| ⑥選択状態のクリア | 一覧表示されているタグにおいて、選択状態(チェック状態)を 全てクリアします。 |
| ⑦タグ一覧をメモ帳で開く | 一覧表示されているタグをメモ帳で開きます。 この時、$tags.txtというファイルが作成されます。 |
| ⑧タグ翻訳結果の保存 | $translation.txt というファイルをメモ帳で開きます。 前回張り付けた翻訳結果を残していますので、必要に応じて削除するか、 中身のテキストを張り替えてください。 |
| ⑨タグの一覧表示 (クリックで選択/解除) | クリックすると選択状態(チェック状態)になり、同じ場所をクリックすると 解除されます。 |
ちなみに、①フォルダ選択 を行ったタイミングでテキストファイルを読み込み、タグ一覧を画面に表示しています。例えば②フォルダ内のリネームを行ってから、stable diffusion web ui でタグテキストを作成した場合、そのままではタグ一覧に何も表示されないので、再度①フォルダ選択でフォルダを選択し直して下さい。
一覧表示のタグの右横に翻訳結果を表示する方法
まず最初に、タグ一覧を翻訳する方法として、DeepL翻訳ツール をお勧めしています。このツールは左にタグ一覧を張り付けると、自動で翻訳が開始され、右に結果が表示されます。ちゃんと1行づつ変換されるので、そのままコピペして使うことが出来ます。
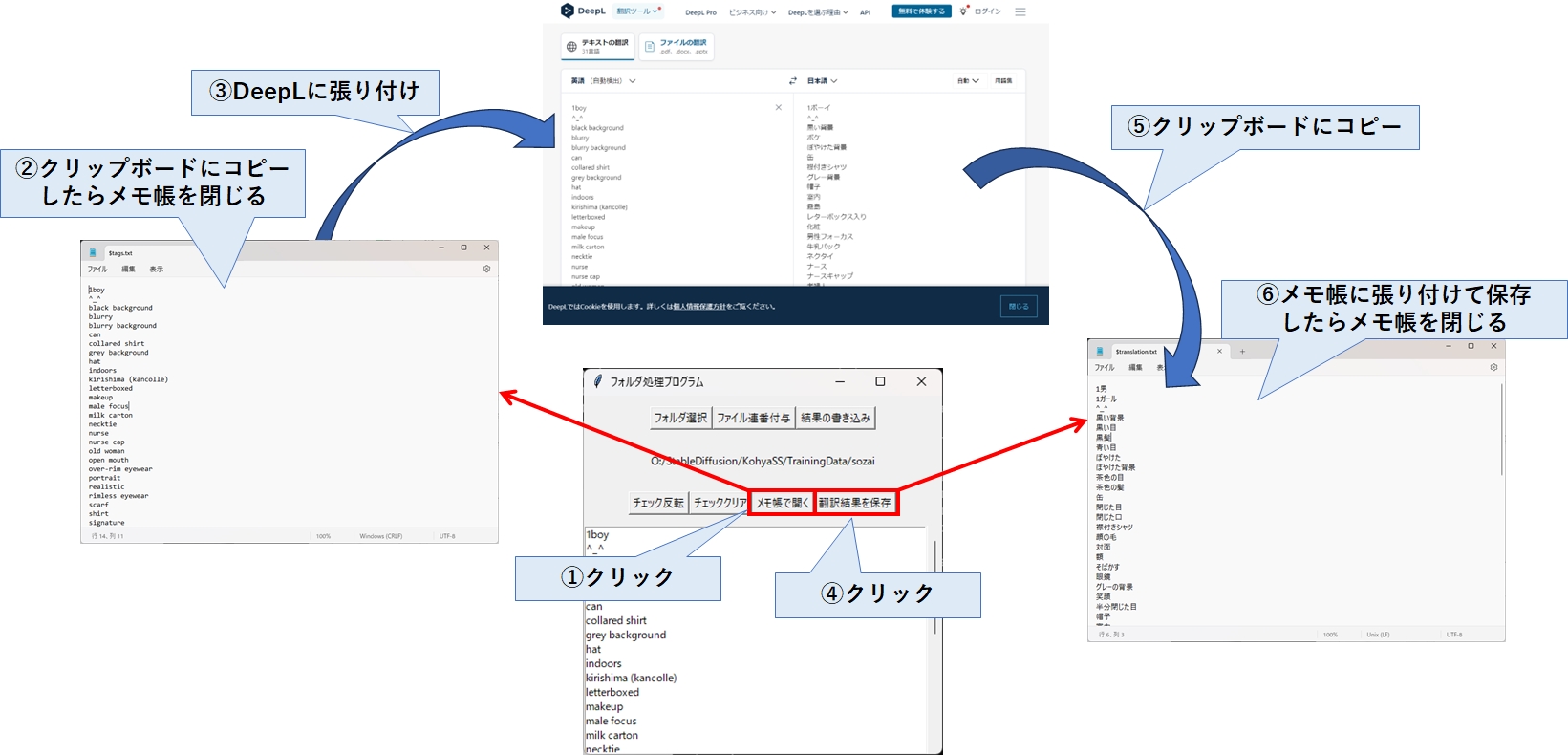
タグ一覧の横に日本語を表示する方法は、以下の①~⑤の手順を実行して下さい。
①でメモ帳が開き、タグ一覧が表示されます。それをDeepLに張り付けましょう。次に、④でメモ帳を表示して、⑤でDeepLの翻訳結果をクリップボードにコピーします。
最後に、⑥でメモ帳を保存したら、タグの横に翻訳結果が表示されているはずです。
ソースコード
下記の内容をメモ帳に張り付けて、deltag.py というファイル名で保存して下さい。保存する場所は何処でもよいですが、Pythonが動作する環境でなければ動きません。
ポータブル環境をお使いの場合は、stable diffusion をインストールしたフォルダ直下に scripts フォルダがあるので、そこに入れておくと便利です。
import os
import shutil
import subprocess
import tkinter as tk
from tkinter import messagebox, filedialog
class Application(tk.Tk):
def __init__(self):
super().__init__()
self.title("フォルダ処理プログラム")
self.geometry("400x400")
self.taglist_name = "$tags.txt"
self.transient_name = "$translation.txt"
self.tag_split_marker = "#"
self.folder_path = ""
self.tag_list = []
self.selected_tags = []
self.create_widgets()
def create_widgets(self):
'''コントロールの表示'''
#フォルダ選択、保存ボタンの表示
self.folder_frame = tk.Frame(self)
self.folder_frame.pack(side=tk.TOP, padx=10, pady=2)
self.folder_button = tk.Button(self.folder_frame, text="フォルダ選択", command=self.select_folder)
self.folder_button.pack(side=tk.LEFT, pady=10)
self.folder_button = tk.Button(self.folder_frame, text="ファイル連番付与", command=self.rename)
self.folder_button.pack(side=tk.LEFT, pady=10)
self.save_button = tk.Button(self.folder_frame, text="結果の書き込み", command=self.save_files)
self.save_button.pack(side=tk.LEFT, pady=10)
#情報表示
self.info_frame = tk.Frame(self)
self.info_frame.pack(side=tk.TOP, padx=10, pady=2)
self.folder_label = tk.Label(self.info_frame, text="フォルダ: ")
self.folder_label.pack(side=tk.LEFT, padx=10, pady=10)
#チェック反転、チェッククリアボタンの表示
self.check_frame = tk.Frame(self)
self.check_frame.pack(side=tk.TOP, padx=10, pady=2)
self.check_button = tk.Button(self.check_frame, text="チェック反転", command=self.toggle_check)
self.check_button.pack(side=tk.LEFT, pady=10)
self.clear_button = tk.Button(self.check_frame, text="チェッククリア", command=self.clear_check)
self.clear_button.pack(side=tk.LEFT, pady=10)
self.clear_button = tk.Button(self.check_frame, text="メモ帳で開く", command=self.open_memo)
self.clear_button.pack(side=tk.LEFT, pady=10)
self.clear_button = tk.Button(self.check_frame, text="翻訳結果を保存", command=self.open_translation)
self.clear_button.pack(side=tk.LEFT, pady=10)
#リストボックスとスクロールバーの表示
self.listbox = tk.Listbox(self, selectmode=tk.MULTIPLE)
self.listbox.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
self.listbox.bind("<Shift-Button-1>", self.shift_click_select)
scrollbar = tk.Scrollbar(self, orient=tk.VERTICAL)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
self.listbox.config(yscrollcommand=scrollbar.set)
def rename(self):
'''ファイル名の変更'''
confirmation = messagebox.askyesno("確認", "フォルダ内のファイル名を連番に変更します。よろしいですか?")
if not confirmation:
return
image_files = []
for filename in os.listdir(self.folder_path):
path = os.path.join(self.folder_path, filename)
if os.path.isfile(path) :
extension = os.path.splitext(filename)[1]
if extension.lower() in ['.png', '.jpg', '.jpeg', '.gif','.bmp']:
image_files.append(path)
for i, file_name in enumerate(image_files, start=1):
file_extension = os.path.splitext(file_name)[1]
new_file_name = f"{str(i).zfill(4)}{file_extension}"
os.rename(os.path.join(self.folder_path, file_name), os.path.join(self.folder_path, new_file_name))
messagebox.showinfo("完了", f"{len(image_files)}のファイル名を変更しました")
def open_memo(self):
# リストに表示されている内容をメモ帳で開く
temp_file = os.path.join(self.folder_path, self.taglist_name)
with open(temp_file,'w',encoding="utf8") as f:
f.write('\n'.join(self.tag_list))
os.startfile(temp_file)
def open_translation(self):
# 翻訳結果の貼り付け用メモ帳を開く
temp_file = os.path.join(self.folder_path, self.transient_name)
if not os.path.isfile(temp_file):
with open(temp_file,'w',encoding="utf8") as f:
pass
subprocess.run(['cmd', '/c', temp_file], check=True)
with open(temp_file, "r",encoding="utf8") as file:
jtags = file.readlines()
# 翻訳タグ数がリストのタグ数より少ない場合、翻訳タグの末尾に不足分を追加
if len(jtags) < len(self.tag_list):
jtags.extend(['']*(len(self.tag_list) - len(jtags)))
#リストの中身を書き換える
self.listbox.delete(0, tk.END)
for tag,jtag in zip(self.tag_list,jtags):
jtag = jtag.strip() # 行末の改行文字を削除
self.listbox.insert(tk.END, f"{tag} {self.tag_split_marker}({jtag})")
def clear_check(self):
'''リストのクリア'''
self.listbox.selection_clear(0, tk.END)
def shift_click_select(self, event):
'''シフト+クリック'''
try:
index = self.listbox.index("@%d,%d" % (event.x, event.y))
if self.listbox.select_includes(index):
# 既に選択済みの場合は選択を解除
self.listbox.selection_clear(index)
else:
# クリック位置から直前に選択された位置までの範囲を選択
cur_selection = self.listbox.curselection()
if cur_selection:
last_index = int(cur_selection[-1])
if last_index < index:
start_index = last_index + 1
end_index = index
else:
start_index = index
end_index = last_index - 1
self.listbox.selection_set(start_index, end_index)
else:
# 選択範囲がない場合は単一の選択とする
self.listbox.selection_clear(0, tk.END)
self.listbox.selection_set(index)
except tk.TclError:
pass
def select_folder(self):
'''フォルダ選択'''
self.folder_path = filedialog.askdirectory()
self.folder_label.config(text=self.folder_path)
if self.folder_path:
self.process_files()
def process_files(self):
'''ファイルの中身をカンマ分割してリストボックスに表示'''
self.tag_list.clear()
self.selected_tags.clear()
self.listbox.delete(0, tk.END)
file_list = self.get_file_list()
for file_path in file_list:
tags = self.read_file(file_path)
self.tag_list.extend([x.strip() for x in tags])
self.tag_list = sorted(list(set(self.tag_list)))
for tag in self.tag_list:
self.listbox.insert(tk.END, tag)
def get_file_list(self):
'''ファイル一覧の取得'''
file_list = []
for file in os.listdir(self.folder_path):
file_path = os.path.join(self.folder_path, file)
if os.path.isfile(file_path) and not file.startswith("$") and file.endswith(".txt"):
file_list.append(file_path)
return file_list
def read_file(self, file_path):
'''ファイルの読み込み'''
keywords = []
with open(file_path, "r") as file:
for line in file:
elements = line.strip().split(",")
keywords.extend(elements[1:])
return keywords
def toggle_check(self):
'''チェック反転の処理'''
if self.listbox.size() > 0:
for i in range(self.listbox.size()):
if self.listbox.selection_includes(i):
self.listbox.selection_clear(i)
else:
self.listbox.selection_set(i)
def save_files(self):
'''フォルダ内の全てのテキストファイルを更新'''
self.selected_tags = self.get_selected_tags()
if len(self.selected_tags) == 0:
messagebox.showinfo("警告", "Tagが選択されていません")
return
confirmation = messagebox.askyesno("確認", "Tagファイルの編集を実行しますか?")
if not confirmation:
return
file_list = self.get_file_list()
for file_path in file_list:
self.copy_file_to_org_folder(file_path)
self.update_file(file_path)
messagebox.showinfo("完了", "ファイルの保存が完了しました。")
def get_selected_tags(self):
'''リストボックスから選択されているタグの一覧を取得'''
return [self.listbox.get(index).split(self.tag_split_marker)[0].strip() for index in self.listbox.curselection()]
def update_file(self, file_path):
'''指定されたファイルを更新'''
with open(file_path, "r") as file:
for line in file:
tags = [x.strip() for x in line.strip().split(",")]
for tag in tags[1:]:
if tag in self.selected_tags:
tags.remove(tag)
with open(file_path, "w") as file:
file.write("".join(" ,".join(tags)))
def copy_file_to_org_folder(self,file_path):
'''直下のORGフォルダにバックアップを保存'''
folder_path = os.path.dirname(file_path)
org_folder_path = os.path.join(folder_path, "org")
if not os.path.exists(org_folder_path):
os.makedirs(org_folder_path)
file_name = os.path.basename(file_path)
org_file_path = os.path.join(org_folder_path, file_name)
shutil.copy2(file_path, org_file_path) # ファイルを"org"フォルダにコピー
app = Application()
app.mainloop()実行方法
Pythonが動作する環境で、次のコマンドを実行して下さい。
python deftag.py
ポータブル環境をお使いで、stable diffusion をインストールしたフォルダ直下の scripts フォルダに 保存されているのであれば、エクスプローラーから @CommandPrompt.bat をダブルクリックし、開いたコマンドプロンプトから上記コマンドを実行して下さい。
まとめ
今回は、stable diffusion で LoRAファイルを作成する手順について、「学習環境の構築」と「学習のさせ方」について紹介しました。
LoRA学習にはいくつかの方法がありますが、本記事では「DreamBooth、キャプション方式」を紹介しています。
そして、この「DreamBooth、キャプション方式」でLoRA学習を行わせるためのツールが Kohya-ss さんがGitHubに公開している、sd-script です。
「DreamBooth、キャプション方式」では、学習用画像1枚に対して、タグ(プロンプト)を記述したテキストファイル1つを用意する必要がありますが、学習画像からタグ(プロンプト)を自動生成するツールが Tagger です。
sd-script は コマンドプロンプト上でいくつかのコマンドを実行することでインストールを行い、Tagger は、stable diffusion web ui の extensionsタブからインストールを行います。
LoRA学習においては、コマンドプロンプトからコマンドを実行することで行うことが可能です。コマンドを実行後数十分から数時間でLoRAモデルが生成されます。
生成されたLoRAファイルを所定のフォルダにコピーし、従来通りプロンプトから <lora:~> とトリガーワードを記述し、Generateボタンをクリックすると、LoRAが適用された画像が生成されます。
一見ややこしそうですが、1つ1つ手順を追って実行すればLoRAファイルを作ることが出来ますので、みなさんも是非挑戦してみてください。



コメント