pandasのDataFrame にはデータを集計するためのgroupby や resampleというメソッドが用意されています。
個々の使い方については他のサイトで解説されていますが、体系的に解説している記事が見つからなかったので、今回はこれを取り上げました。
図を使って説明していますので、興味のあるかたは是非ご一読下さい。
pandasを使った集計の概要
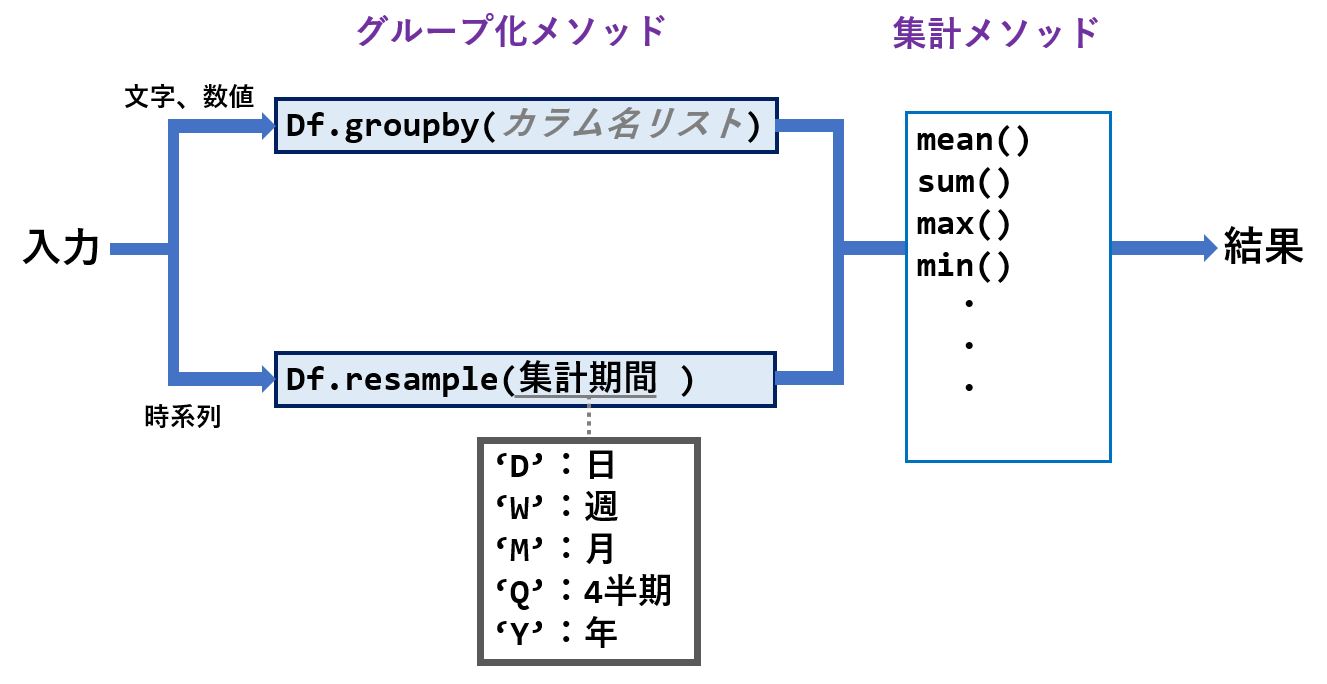
pandasのDataFrameに格納されているデータに対して、groupby や resample というメソッドを使うとことで、グルーピング集計が可能です。
| groupby | 任意のカラム(数値型、文字列)に対して集計したい時。 groupbyの第一引数で、グルーピングしたいカラムを記述する。 記述例:df.groupby("hoge").sum() |
|---|---|
| resample | 時系列データ(Datatime型)に対して、周期(年、月、日など)を指定して集計したいとき。 事前にDateTime型のカラムにインデックスを設定しておく必要あり。 記述例:df.resample("M").sum() |
集計結果の取得方法
集計結果は DataFrame として返って来ますが、階層型インデックス(MultiIndex)になっているため、値の取り出し方には少しだけ注意が必要です。
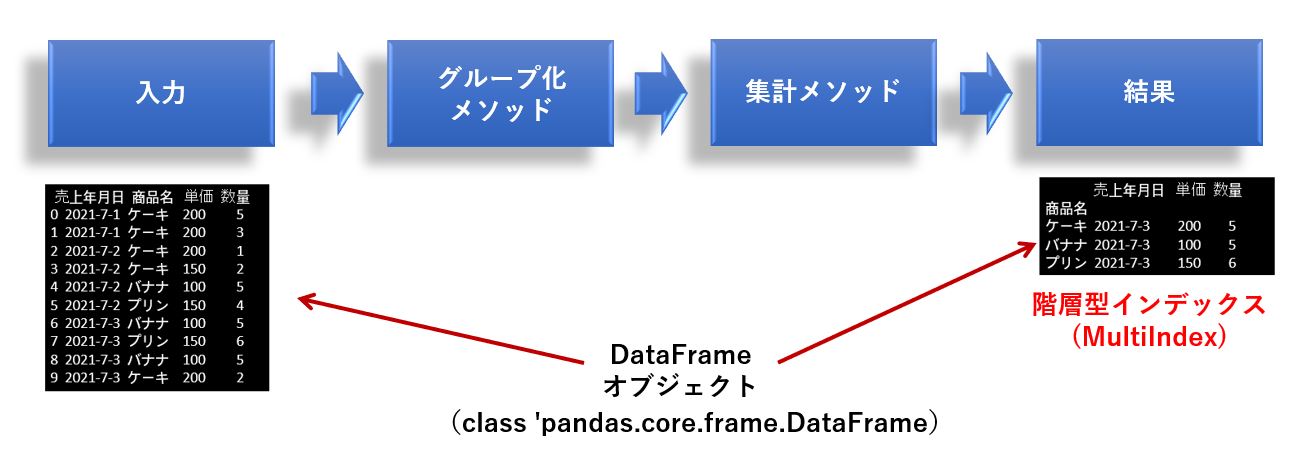
インデックスに指定したカラムと、それ以外のカラムでは取得方法が違います。
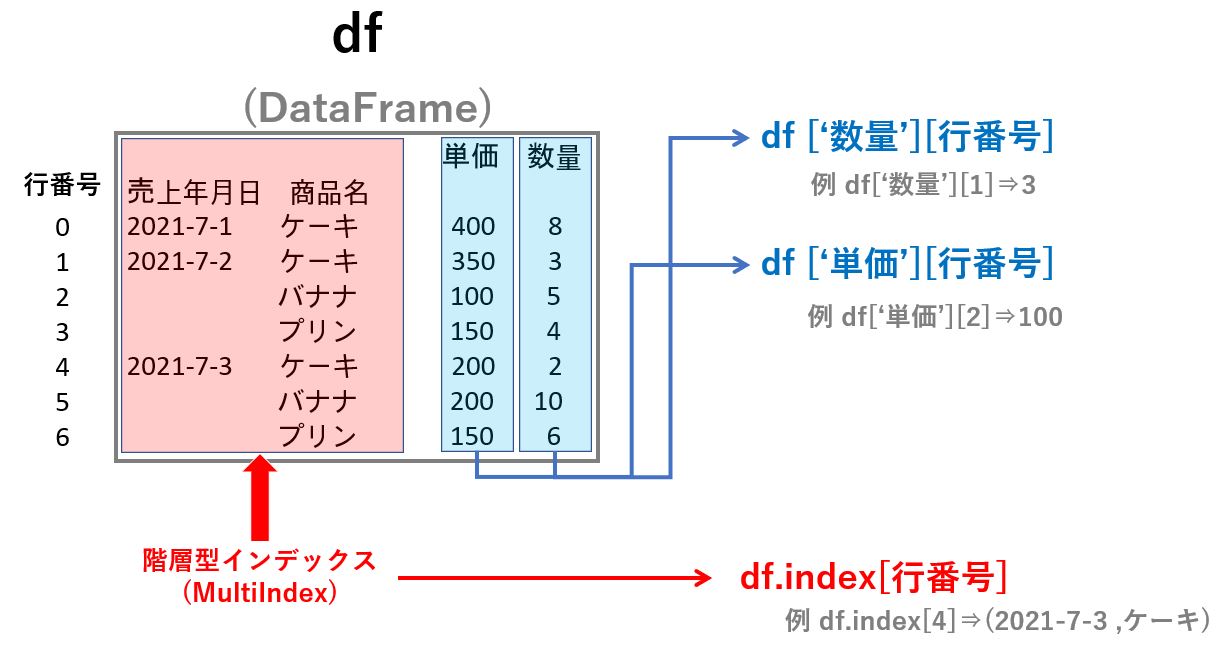
| 集計結果を取り出す場合 | 通常通り、カラムと行番号を指定して取得 例:print( df["数量"][1] ) |
|---|---|
| インデックスに指定したカラムを取り出す場合 | index に行番号を指定して取得(タプル型で返される) 例:print( df.index[1] ) |
IndexMultiIndexは1つ以上のカラム名がタプルで構成されているため、index[行番号]で返される値もタプルで返ってくることにご注意ください。下図は売上年月日と商品名で構成されたMultiIndexの例です。
もっと簡単な方法としては、MultiIndexを解除する方法もあります。
reset_index メソッドを使ってMultiIndexを解除すれば通常のDataFrameと同じアクセスができるようになります。
df.reset_index()MultiIndexを完全に削除したい場合は、引数に drop=Trueを指定します。
df.reset_index(drop= True)groupby を使った集計
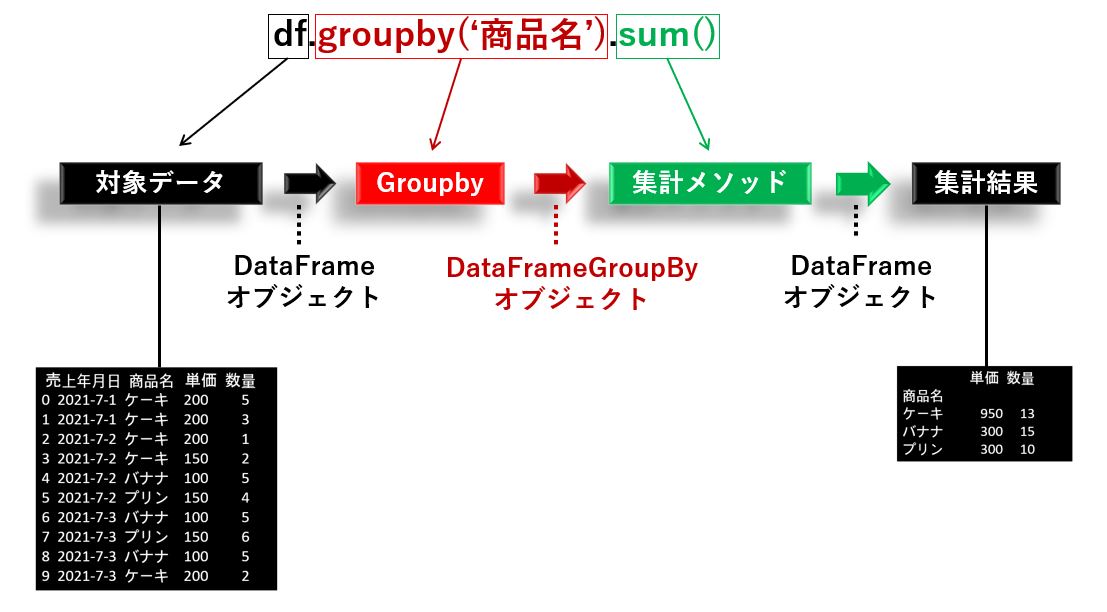
groupby によるグループ化は、引数にグルーピング対象のカラム名と記述し、続けて集計メソッドを記述します。
全てのカラムに対して、集計処理が実行されます。
df.groupby(グルーピング対象のカラム名).集計メソッド
df.groupby("商品名").sum() 売上年月日 単価 数量
商品名
ケーキ 2021-7-1 2021-7-1 2021-7-2 2021-7-2 2021-7-3 950 13
バナナ 2021-7-2 2021-7-3 2021-7-3 300 15
プリン 2021-7-2 2021-7-3 300 10
特定のカラムだけを集計したい場合は、カラム名を指定します。
df.groupby(グルーピング対象カラム名)[集計対象カラム名]
df.groupby("商品名")["単価"].sum()商品名
ケーキ 950
バナナ 300
プリン 300
Name: 単価, dtype: int64
グルーピング対象カラム、集計対象カラムのどちらも、複数カラム名が指定可能です。この場合は、リスト形式で指定します。
df.groupby([グルーピング対象カラム名1,・・・])[ [集計対象カラム名1,・・・] ]
df.groupby( ["売上年月日","商品名"] )[ ["単価","数量"] ].sum() 単価 数量 単価 数量
売上年月日 商品名
2021-7-1 ケーキ 400 8
2021-7-2 ケーキ 350 3
バナナ 100 5
プリン 150 4
2021-7-3 ケーキ 200 2
バナナ 200 10
プリン 150 6
集計メソッドに組み込み集約関数を使う
集計関数の中には、NumPyやPandasを使っているものもあるので、必要に応じてimport して下さい。ここではよく使われる集計関数を紹介しておきます。
詳細な情報が必要な場合は、pandas公式ドキュメントをご参照ください。
| メソッド名 | 内容 |
|---|---|
| mean() | 平均を求める |
| sum() | 合計を求める |
| max() | 最大を求める |
| min() | 最小を求める |
| median() | 中央値を求める |
| std() | 標準偏差を求める |
| var() | 分散を求める |
| count() | 行数を求める |
| first() | 先頭の1行を取得 |
| last() | 最後の1行を取得 |
| cumsum() | 累計和を求める |
では、具体的な例を挙げてみます。
下記はサンプルデータです。この記事に掲載したプログラムを実際に動かしたい場合、メモ帳等でCSVファイルとして保存してお使いください。
売上年月日,商品名,単価,数量
2021-7-1,ケーキ,200,5
2021-7-1,ケーキ,200,3
2021-7-2,ケーキ,200,1
2021-7-2,ケーキ,150,2
2021-7-2,バナナ,100,5
2021-7-2,プリン,150,4
2021-7-3,バナナ,100,5
2021-7-3,プリン,150,6
2021-7-3,バナナ,100,5
2021-7-3,ケーキ,200,2p:ドライブに group_data.csv という名前のCSVがあり、上記データが格納されているという前提で、商品名でグループ化し、それぞれの合計を計算する場合、次の様になります。
import pandas as pd
df = pd.read_csv('p:/group_data.csv',encoding='shift-jis',sep=',')
df.groupby('商品名').sum()
商品名だけで集計しているため、インデックス以外のカラム(単価と数量)はそれぞれ合計値が計算されます。

次は、売上年月日と商品名でグループ化してみます。
import pandas as pd
df = pd.read_csv('p:/group_data.csv',encoding='shift-jis',sep=',')
df.groupby(['売上年月日','商品名']).sum()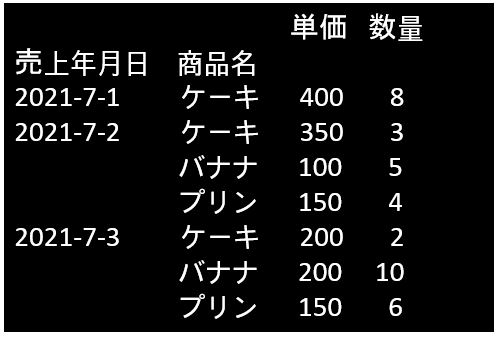
売上年月日と商品名が index となっていることが分かると思います。
グルーピング集計した結果の行数(=インデックスの個数)を取得する場合は、 size プロパティを使います。
df.index.size
import pandas as pd
df = pd.read_csv('p:/group_data.csv',encoding='shift-jis',sep=',')
res = df.groupby(['売上年月日','商品名']).sum()
#sizeで取得したインデックス個数を使ったループ
for i in range(res.index.size):
print(res.index[i])
#indexを使ったループ
for i in res.index:
print(i)集計メソッドに agg メソッド を使う
agg (Aggregationの略称) は指定したカラムに対して、集計関数を適用するメソッドです。集計したいカラムと集計関数を辞書形式で渡すことで、一度の呼び出しで複数カラムの集計が可能です。
df.groupby(グルーピング対象カラム名).agg({集計対象カラム名1: 集計関数1,・・・})
df.groupby('商品名').agg({'単価':'mean','数量':'sum'})
'mean' や 'sum’ の代わりに、ラムダ式を使うことも出来ます。
df.groupby('商品名').agg({'単価': lambda x: x.mean(), '数量': lambda x: x.sum()})また、ユーザー定義関数を作成し、agg から呼び出すことも可能です。
#列の平均を求めるユーザー定義関数
def my_mean(x):
return x.mean()
#列の合計を求めるユーザー定義関数
def my_sum(x):
return x.sum()
#aggにユーザー定義関数を使った例
df.groupby('商品名').agg({'単価': my_mean, '数量': my_sum})集計メソッドに apply を使う
agg はカラム単位に処理を行うメソッドで集計関数しか適用できませんでしたが、apply は行単位に任意の処理を実行できるメソッドです。
df.groupby(グルーピング対象カラム名).apply(ラムダ式又は関数)
ラムダ式又は関数には、グルピングされたデータ(複数レコード)が引数として渡されます。ラムダ式又は関数からは、DataFrame,Series,スカラなどを返すことが可能ですが、それぞれの挙動がややこしいので、ここではDataFrameを返す方法を紹介します。
下記のサンプルでは、全てのカラムに対して、mean()が実行されます。但し sum() の場合は文字列を結合してしまうため、商品名の欄が崩れてしまいます。
df.groupby('商品名').apply(lambda x:x.mean())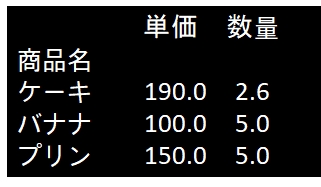
ラムダ式の中でカラムを指定できますが、全て同じ計算式を適用しなければなりません。例えば、単価は平均、数量は合計といった事が出来ません。
df.groupby('商品名').apply(lambda x:x[['単価','数量']].mean())DataFrameに格納して返すことで、任意の集計結果を表形式で得ることが出来ます。今回はカラム名を「単価平均」「数量合計」に変えてみました。
df.groupby('商品名').apply(lambda x: pd.DataFrame({'単価平均': [x['単価'].mean()], '数量合計': [x['数量'].sum()]}))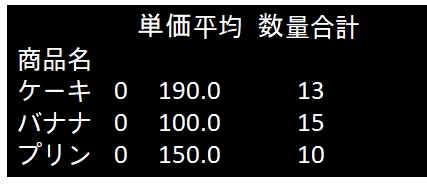
商品目の次に0が並んでいますが、これはインデックスです。グルーピングの単位でラムダ式が呼ばれますが、ラムダ式で1レコードだけを格納したDataFrameを作成しているため、行の先頭にインデックスの0が付加されてしまいました。
以下は関数を使って集計するサンプルです。ラムダ式と違って関数は複雑なことが記述できるので、応用範囲が広がります。
#関数の定義
def my_func(group):
# group を直接書き換えることが出来ないのでコピーしたものを書き換える
row = group.iloc[0].copy()
row['単価'] = group['単価'].mean()
row['単価×数量'] = row['単価'] * row['数量']
return row
#applyの実行
df.groupby('商品名').apply(my_func)
row = group.iloc[0].copy() は グルーピングされた結果(複数行)の先頭レコードを iloc[0] で取得し、それをコピーして row に格納しています。
group を直接編集することが出来ない仕様なので、コピーしたものを使う必要があります。
関数に任意の引数を渡したい場合、呼び出し側は 次の様に記述します。
apply(関数名,引数1,引数2,・・・)
ユーザー関数側は 次の様に記述します。
my_func(groupbyから受け取る引数名,applyから渡される任意の引数1,・・・)
#引数が2個の関数定義
def my_func(group,num):
return group * num
#任意の引数を渡す呼び出し方
df.groupby('商品名').apply(my_func,3)
resampleを使った集計
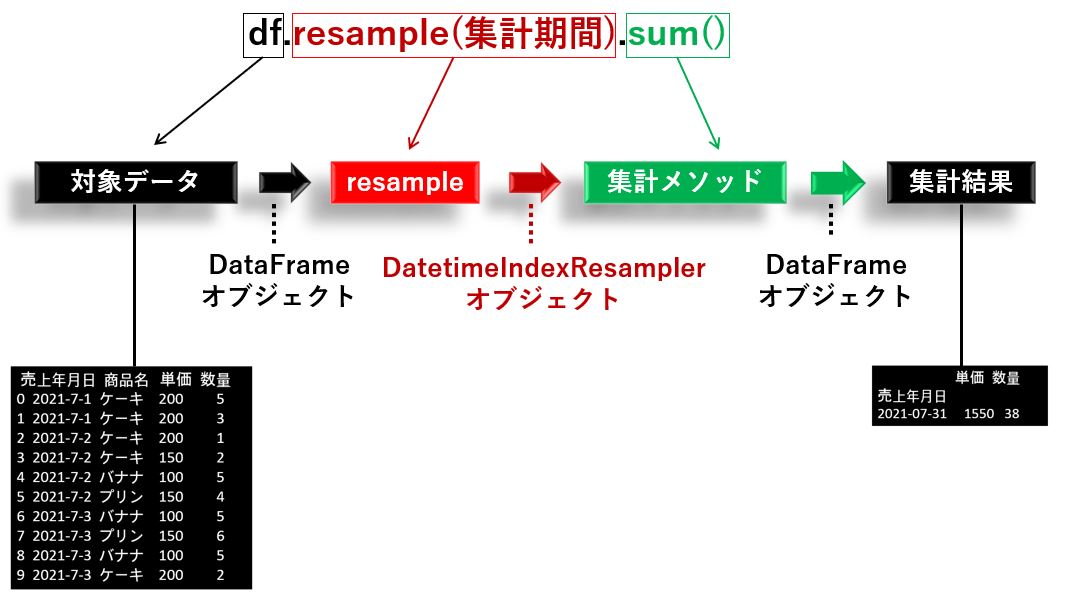
resample は時系列に特化したグルーピング集計です。引数に指定した集計期間を使って、平均や合計などの集計計算を行わせることができます。尚、集計計算はGroupByと同じものが指定できます。
resample を使うには、あらかじめ datetime型のカラムにインデックスを設定しておく必要があります。
df.resample(集計期間)
df.resample('M').sum()集計期間には次の文字が指定できます。また、文字の前に数値を書くことで、2日や3ヶ月といった指定も可能です。
| 集計期間 | 文字 | 使用例 |
|---|---|---|
| 日 | D | resample('2D') ⇒2日ごとの集計 |
| 週 | W | resample('3W') ⇒3週間ごとの集計 |
| 月 | M | resample('M') ⇒1か月ごとの集計 |
| 四半期 | Q | resample('Q') ⇒四半期ごとの集計 |
| 年 | Y | resample('5Y') ⇒5年ごとの集計 |
CSVを読み込んで resample するには
read_csvでCSVファイルを読み込む際、index_col 引数にDateTime型のラカムを番号で指定し、日付型に変換するためにparse_dates=True を指定します。
pd.read_csv(ファイル名,index_col=カラム番号,parse_dates=True)
先ほどのCSVを例に、売上年月日をdatetime型のインデックスとして指定し、月ごとの集計を行うには次の様になります。
import pandas as pd
df = pd.read_csv('p:/group_data.csv',encoding='shift-jis',sep=',',index_col=0,parse_dates=True)
df.resample('M').sum()
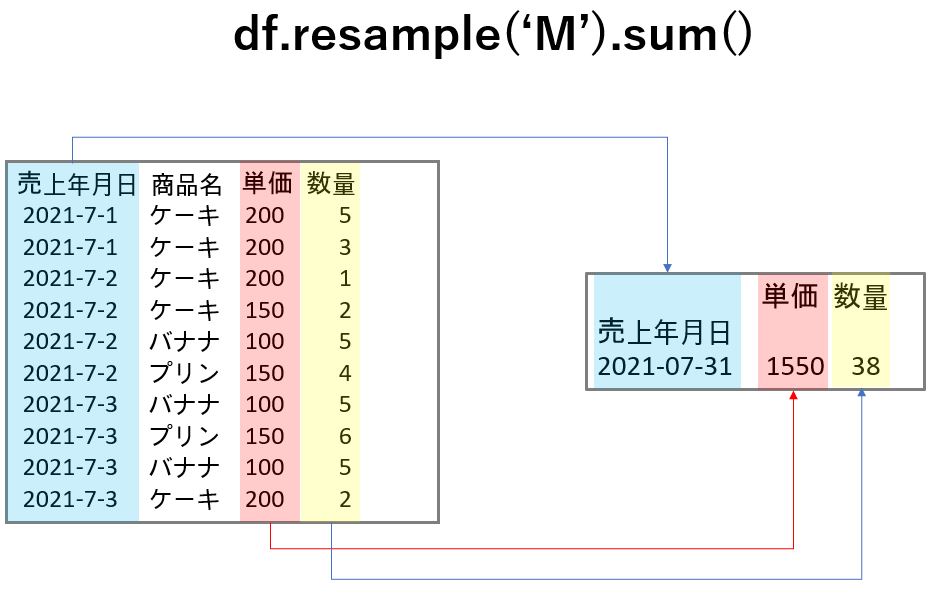
今回のサンプルデータは7月のデータしかないので、1か月ごとの集計では1行となります。
まとめ
今回はpandas DataFrame を使った集計について、groupby と resample を紹介いたしました。
単に月ごとや年毎であれば、文字列として扱って groupby すれば事足りますが、2日ごとや1週間ごとなどの集計では resample を使う方が圧倒的に便利です。
resample は datetime 型のインデックスで集計するため、もちろん1時間ごとや5分毎、秒単位での集計も可能です。
CSVデータをサクっと集計するには非常に便利ですが、慣れない間はけっこう悩んでしまうのではないでしょうか。
そんな方のために、今回の記事がお役に立てれば幸いです。








コメント