python には、数値計算用のパッケージとして、pandas と numpy があります。
この2つは機能が被っているので、Pythonを始めた方にとって両者の違いがわからないのではないかと思います。
また、Pythonを使っている方にとっても、pandas は遅いという評価はあるものの、実際にどれくらいの速度差があるかについて、なかなか把握しきれていないのではないでしょうか。
今回は、CSVデータを集計するという観点から、処理時間(処理速度)の違いを調べてみましたので、その結果を掲載させていただきます。
pandas と numpy の関係は?
pandas と numpy は、共に1次元配列、2次元配列、多次元配列のデータを集計するためのライブラリです。
pandas は DataFrame と呼ばれるデータフォーマットでデータを管理し、そのデータに対して様々な数値計算や、欠損値補間が行える他、EXCELやCSVの読み書き、グラフ描画機能など数値計算以外の機能も網羅しています。
一方、numpy は ndarray と呼ばれるデータフォーマットでデータを管理し、数値演算を高速に処理できるように作られています。
そして、pandas の多くの機能の中で数値演算が必要な時、pandas が numpy を呼び出して数値計算させるという連携を行っています。
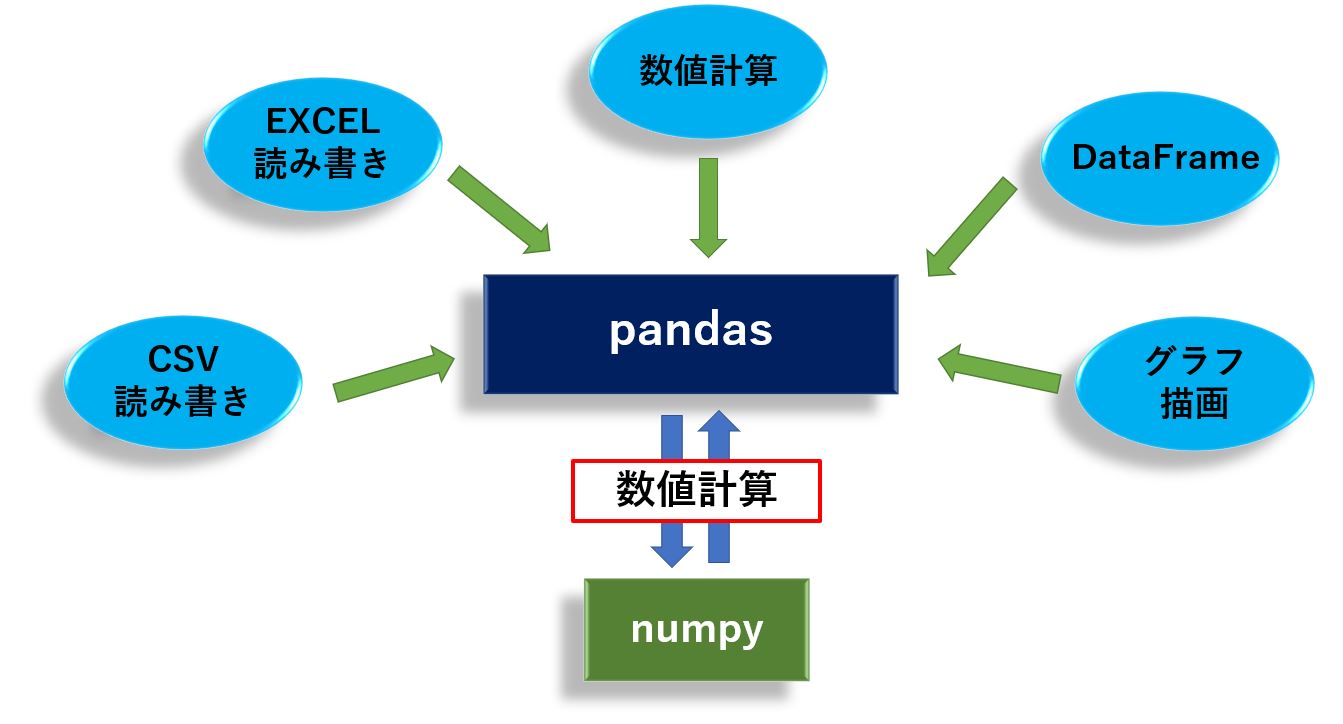
両者を自動車に例えると、pandas が自動車そのもので、numpy がエンジンに相当します。
pandas について詳しい情報が知りたい方は、こちらの記事を、numpy に関して詳しい情報が知りたい方は、こちらの記事をご一読ください。
計測に使ったデータ
それでは、計測した内容、計測に使ったデータ、計測に使ったPCについて紹介しておきます。
計測内容
今回は次の4点について計測しました。
| データの読み込み | pandas.DataFrame() 、numpy.array() を使って データを内部形式に読み込ませた時の処理時間 |
| 全データの合計計算 | 全データに対して合計計算(sum) を行った場合の処理時間 |
| CSV読み込み | pandas.read_csv()、numpy.loadtxt() を使ってCSVファイルを 読み込ませた場合の処理時間 |
| CSV読み込み及び合計計算 | pandas.read_csv()、numpy.loadtxt() でCSVファイルを読み込み、 sum() で合計計算をさせた場合の処理時間 |
「データの読み込み」、「全データの合計計算」で使った配列データ
1次元は単純な10万要素の配列データであるのに対し、2次元1行10万列は、リストの中に1次元配列を1行だけ格納したデータです。
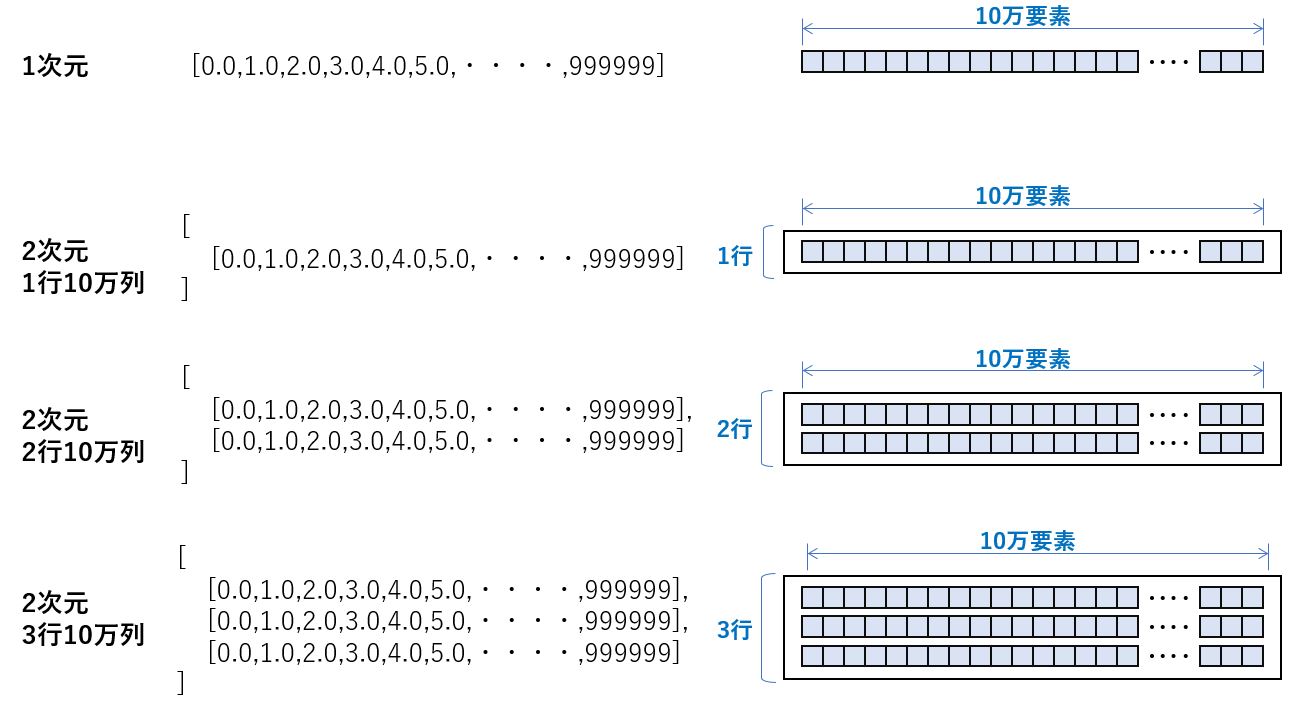
data = [x * 1.0 for x in range(100000)]
df = pd.DataFrame(data)
df = pd.DataFrame([data])
df = pd.DataFrame([data,data])
df = pd.DataFrame([data,data,data])
ar = np.array(data)
ar = np.array([data])
ar = np.array([data,data])
ar = np.array([data,data,data])上記のデータでは pandas の速度が極めて遅くなったため、pandas については 下記の様に data を縦方向に追加したデータについても速度評価しました。
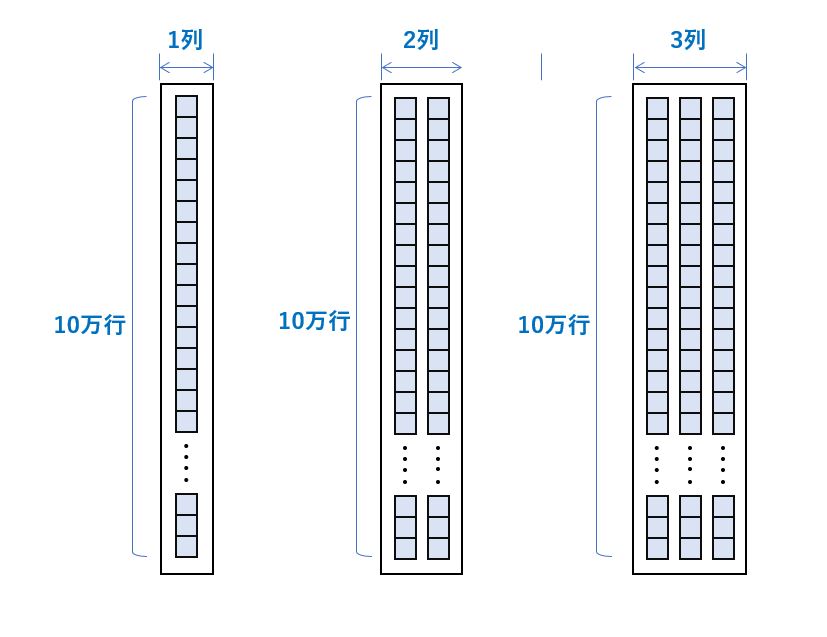
data = [x * 1.0 for x in range(100000)]
df = pd.DataFrame(data)
df = pd.DataFrame([{'a':data}])
df = pd.DataFrame({'a':data,'b':data})
df = pd.DataFrame({'a':data,'b':data,'c':data})上から1つ目(1次元)と2つ目(2次元1行10万列)の違いは、同じ10万個のデータであっても、1次元としてそのまま使う方法(pd.DataFrame(data))と、リストに格納して使う方法(pd.DataFrame([data])の差です。
同じデータ個数であっても、データの持ち方で差が出るのかを検証するために用意しました。
「CSV読み込み」、 「CSV読み込み及び合計計算」で使ったCSVデータ
こちらは以下のようなCSVを用意し、行数は1万行を固定で、列数を200列、500列、1000列に増やして計測を行いました。
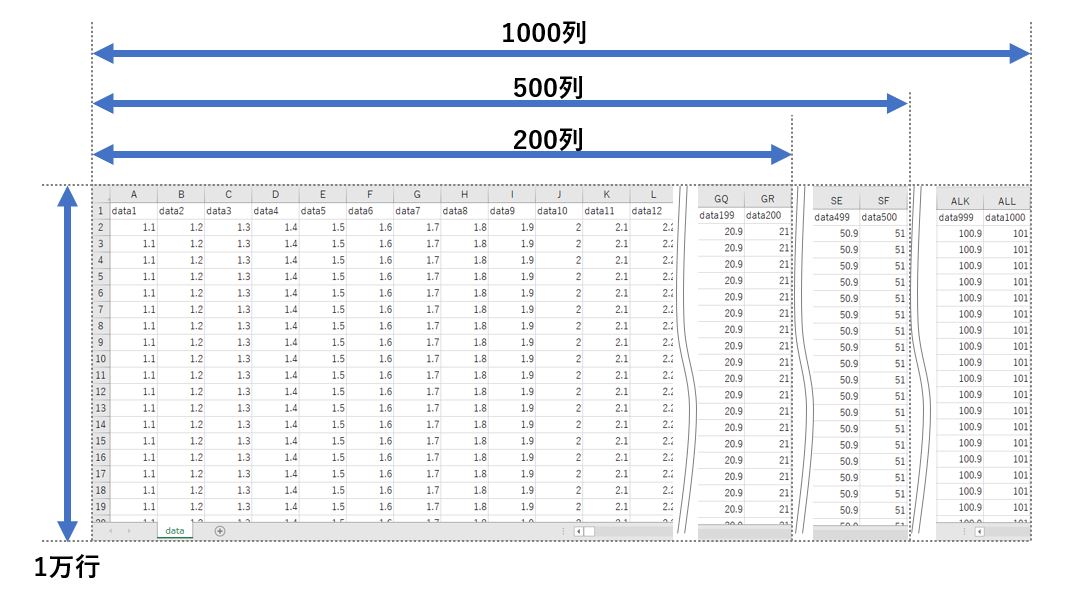
計測したPCと計測方法
今回は以下のスペックのPCを使いました。
| 項目 | 内容 |
|---|---|
| OS | Windows 10 Pro 20H2 |
| CPU | Intel(R) Core(TM) i5-9400 (6コア6スレッド)2.90GHz |
| メモリ | 32.0 GB |
| SSD | PLEXTOR PX-512M9PeG 512.1 GB(読み込み速度:3200 MB/s) |
計測した数値は10回の平均を掲載しています。
パソコンの性能により処理時間に差がでますので、掲載した結果は pandas と numpy は何倍違うのかという観点で見ていただく方が良いかと思います。
pandas と numpy の 速度比較(総評)
次の4つについて評価しました。
計測結果から、次の事が言えます。
- numpy の方が数倍~十数倍ほど処理速度が速い
- pandas は列数が多いと著しく処理速度が低下する
- CSV読み込みはpandas の方が数倍高速に処理できる
- CSVファイルを読み込んで計算する場合は、pandas で読んで numpy で計算させるのが良い
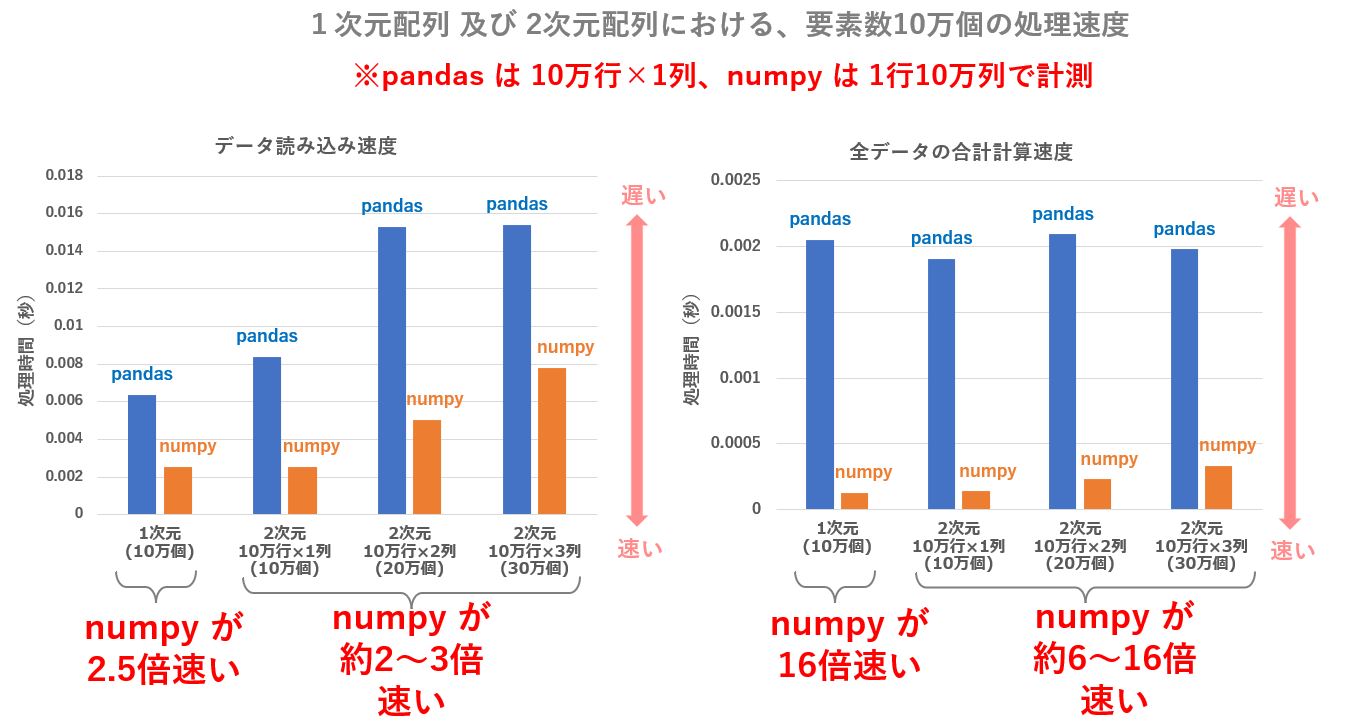
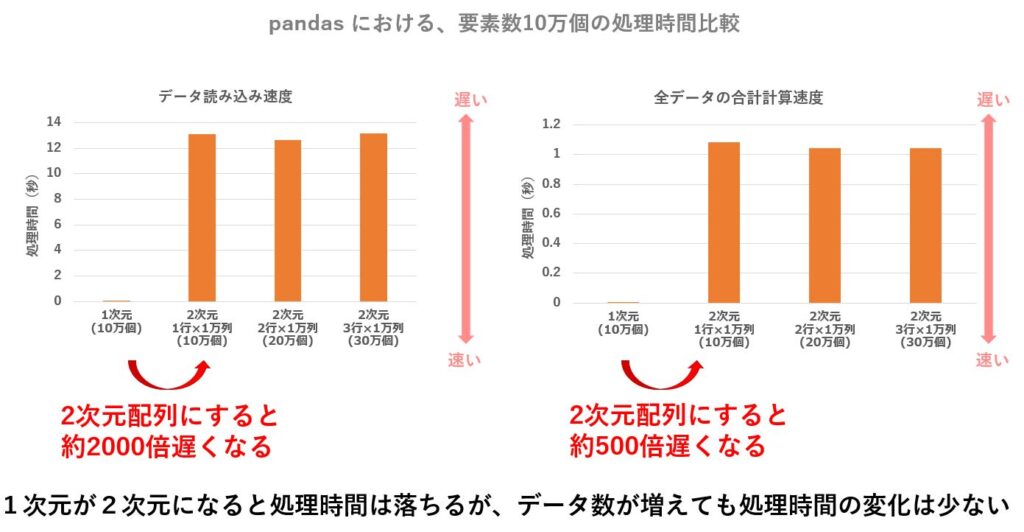
まず、単純な10万個の配列、及び1行10万列、2行10万列、3行10万列の2次元配列について、データ読み込みと合計計算の処理時間を計測したところ、2次元配列においては pandas の速度低下が著しく、numpy の方が数千倍も高速になるという結果になりました。

同じデータ数ですが、pandasに与えるデータについては列を行に展開し、10万行1列、10万行2列、10万行3列のデータで試したところ、大幅な速度改善が出来ました。
しかし、やはり numpy の方が数倍~十数倍ほど高速に処理されていました。
一方、CSV読み込みは pandas の read_csv() が高速です。
合計計算に比べてCSV読み込みの方が圧倒的に時間が掛かるので、CSVファイルを頻繁に読み込んで計算させるような場合は、numpy の loadtxt は使うべきではありません。
CSVファイルを読み込んで何らかの計算を行う場合、read_csv() で読み込んだ後、 values を使って ndarray に変換してから numpy で計算させる方法が一番処理効率が良かったです。
計測の詳細
ここからは、個々の計測結果について、実際の計測結果とグラフで詳しく見ていきたいと思います。
「データの読み込み」「 全データの合計計算 」 の計測結果詳細
pandas においては、列数が多いと速度低下が著しいので、pandas では列数を少なくしたほうが無難です。
もともと DataFrame はカラム名(列名)が使える仕様なので、列が増えることでカラム名を管理するための内部処理のオーバーヘッドが目立つのだと思われます。
例えばCSVファイルを読み込んで計算するなど、pandas は一覧形式のデータを扱うケースが多いと思います。
一般のCSVファイルだと問題になることは無いとは思いますが、CSVから複数列を抽出して pandas に格納する際、誤って列数が多くなる可能性はあるので、もし速度低下が見つかった場合は、この点もチェックしておいた方が良いかもしれません。
| 1次元 (10万個) | 2次元 [1行×10万列] (10万個) | 2次元 [2行×10万列] (20万個) | 2次元 [3行×10万列] (30万個) | |
|---|---|---|---|---|
| データの読み込み | 0.00662 | 13.1315 | 12.6588 | 13.1581 |
| 全データの合計計算 | 0.00205 | 1.0833 | 1.04327 | 1.04327 |
同じデータ数ですも、列数を行数に展開して pandas に与えると、処理速度の低下はあまりお発生しません。
列数が少なくなることで、カラムの管理に関するオーバーヘッドが少なくなるからなのでしょう。
深層学習(ディープラーニング)はともかく、一般的な利用用途では pandas でも十分高速なので、numpy は使わなくても事足りると思われます。
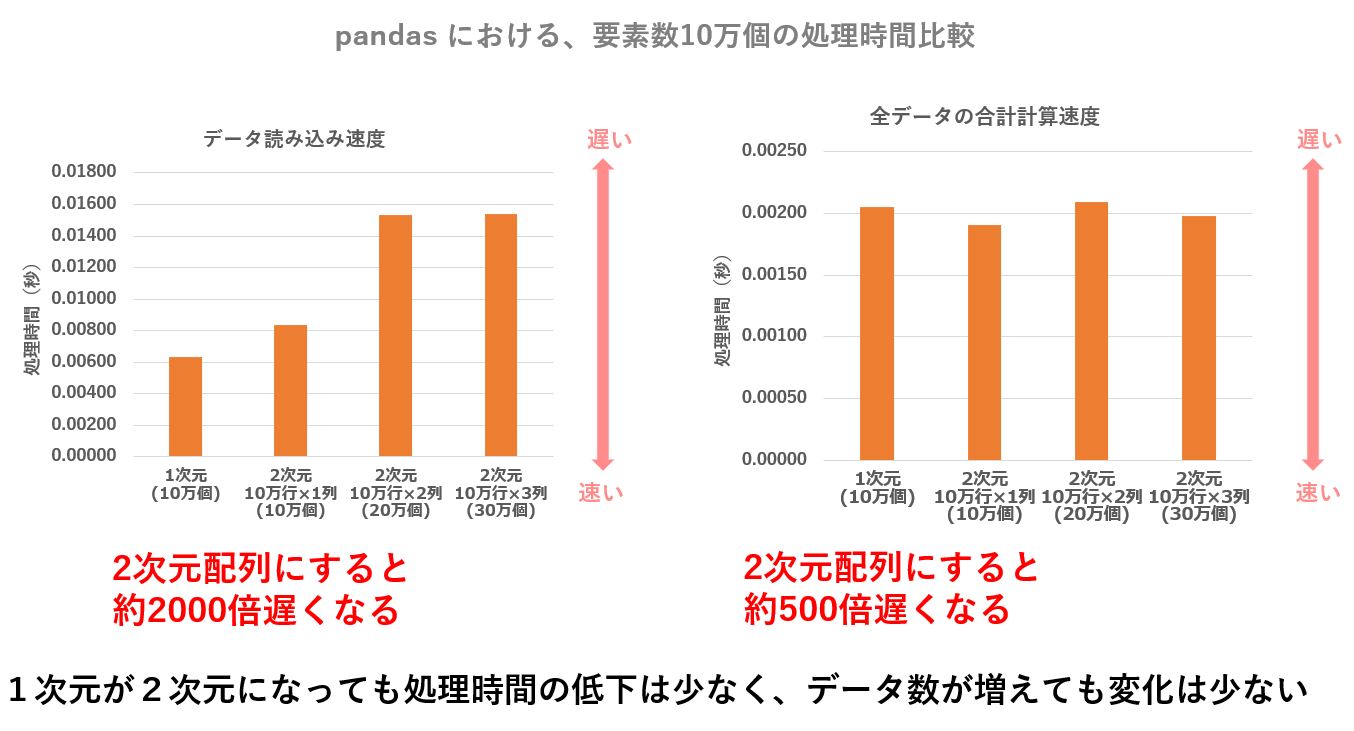
| 1次元 (10万個) | 2次元 [ 10万2行×1万列] (10万個) | 2次元 [ 10万行×2万列] (20万個) | 2次元 [ 10万行×3万列] (30万個) | |
|---|---|---|---|---|
| データの読み込み | 0.00662 | 0.00839 | 0.01531 | 0.01540 |
| 全データの合計計算 | 0.00205 | 0.00191 | 0.00209 | 0.00198 |
一方、numpy については、列数が多くても高速に処理してくれます。
numpy にはカラム名(列名)が存在せず、単に縦と横の2次元配列を処理するだけの話なので、横方向(列数)が増えても処理時間はあまり関係ないのでしょう。
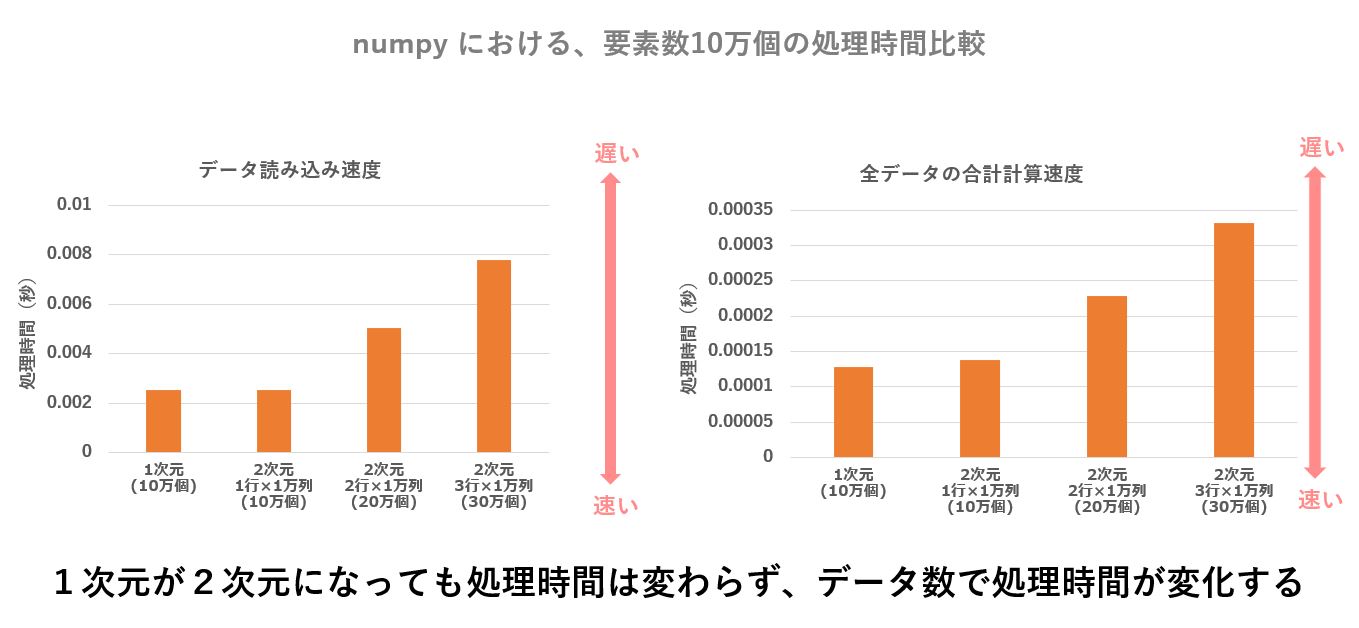
| 1次元 (10万個) | 2次元[1行×10万列] (10万個) | 2次元[2行×10万列] (20万個) | 2次元[3行×10万列] (30万個) | |
|---|---|---|---|---|
| データの読み込み | 0.00252 | 0.00252 | 0.00505 | 0.00778 |
| 全データの合計計算 | 0.00013 | 0.00014 | 0.00023 | 0.00033 |
CSV読み込み
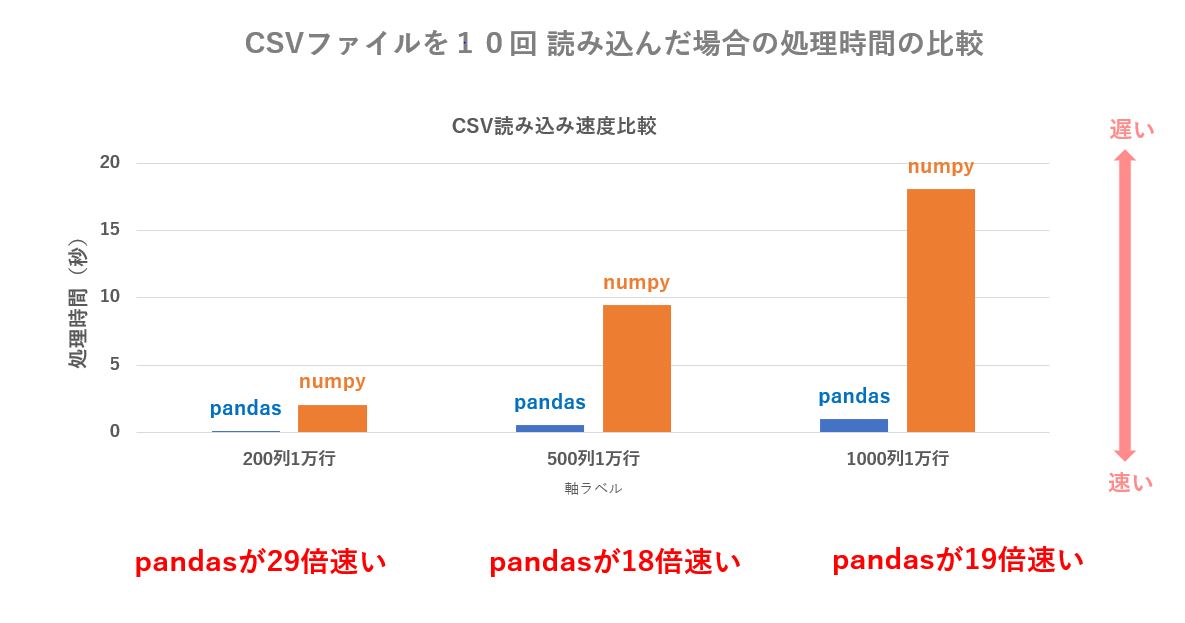
CSV読み込みに関しては、pandas の read_csv() が numpy に比べて18倍以上高速に読み込めました。
下記は10回読み込んだ場合のトータル秒数なので、10で割ると1回当たりの処理時間が算出できます。
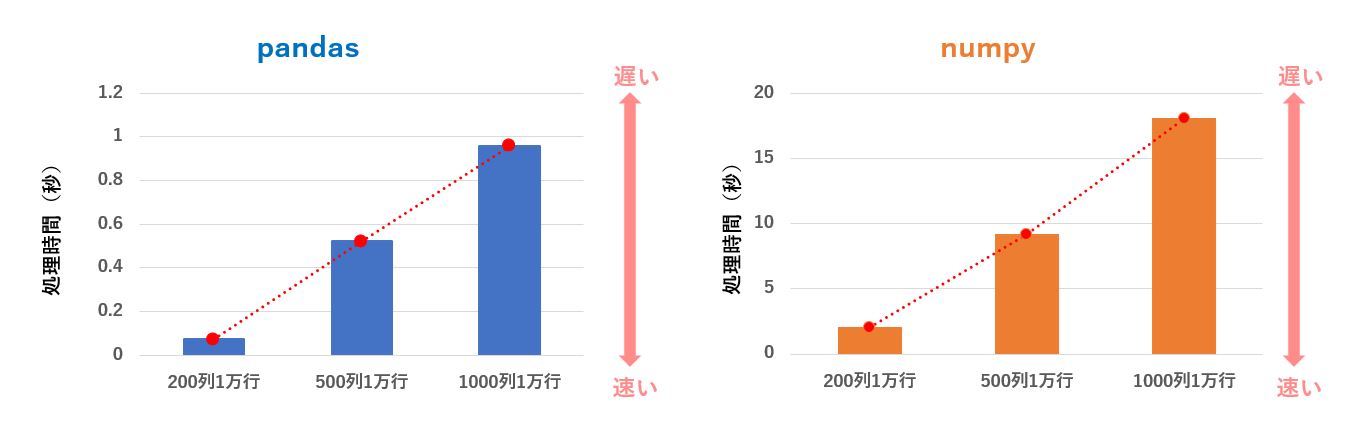
私の環境では、pandas の場合は 1000列1万CSVデータを0.1秒程度で読み込むことが出来ます。
一方、numpy では 1.8秒ほど掛かりますので、loadtext() は 19.1倍遅いことになります。
数千ファイルのCSVを扱うような場合はCSVを読み込むだけで30分や1時間消費されてしまいますので、loadtext() を使う場合は数ファイル程度の場合に限った方が良さそうです。

| 200列1万行 のCSV を読み込む時間 | 500列1万行のCSV を読み込む時間 | 1000列1万行 のCSV を 読み込む時間 | |
|---|---|---|---|
| pandas | 0.06971162 | 0.51938532 | 0.95763751 |
| numpy | 2.01745459 | 9.4414273 | 18.09034507 |
下記のグラフは列数が増えることによる処理時間の変化ですが、pandas 、numpy とも単純に増加しているだけでした。
CSV読み込み及び合計計算
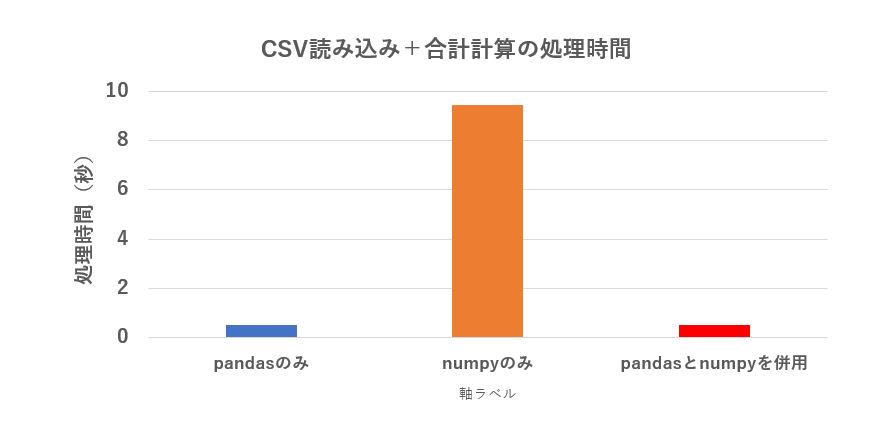
実用上、CSVを読み込んで何らかの計算を行うとうパターンが一番多いと思いますので、それを調べてみました。
今回は単純に、500列1万行のCSVを読み込んで、全データの合計を計算し print するという単純なもの1回だけ行った結果です。
#pandasのみ
df = pd.read_csv('p:/data.csv', skiprows=0, header=0, index_col=None,dtype='double')
print(df.sum().sum())
#numpyのみ
ar = np.loadtxt('p:/data.csv', delimiter=',', skiprows=1,dtype='double')
print(ar.sum())
#pandasとnumpyを併用
df = pd.read_csv('p:/data.csv', skiprows=0, header=0, index_col=0,dtype='double')
ar = df.values
print(ar.sum())numpy の方が計算時間は高速ですが、それよりも CSV ファイルを読み込む方が時間が掛かるため、結果は pandas の方が圧勝でした。
pandas で CSVを読み込み、ndarray に変換して numpy で合計計算する方法が速度的に有利ですが、pandas の計算も十分早いので、数値計算がそれほど多くない場合、pandas だけで済ませるのも有りかと思います。
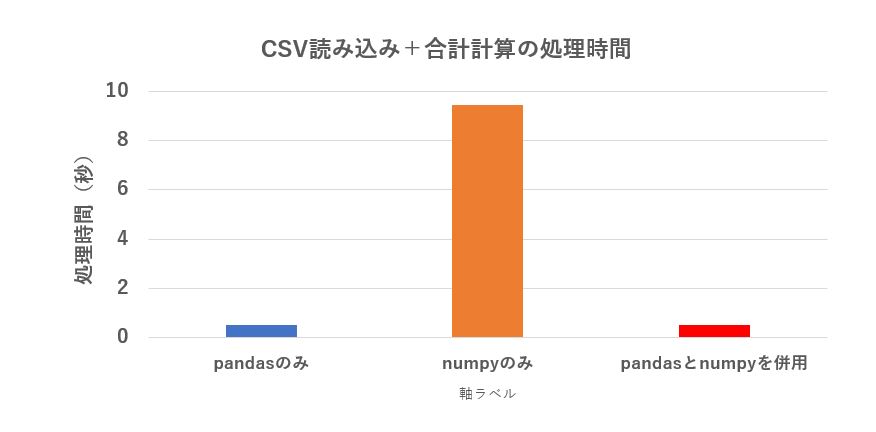
| 500列1万行のデータを読んで合計を求める | |
|---|---|
| pandasのみ | 0.51938532 |
| numpyのみ | 9.4414273 |
| pandasとnumpyを併用 | 0.52342579 |
pandasからndarray への変換時間
最後に、pandas の DataFrame から numpy の ndarray に変換する処理速度を図ってみました。
ar = df.values1行×1万列から10行1万列、及び 1万行1万列 のDataFrame を ndarray に変換する際の処理時間は、多少のバラつきはあるものの40 μ秒 前後と高速ですので、変化のオーバーヘッドは無視できる程度です。
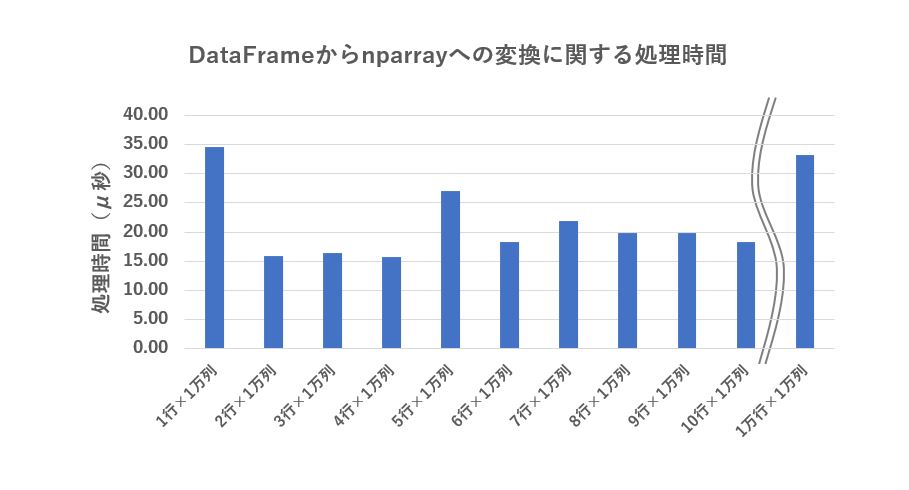
| DataFrameのサイズ | 処理時間(μ秒) |
|---|---|
| 1行×1万列 | 34.50 |
| 2行×1万列 | 16.00 |
| 3行×1万列 | 16.50 |
| 4行×1万列 | 15.80 |
| 5行×1万列 | 27.10 |
| 6行×1万列 | 18.30 |
| 7行×1万列 | 21.90 |
| 8行×1万列 | 19.90 |
| 9行×1万列 | 19.90 |
| 10行×1万列 | 18.30 |
| 1万行×1万列 | 33.20 |
まとめ
今回は pandas と numpy の違いを軽く触れ、両者の処理時間(処理速度)について計測した結果を紹介しました。
数値計算は numpy の方が数倍~十数倍ほど処理速度が速いのですが、CSVファイルの読み込みは逆転して pandas の方が20倍近く速いです。
多くの場合は csv 読み込みの方が処理時間が長いので、頻繁にCSVを読み書きする場合は pandas の read_csv() を使いましょう。
また、pandas も実用上の速度は十分高速なので、数値計算が多くて処理速度が気になる場合は、ndarray に変換して numpy で処理するというのが良さそうです。
今回の記事が皆様のお役に立てれば光栄です。








コメント