「【実践】Pythonとjanomeで感情分析しようよ!」の記事では、形態素解析器の Janome と日本語評価極性辞書を使って、文書による感情分析を行いました。
今回は、BERT という自然言語処理モデルを使った感情分析について紹介したいと思います。
今回もクラス化しているので、コピペですぐにお試し頂けるようにしていますので、興味のある方は是非ご一読ください。
BERTの概要
BERTとは、Bidirectional Encoder Representations from Transformers の頭文字を取った略称で、2018年10月に Googleの Jacob Devlin らが論文で発表した自然言語処理モデルです。
詳しい原理については難しいのでここでは割愛しますが、気になる方は Yahoo!JAPAN Tech Blog の こちら のページに記載されていますのでご一読ください。
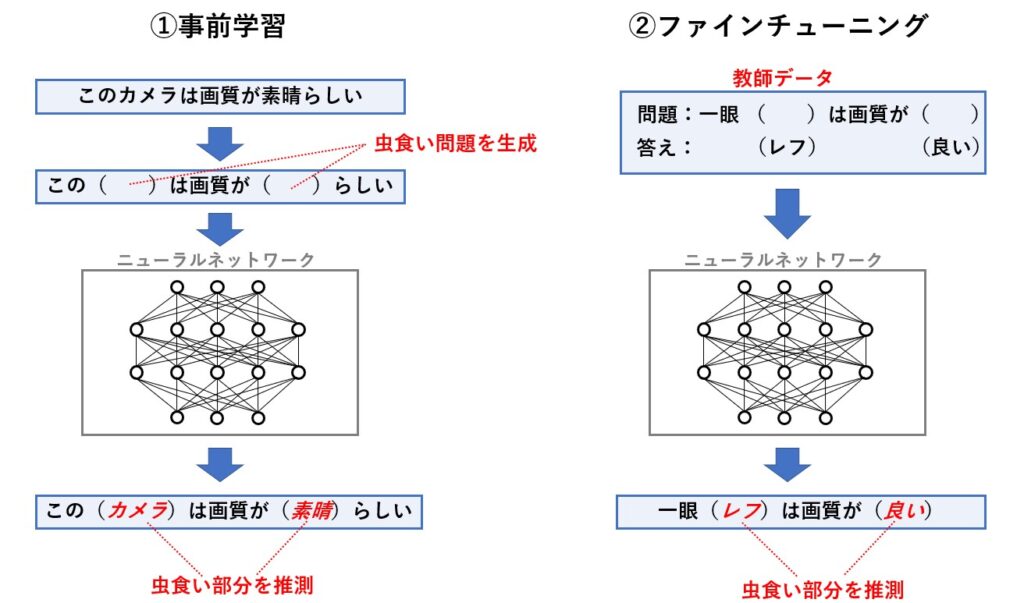
BERT はニューラルネットワークの技術が用いられており、大量の文書から大量の虫食い問題を作成し、この虫食い問題を前後の単語から推測させるというアプローチをひたすら行ってニューラルネットに学習(事前学習)させます。
そして、この学習済みニューラルネットワークに対して、実際に解きたいタスクのために用意した教師データを学習(ファインチューニング)させることで、そのタスクに対応できるモデルを生成します。
今回は、解きたいタスクが感情分析なので、感情分析用のモデルを生成することになるのですが、既に学習済みモデルが用意されているので、これを使います。
インストール方法
今回は、以下の3つのライブラリをインストールします。
- PyTorch(ニューラルネット用のライブラリ)
- torchvision (データセット、モデルアーキティクチャ、画像変換用ライブラリ)
- transformers(トレーニング済みの学習モデルのダウンロード、トレーニング用ライブラリ)
以下のコマンドでインストールして下さい。
pip install torch torchvision
pip install transformers[ja]感情分析の実行手順
手順は以下の通りです。

下記は、必要なライブラリのimportを含んだサンプルです。
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer
# 感情分析の実行
model = AutoModelForSequenceClassification.from_pretrained('kit-nlp/bert-base-japanese-sentiment-irony')
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer)
print(nlp('修理に出します。購入して1年ちょっとで壊れてしまいました。残念です。'))結果は次の様になります。
[{'label': 'ポジティブ', 'score': 0.6155223250389099}]
「購入して1年ちょっとで壊れてしまいました。残念です。修理に出します。」は、人間が読むとネガティブな印象を受けますが、結果はポジティブに分類されています。
この文書は、ネガティブとポジティブの単語が同時に含まれている例なので、ネガティブの判定を出した要因を探るため、ネガティブとポジティブの位置を反転させたものと、短文に区切ったものを用意して、判定してみました。
| 文章 | 判定結果 |
|---|---|
| 購入して1年ちょっとで壊れてしまいました。残念です。修理に出します。 | [{'label': 'ポジティブ', 'score': 0.7012038826942444}] |
| 修理に出します。購入して1年ちょっとで壊れてしまいました。残念です。 | [{'label': 'ポジティブ', 'score': 0.6155223250389099}] |
| 購入して1年ちょっとで壊れてしまいました | [{'label': 'ポジティブ', 'score': 0.5462110638618469}] |
| 残念です。 | [{'label': 'ネガティブ', 'score': 0.8505648374557495}] |
| 修理に出します。 | [{'label': 'ポジティブ', 'score': 0.9535529017448425}] |
この結果だけを見ると、最後に登場する単語の判定結果が、文書全体の判定に影響するのかもしれません。
感情分析クラスについて
では、さっそく自作した感情分析クラスの概要、リファレンス、ソースコードの順に紹介していきたいと思います。
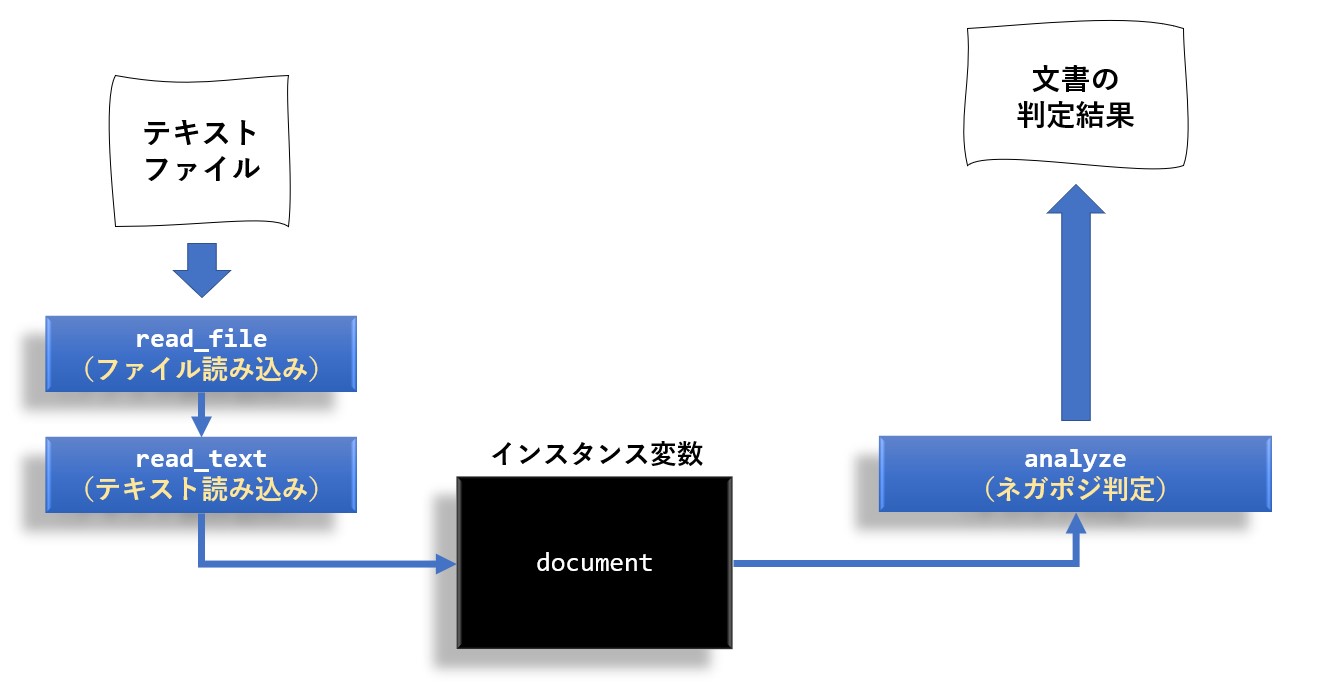
クラスの概要
クラス名は 前回と同じく、SentimentAnalysis にしました。
また、クラスの構造も前回と合わせたので、以下の様になっています。
リファレンス
メソッドはコンストラクタ含めて4つです。
| 機能 | メソッド仕様 | 戻り値 |
|---|---|---|
| コンストラクタ | __init__( dic_path #日本語評価極性辞書のフルパス ) | |
| ファイルの読み込み | read_file( filename, #入力ファイル名 encoding='utf-8' #エンコード名 ) | なし |
| テキストの読み込み | read_text( text #入力テキスト ) | なし |
| 感情分析の実行 | analyze( text = None #入力テキスト ) | { 'label':判定結果, #ネガポジ判定 'score':スコア #判定結果のスコア } |
今回は、 read_text や read_file を使わなくても analyze の引数にテキストを直接渡して処理できるようにしました。
analyze メソッドの戻り値
analyze メソッドの戻り値 は 辞書形式になっていて、label と score のキーを持っています。
例:{'label': 'ポジティブ', 'score': 0.9712414145469666}
使い方
使い方は2通りあって、次の順番にメソッドを呼ぶだけでOKです。

以下に実際のサンプルを掲載しておきます。
#--------------------------------------------------------------------------------
# ここに後述するSentimentAnalysisのソースコードを張り付けて実行して下さい。
#--------------------------------------------------------------------------------
sa = SentimentAnalysis()
lines = [
'やはり1型のセンサーは素晴らしい画質です。スマホとは比べ物になりません。',
'悩んで購入しましたが、高いわりに画質がイマイチでした。後悔しています。',
'小型軽量で電池も長持ちするし、お勧めできる製品です。',
'購入して1年ちょっとで壊れてしまいました。残念です。修理に出します。',
'このサイズでAPC-Cセンサー搭載とは驚きです。値段は少し高めですが、満足です'
]
for line in lines:
print(line)
print(sa.analyze(line))
print("////////")実行結果は次の様になりました。
やはり1型のセンサーは素晴らしい画質です。スマホとは比べ物になりません。
[{'label': 'ポジティブ', 'score': 0.6981086134910583}]
////////
悩んで購入しましたが、高いわりに画質がイマイチでした。後悔しています。
[{'label': 'ネガティブ', 'score': 0.6179606318473816}]
////////
小型軽量で電池も長持ちするし、お勧めできる製品です。
[{'label': 'ポジティブ', 'score': 0.7786630392074585}]
////////
購入して1年ちょっとで壊れてしまいました。残念です。修理に出します。
[{'label': 'ポジティブ', 'score': 0.7012038826942444}]
////////
このサイズでAPC-Cセンサー搭載とは驚きです。値段は少し高めですが、満足です
[{'label': 'ネガティブ', 'score': 0.6620423793792725}]
////////
簡単な文書ですが、全てがポジティブに分類されてしまいました。
「悩んで購入しましたが、高いわりに画質がイマイチでした。後悔しています。」はどう考えてもネガティブだと思うのですが、文書を短く区切って判定させたところ、「後悔しています」がポジティブに判定されたことが分かりました。
そこで、「後悔しています。悩んで購入しましたが、高いわりに画質がイマイチでした。」という文書に変えて判定させたところ、見事にネガティブ判定が出ました。
後悔しています。悩んで購入しましたが、高いわりに画質がイマイチでした。
[{'label': 'ネガティブ', 'score': 0.7478147745132446}]
////////
やはり、文書の最後に出てくる単語の判定結果が効いているようです。
ソースコード
最後に、クラスの全ソースコードを紹介しておきます。
from transformers import pipeline, AutoModelForSequenceClassification, BertJapaneseTokenizer
import codecs
class SentimentAnalysis:
def __init__(self):
"""
コンストラクタ
"""
model = AutoModelForSequenceClassification.from_pretrained('kit-nlp/bert-base-japanese-sentiment-irony') tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
self.nlp = pipeline("sentiment-analysis",model=model,tokenizer=tokenizer)
self.document = None
def analyze(self,text = None):
'''
感情分析
Returns:
--------
{'label':str,'score':float} ネガポジの結果と確率を辞書形式で返す
'''
return self.nlp(self.document if text is None else text)
def read_file(self,filename,encoding='utf-8'):
'''
ファイルの読み込み
Parameters:
--------
filename : str 分析対象のファイル名
'''
with codecs.open(filename,'r',encoding,'ignore') as f:
self.read_text(f.read())
def read_text(self,text):
'''
テキストの読み込み
Parameters:
--------
text : str 分析対象のテキスト
'''
# 形態素解析を用いて名詞のリストを作成
self.document = textまとめ
今回はBERTというニューラルネットワークを使った自然言語処理モデルを用いて、感情分析を行ってみました。
Janome と日本語評価極性辞書を使った感情分析と比べると、BERTを使った方が起動時に十数秒待たされる文、遅く感じてしまいます。
また、口コミを判定する場合においては、「【実践】Pythonとjanomeで感情分析しようよ!」の方が成績が良かったような気もします。
ただ、辞書に左右されることなく感情分析が出来るところはメリットです。
口コミなどの短い文書の場合、最後に登場する単語の判定結果に強い影響を受けていそうですが、大量の口コミから全体の傾向を判定するような場合は、それほど問題にならないでしょう。
とりあえずBERTを使った「感情分析」を手軽に試してみたいという方は、ソースコードをコピペして試していただければと思います。
この記事が皆様のお役に立てば幸いです。





コメント