データ分析やデータのグラフ化を行う上で、欠損値の扱いは非常に重要です。
今回はPandasのDataFrameに含まれる欠損値(NaN)の補完方法について、最低限知っておくと便利な内容に絞って解説したいと思います。
補間した結果が理解しやすいよう、グラフを使って補間結果を可視化していますので、特に先頭や末尾に欠損値がある場合、どのように補間されるか知りたい方はご一読下さい。
欠損値の確認方法
欠損値が存在するか否かは、次のメソッドで確認できます。
df というインスタンス変数に値が格納されていると仮定すると、次のメソッドでカラム毎の欠損値の工数を表示することが出来ます。
df.isnull().sum()
例えば、pandas を使って読み込んだCSVデータに対して、欠損値の確認は次のようになります。
import pandas as pd
df = pd.read_csv('d:/data.csv')
print(df.isnull().sum())
pandas で欠損値を処理する際の注意点
pandas には欠損値を処理するメソッドがいくつか用意されていますが、特に指定しない場合は対象となるDataFrame の書き換えは行われません。
言い換えると、元のDataFrameからコピーされたものに対して処理が行われます。
もし、元のDataFrameに対して処理結果を反映させたい場合は、inplace引数にTrueを設定するか、メソッドの戻り値を元の変数に代入するなどの処理が必要です。
#inplace引数を使う例
df.dropna(inplace=True)
#処理結果を元の変数に代入する例
df = df.dropna()欠損値のがある列又は行を削除
欠損値を含む行、又は列(カラム)を削除したい場合は、 dropna メソッドを使います。
df.dropna()
なにも引数を指定しない場合、欠損値が1つでも存在する行が削除されます。
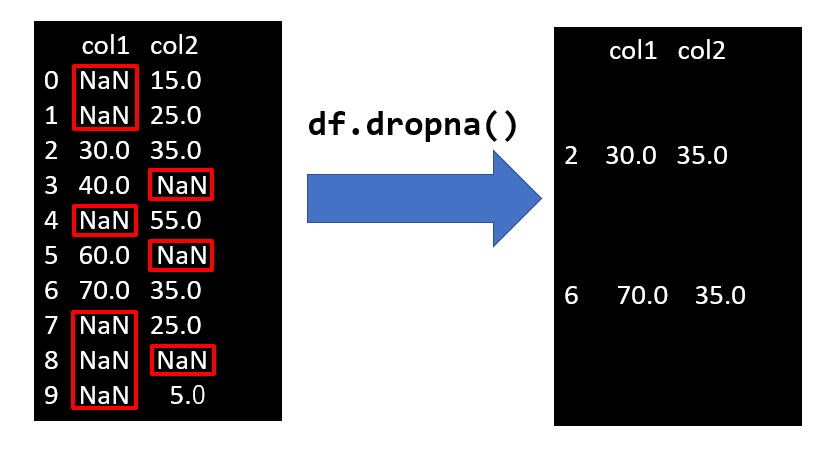
dropna にはいくつかのオプションがあって、有効な要素の数が指定値未満のものを削除したり、特定の行や列の欠損値で削除するか否かを判断することが出来ます。
| 引数名 | 使用例 | 解説 |
|---|---|---|
| inplace | inplace=True | 補正結果をオブジェクトに反映(更新)する |
| axis | axis=1 | 1を指定すると、列が削除対象となる |
| how | how='any' | ’any':欠損値が1つでも含まれていれば、その行又は列を削除 'all':全ての値が欠損値の場合、その行又は列を削除 |
| thresh | thresh=3 | 有効な(欠損値ではない)要素が指定数に満たない行又は列を削除 |
| subset | subset=['col1'] | 指定した列に欠損値がある行又は列を削除する |
import pandas as pd
df = pd.read_csv('d:/data.csv')
df.dropna(how='any',thresh=3)データの補間処理
欠損値の補間処理としてよく使われる方法は次の3通りあります。
- 欠損値を既定値で埋める
- 欠損値を直前または直後の値で埋める
- 欠損値を前後の値から推測して埋める
規定値で埋める
既定値で埋める場合は fillna メソッドを使います。
df.fillna(規定値)
例えば、欠損値を0で埋めたい場合は、次のようになります。
import pandas as pd
df = pd.read_csv('d:/data.csv')
print(df.dropna(0))
直前又は直後の値で補間する
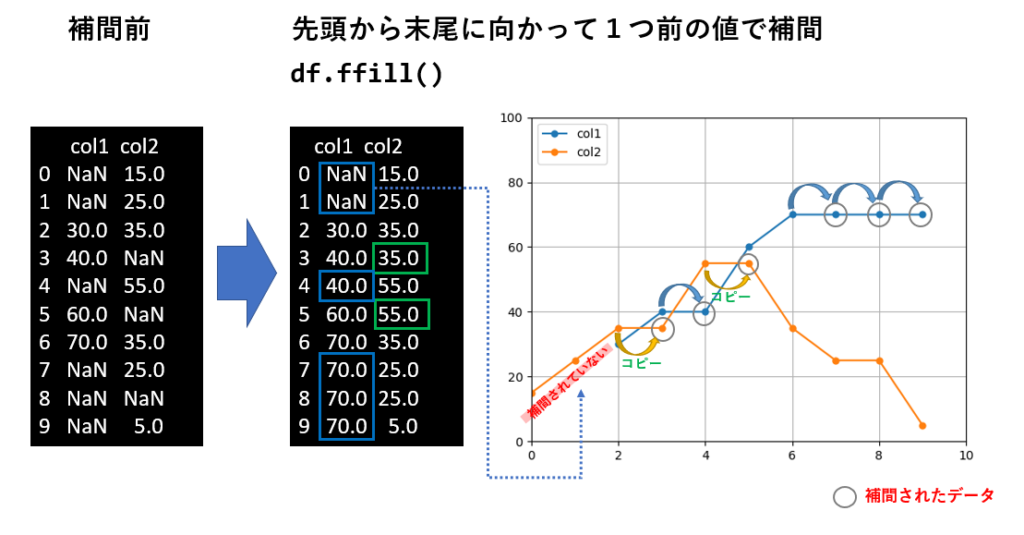
欠損値に対して、直前又は直後の値をコピーして補間する場合は ffill()、bfill() メソッドを使います。
df.ffill() 又は df.bfill()
fillna() を使っても同じことができますが推奨されていません(使えますが、警告が表示されます)。
※この書き方は非推奨
df.fillna(method='ffill') 又は df.fillna(method='bfill')
ffill()は、データの先頭から末尾に向かって欠損値を探し、見つかった時点で直前の値をコピーします。
bfill()は、逆に末尾から先頭に向かって欠損値を探し、見つかった時点で直前の値をコピーします。
import pandas as pd
df = pd.read_csv('d:/data.csv')
print(df.ffill())
print(df.bfill())
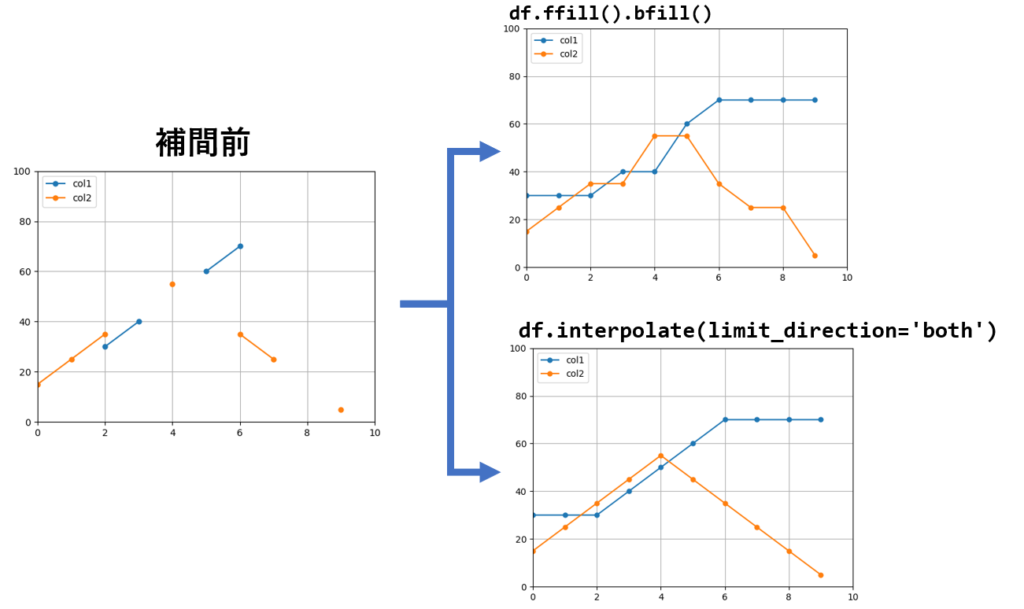
では、ここからはデータをグラフ化して、どのように補間されるかを確認していきましょう。
今回使う補間前のデータと、それをグラフ化した結果をあらかじめ確認しておきます。
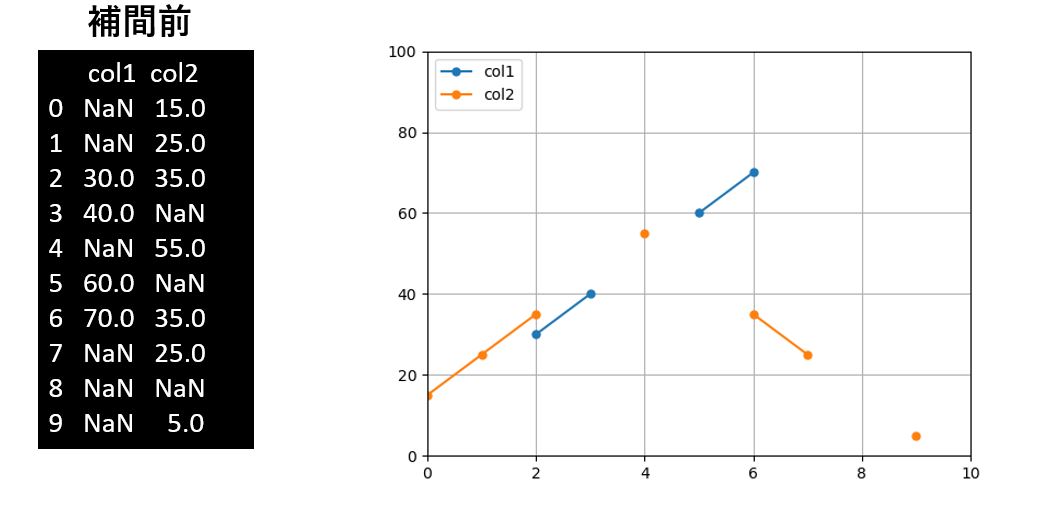
注目すべき点は、データの先頭及び末尾に欠損値があった場合の挙動です。
ffill() で補間した場合、先頭に欠損値があっても、それは補間されません。
逆に、bfill() で補間した場合、末尾に欠損値があっても、それは補間されません。
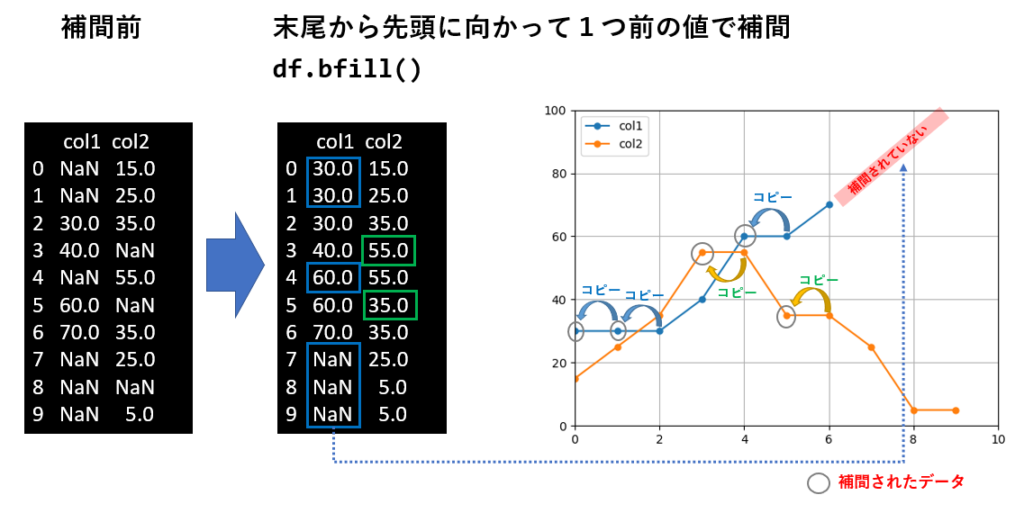
この様に、データの先頭と末尾に欠損値が存在するケースでは、ffill()に続けて bfill()を呼ぶ事で解決できます。
import pandas as pd
df = pd.read_csv('d:/data.csv')
print(df.ffill().bfill())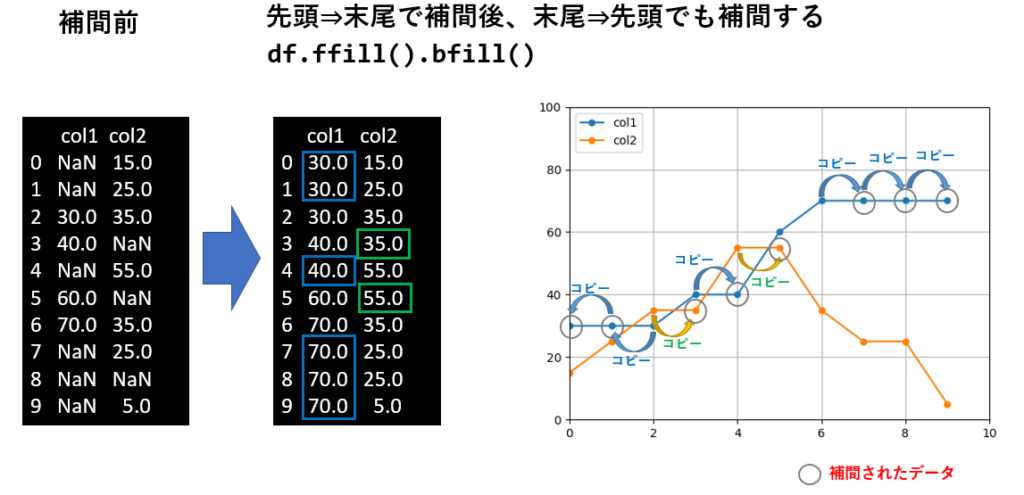
前後の値から欠損値を推測する
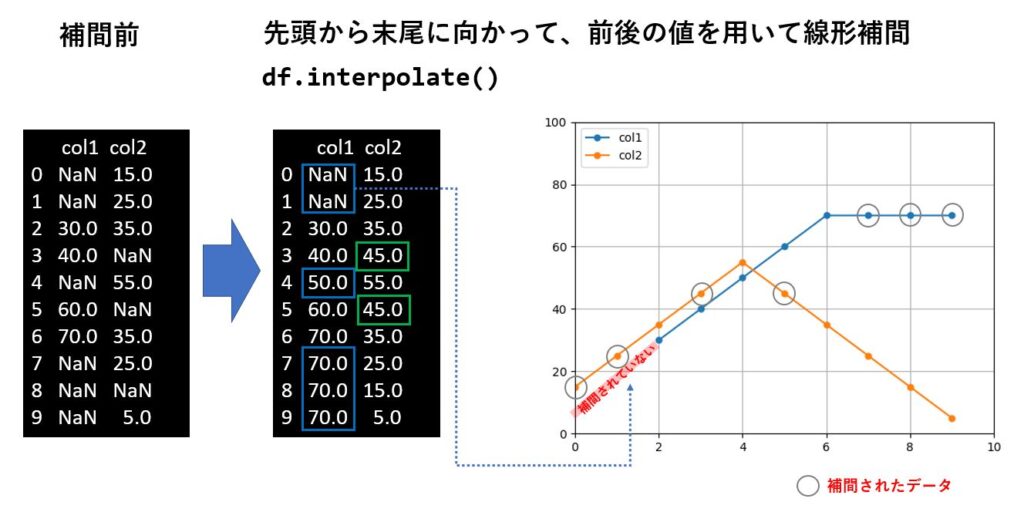
欠損値の前後の値を使って補間する場合は interpolate メソッドを使います。
df.interpolate()
このメソッドは値の増減が線形(等間隔)であると仮定し、欠損値を推定してくれます。
interplate メソッドも fillna メソッドと同様に、引数で補間の方向(先頭⇒末尾、末尾⇒先頭)が指定できます。
| 引数名 | 使用例 | 解説 |
|---|---|---|
| inplace | inplace=True | 補正結果をオブジェクトに反映(更新)する |
| axis | axis=1 | 1を指定すると、列が削除対象となる |
| limit | limit=3 | 欠損値が連続している場合、最大何個まで補間するかを指定する 初期値はNoneで、この場合は無制限に補間される |
| limit_direction | limit_direction=’both' | 'forward':先頭⇒末尾に向かって補間 'backward':末尾⇒先頭に向かって補間 'both':先頭⇒末尾、末尾⇒先頭の両方で補間う |
| method | method='linear' | 'linear':線形補間 'spline':スプライン曲線による補間 その他の値についてはpandasリファレンスをご参照下さい。 |
ffill()や bfill()の様に直前値で補正する場合、先頭から補間するか末尾から補完するかによって値が変わってきますが、interplate の場合はどちらから補間しても同じ結果になります。
ただ、補間する方向によって先頭の欠損値が補間されなかったり、末尾の欠損値が補間されないといった違いは起こります。
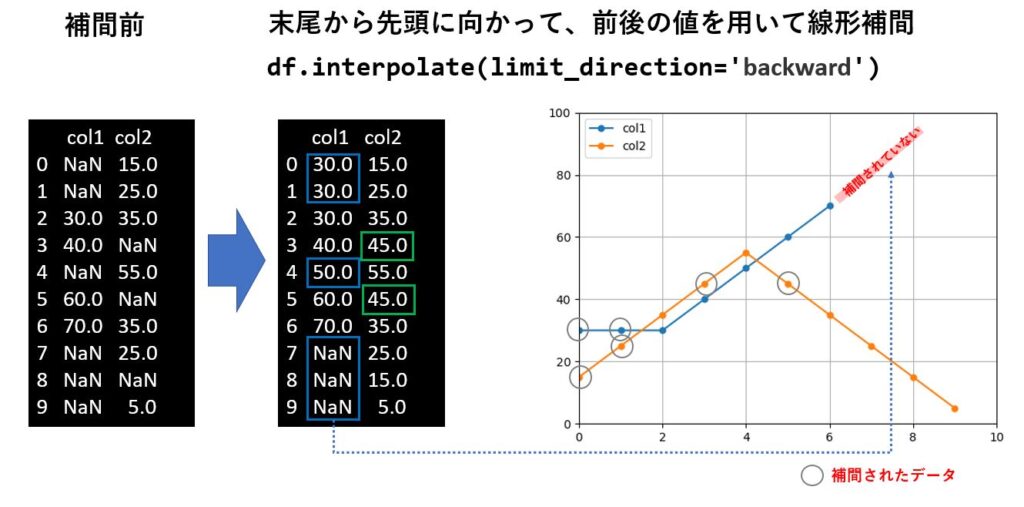
limit_direction='backward' と指定した場合も同様に、やはり末尾の欠損値は補間されません。
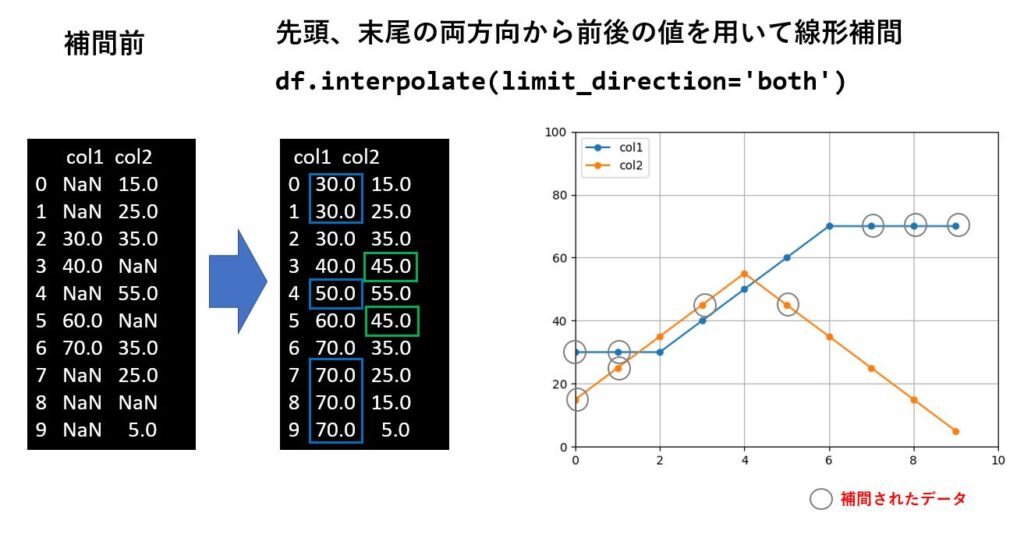
先頭と末尾の両方に欠損値がある場合、fillnaの様に2回呼ぶ必要はなく、limit_direction='both' で補間することが可能です。
fillna と interpolate の補間結果の比較
fillna と interpolate の2つの補間方法について、それぞれ解説してきました。
最後に2つの補間方法で作成したグラフを比較して、共通点と違いをまとめておきたいと思います。
まず、末尾に存在する欠損値は、どちらにおいても直前の値を引き継いだ補間になっています。
interpolate が線形だからと言って、先頭や末尾の欠損を傾きで予測するようなことはやっていないようです。
一方、間に存在する欠損値については、fillna は単純に直前と値をコピーしているだけに平坦ですが、interpolateの場合はそれっぽく補間されています。
この様な傾向の差を念頭に、どちらを使うべきかを検討していただければと思います。
参考までに、今回の記事を書くために作ったサンプルプログラムを紹介しておきます。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('p:/data.csv')
#res = df.ffill()
#res = df.bfill()
#res = df.ffill().bfill()
#res = df.interpolate()
#res = df.interpolate(limit_direction='backward')
res = df.interpolate(limit_direction='both',limit_area='inside')
print("======== 補正前 ===================================")
print(df)
print("======== 補正後 ===================================")
print(res)
#グラフ描画
fig = plt.figure()
ax = fig.add_subplot()
ax.set_ylim(0,100)
ax.set_xlim(0,10)
plt.plot(res,markersize=5,marker='o')
plt.grid(True)
plt.legend(df.columns,loc='upper left')
plt.show()まとめ
今回はpandas を使った欠損値の処理方法について、最初に欠損値を含むデータを削除する方法、次に何らかの値で補完する方法について解説しました。
データ量が多く欠損値が少ない場合はデータを削除するアプローチでも問題ありませんが、データが少ない場合はデータ補間による救済処置が重要になります。
pandas に欠損値の補間機能があるということは知っていても、先頭や末尾に連続した欠損値が存在する場合、どのように補間されるのかすぐに思い浮かばない方も多いのではないかと思いますので、そのような方のお役に立てれば幸いです。








コメント