前回はTF-IDFを使った文書の特徴抽出について紹介しましたが、今回は Python を使った文書の感情分析について、その方法をご紹介したいと思います。
今回もクラス化しているので、コピペですぐにお試しいただけます。
さっと試してみたいという方は、是非この記事をご一読ください。
感情分析の概要
「感情分析」とは、顔の表情、声のトーン、文書などの情報の中から、どのような感情が含まれているかを分析するものです。
この記事では、文書を使った「感情分析」のみに限定していますが、それでも数多くの手法(アルゴリズム)が存在します。
そこで今回は、東北大学の乾・鈴木研究室の「日本語評価極性辞書」を使ったシンプルな方法を使います。
具体的には、文書に対して形態素解析を実行し、取り出したキーワード(単語)と日本語評価属性辞書を突き合わせ、ネガポジ判定(e:ニュートラル,p:ポジティブ,n:ネガティブ) を行うだけです。
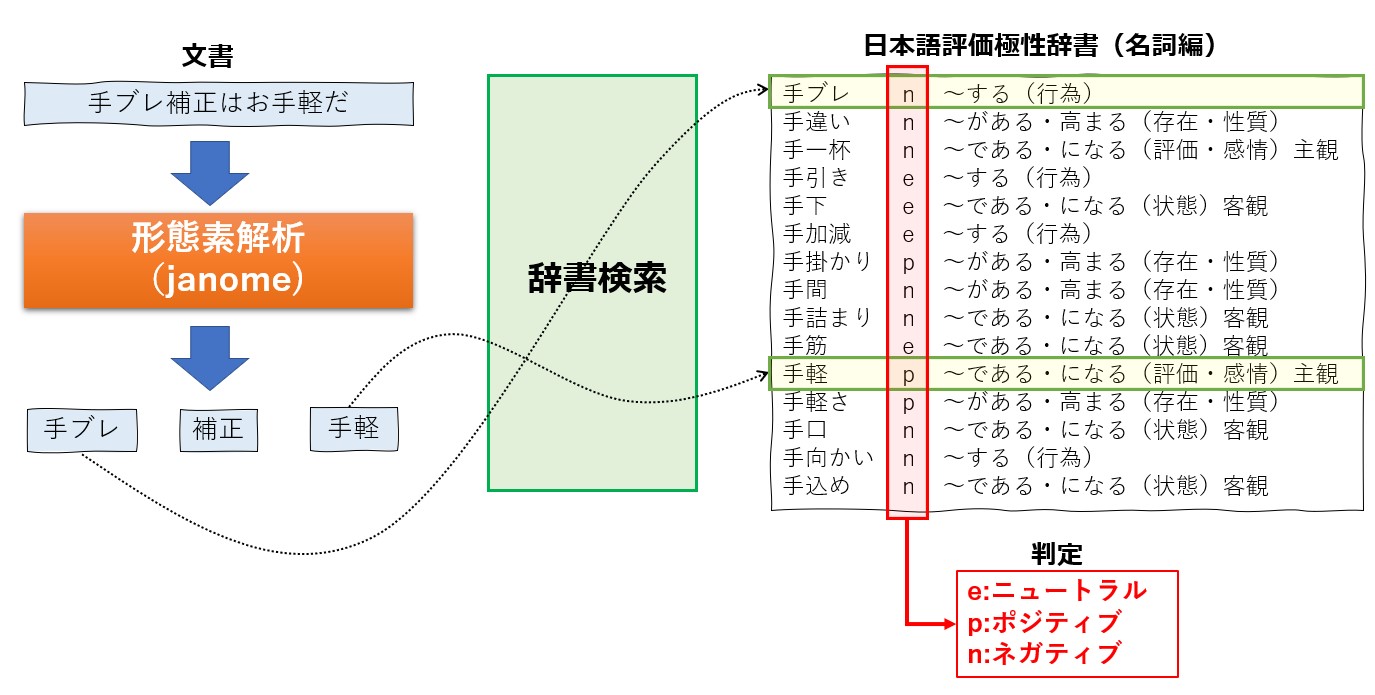
日本語評価属性辞書には「用語編」と「名詞編」がありますが、ここでは「名詞編」を利用します
ちなみに、日本語評価属性辞書(用語編)には約13000個ものキーワードが登録されています。
辞書に存在しない単語は感情の評価がされないという課題はありますが、辞書のフォーマットは単純でで追加が容易なため、ニューラルネット等を使った方法に比べて、結果をコントロールしやすいといったメリットもあります。
インストール方法
形態素解析は何でもいいのですが、Mecab よりも簡単に導入が可能な janome を使います。
Janomeのインストールは以下の通りです。
pip install janome
次に、辞書を入手しましょう。
こちらの公式サイトからダウンロードして下さい。
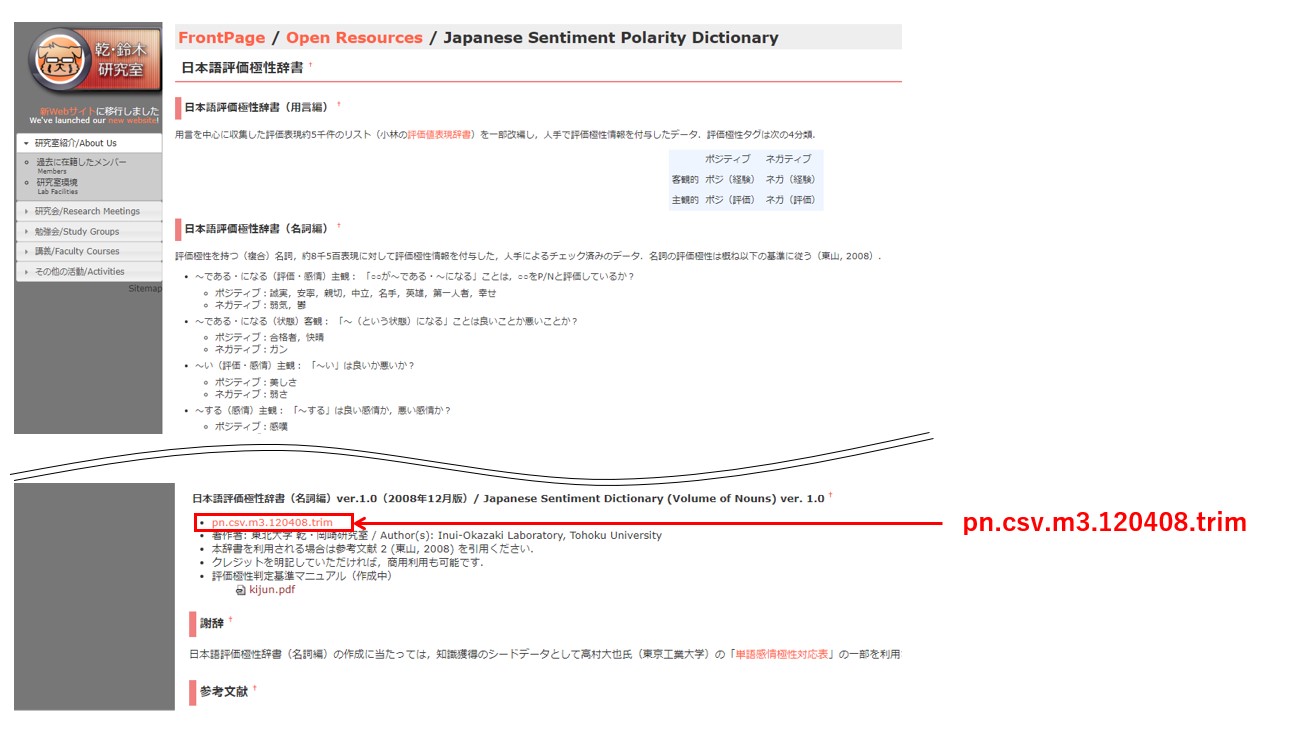
表示されるページを少しスクロールすると「日本語評価極性辞書(名詞編)ver.1.0」というタイトルが見つかりますので、pn.csv.m3.120408.trim のリンクをクリックするとダウンロードできます。
ファイルは圧縮されていませんので、そのまま使うことが出来ます。
任意のフォルダに保存したら、そのフルパスは後で使うので記録しておいてください。
感情分析の実行手順
以下の手順になります。
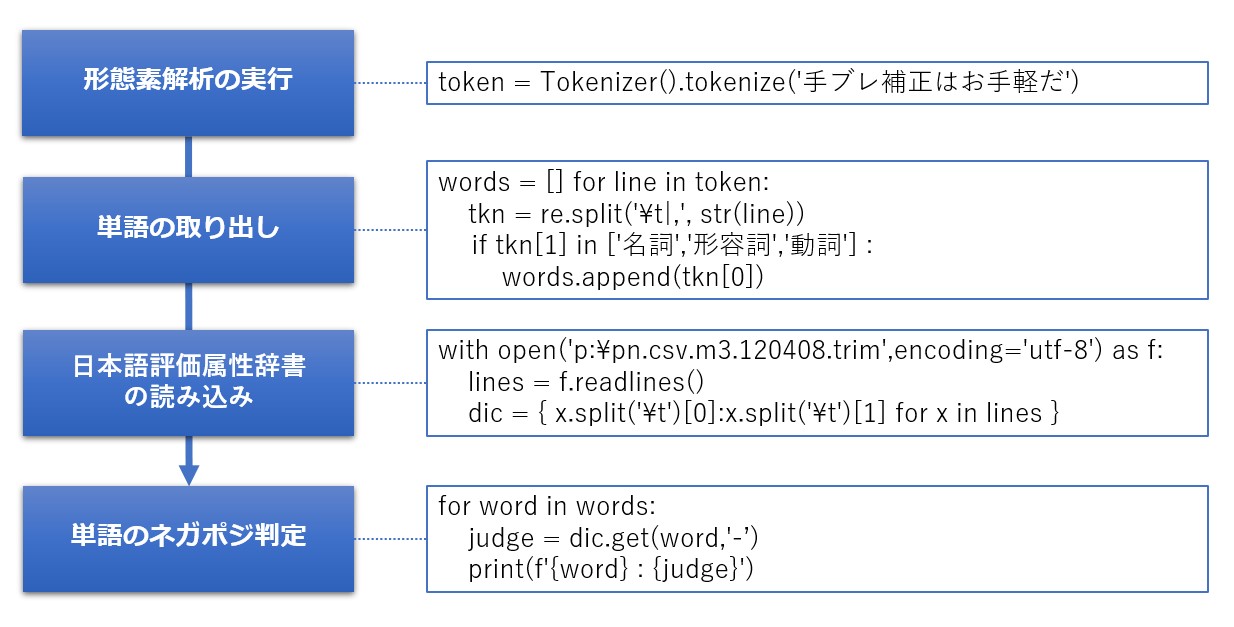
下記は、必要なライブラリのimportを含んだサンプルです。
from janome.tokenizer import Tokenizer
import re
#形態素解析の実行
token = Tokenizer().tokenize('手ブレ補正はお手軽だ')
#単語の取り出し
words = []
for line in token:
tkn = re.split('\t|,', str(line))
# 名詞、形容詞、動詞で判定
if tkn[1] in ['名詞','形容詞','動詞'] :
words.append(tkn[0])
#日本語評価極性辞書(名詞編)の読み込み
with open('p:\pn.csv.m3.120408.trim',encoding='utf-8') as f:
lines = f.readlines()
dic = { x.split('\t')[0]:x.split('\t')[1] for x in lines }
#単語のネガポジ判定
for word in words:
judge = dic.get(word,'-')
print(f'{word} : {judge}')結果は次の様になります。

janome標準の辞書では、手ブレが「手」と「ブレ」に分割されてしまいますので、更なる精度を求めるのであれば、別途辞書を登録するか、Neologd などの辞書を使うなどの対策は必要かと思います。
感情分析クラスについて
では、さっそく自作した感情分析クラスの概要、リファレンス、ソースコードの順に紹介していきたいと思います。
クラスの概要
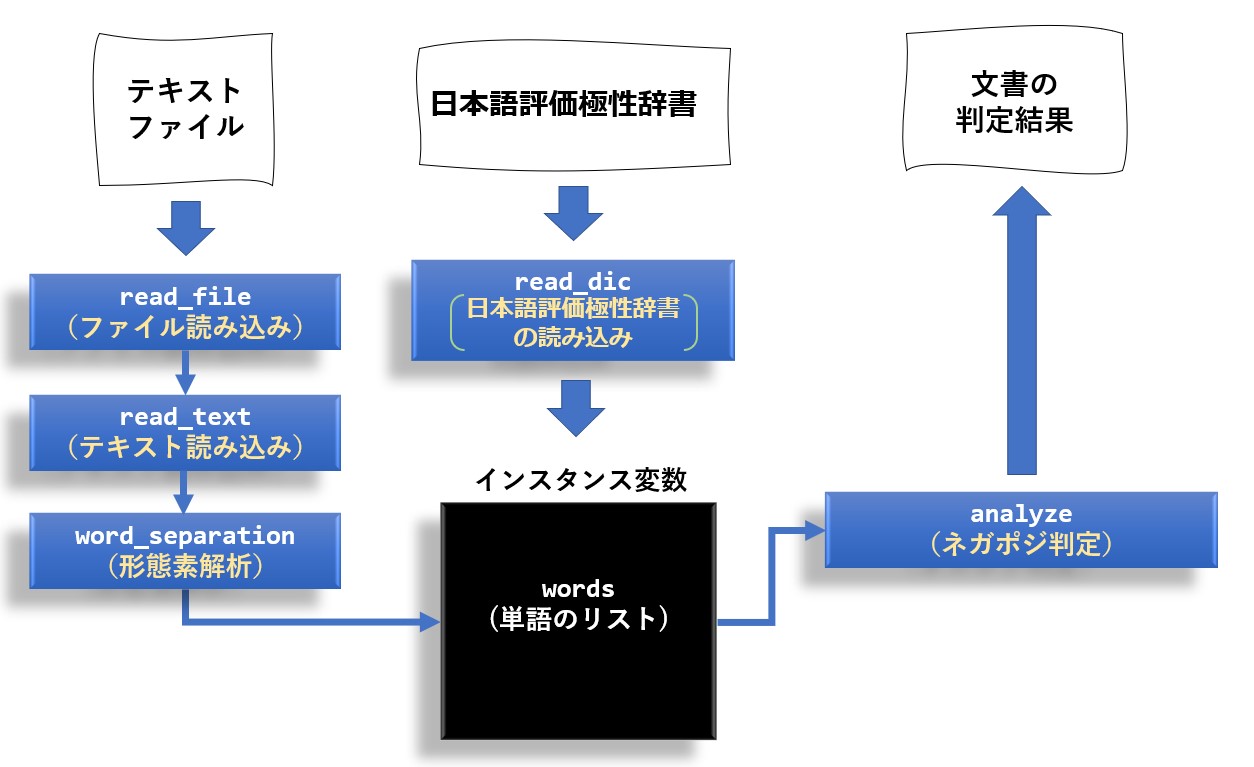
クラス名は SentimentAnalysis にしました。
まず最初に、先ほどダウンロードした日本語評価極性辞書のフルパスをコンストラクタの引数に渡します。
後は、read_file 又は read_text メソッドで文書を指定し、analyze メソッドを呼ぶだけで感情分析が行えます。
クラスの構造は以下の様になっています。
リファレンス
メソッドは次の5つだけです。
| 機能 | メソッド仕様 | 戻り値 |
|---|---|---|
| コンストラクタ | __init__( dic_path #日本語評価極性辞書のフルパス ) | |
| ファイルの読み込み | read_file( filename, #入力ファイル名 encoding='utf-8' #エンコード名 ) | なし |
| テキストの読み込み | read_text( text #入力テキスト ) | なし |
| 感情分析の実行 | analyze() | posi, #ポジティブ単語の個数 nega,#ネガティブ単語の個数 neut,#ニュートラル単語の個数 err #判定できなかった単語の個数 |
| 単語の抽出 (形態素解析) | word_separation( text #入力テキスト ) | 抽出された単語のリスト ['aaa','bbb','ccc', ・・・] |
analyze メソッドの戻り値
analyze メソッドの戻り値 は4個の要素を持つタプル形式となり、左から順にポジティブ単語の個数、ネガティブ単語の個数、ニュートラル単語の個数、判定できなかった単語(辞書に登録されていなかった単語)の個数が並びます。

インプットとなる文書全体のポジティブ度、ネガティブ度を判定したい場合は、ポジティブ単語の個数とネガティブ単語の個数の差、もしくは比率を求めて判定して下さい。
使い方
使い方は非常に簡単で、次の順番にメソッドを呼ぶだけです。
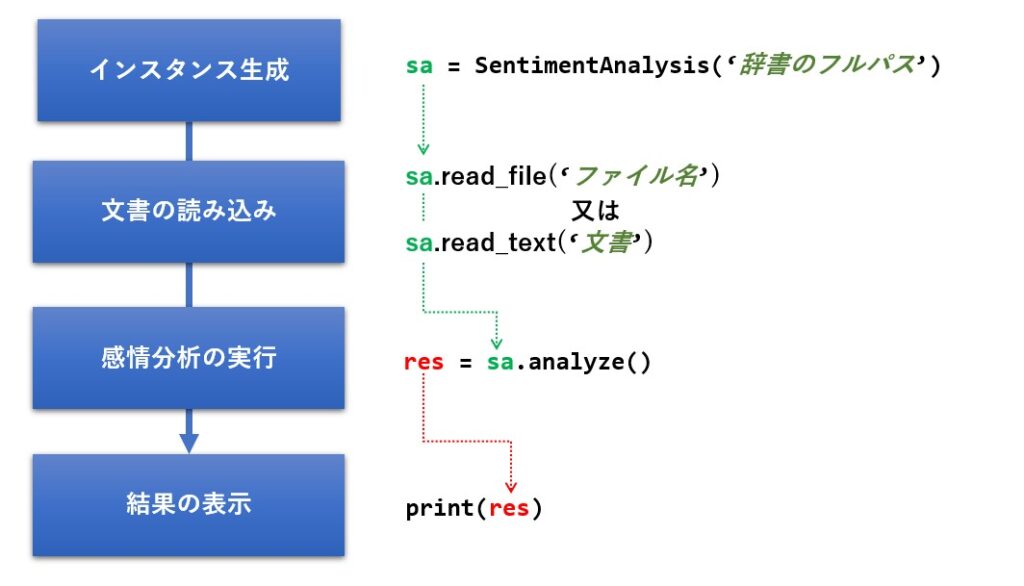
以下に実際のサンプルを掲載しておきます。
検証で使ったPCが Windows11 マシンであり、辞書を p ドライブ直下に置いていましたので、インスタンスの引数に 'p:/pn.csv.m3.120408.trim' を指定しています。
# インスタンスの生成
sa = SentimentAnalysis('p:/pn.csv.m3.120408.trim')
# 感情分析したい文章
lines = [
'やはり1型のセンサーは素晴らしい画質です。スマホとは比べ物になりません。',
'悩んで購入しましたが、高いわりに画質がイマイチでした。後悔しています。',
'小型軽量で電池も長持ちするし、お勧めできる製品です。',
'購入して1年ちょっとで壊れてしまいました。残念です。修理に出します。',
'このサイズでAPC-Cセンサー搭載とは驚きです。値段は少し高めですが、満足です'
]
#1行ずつ読んで分析する
for line in lines:
print(line) # 元の文書を表示
sa.read_text(line) # 文書の読み込み
res = sa.analyze() # 感情分析の実行
print(res) # 結果の表示
print("-----------")実行結果は次の様になりました。

簡単な文書ですが、だいたい思った通りの結果になっているように思います。
文書に含まれるポジティブの単語数とネガティブの単語数をカウントしているだけなので、文書量がどれだけ多くなろうと、句読点が少ない長文になっていようと、感情分析は可能です。
もちろん辞書に含まれていない単語が多用されていたり、「画質が綺麗ではない」などの否定表現が多い場合は分析精度が低下するかと思いますが、文書全体の傾向はつかめるのではないかと思います。
ソースコード
最後に、クラスの全ソースコードを紹介しておきます。
from janome.tokenizer import Tokenizer
import re
import codecs
class SentimentAnalysis:
def __init__(self,dic_path):
"""
コンストラクタ
"""
self.words = []
self.dic = self.read_dic(dic_path)
def analyze(self):
'''
感情分析
Returns:
--------
(int,int,int,int) ポジティブ数、ネガティブ数、ニュートラル数、判定不可数
'''
posi = 0
nega = 0
neut = 0
err = 0
for word in self.words:
res = self.dic.get(word,'-')
if res == 'p':
posi += 1
elif res == 'n':
nega += 1
elif res == 'e':
neut += 1
else:
err += 1
return posi,nega,neut,err
def word_separation(self,text):
"""
形態素解析により名詞、形容詞、動詞を抽出
---------------
Parameters:
text : str テキスト
"""
token = Tokenizer().tokenize(text)
words = []
for line in token:
tkn = re.split('\t|,', str(line))
# 名詞、形容詞、動詞で判定
if tkn[1] in ['名詞','形容詞','動詞'] :
words.append(tkn[0])
return words
def read_dic(self,filename):
with codecs.open(filename,'r','utf-8','ignore') as f:
lines = f.readlines()
dic = { x.split('\t')[0]:x.split('\t')[1] for x in lines }
return dic
def read_file(self,filename,encoding='utf-8'):
'''
ファイルの読み込み
Parameters:
--------
filename : str 分析対象のファイル名
'''
with codecs.open(filename,'r',encoding,'ignore') as f:
self.read_text(f.read())
def read_text(self,text):
'''
テキストの読み込み
Parameters:
--------
text : str 分析対象のテキスト
'''
# 形態素解析を用いて名詞のリストを作成
self.words = self.word_separation(text)まとめ
今回は形態素解析と日本語評価極性辞書を使った「感情分析」について紹介致しました。
文書から単語を取り出して辞書と付き合わせるだけの単純な方法ですが、文書全体のおおよその傾向はつかめるのではないかと思います。
更なる精度を求めるのなら、辞書を改善したり、否定表現に対応するなどの対策は必要ですが、まずは「感情分析」を手軽に試してみたいという方は、是非ソースコードをコピペして試していただければと思います。
この記事が皆様のお役に立てば幸いです。








コメント