仕事で PostgreSQL のストアドプロシージャを使うことになったので、色々とググったところ、今一分かりやすい記事が見つかりませんでした。
そこで、これから PostgreSQL でストアドプロシージャ(stored procedure)やストアドファンクション(stored function)を始めたい人向けに作り方を解説したいと思います。
サンプルも豊富に掲載していますので、是非お役立てください。
ストアドプロシージャとは
ストアドプロシージャとは、データベースに登録して使うプログラムの事です。
通常は、アプリケーションからデータベースへ命令する場合、命令の回数文だけSQLを実行しなければなりません。
例えば、4つのSQLを実行する場合、データベースに対して4回の通信が発生します。
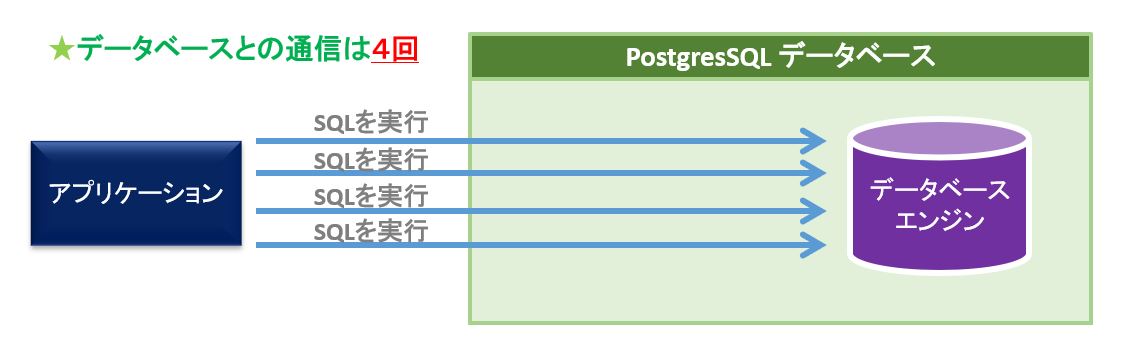
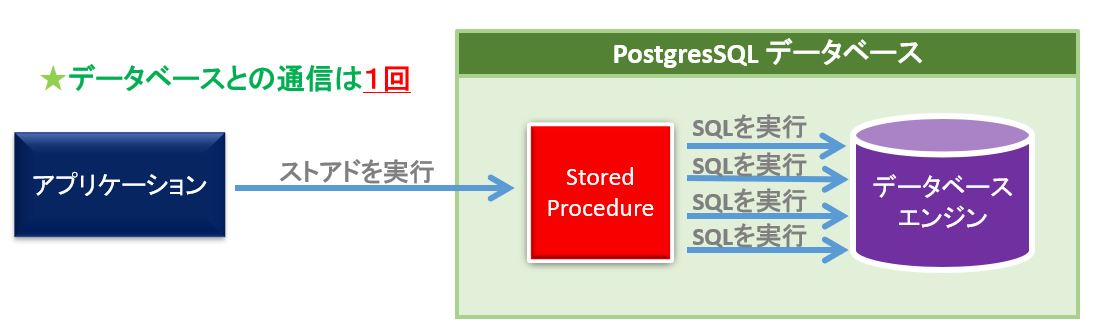
実行したいSQLをデータベースに登録(stored proceder)しておき、これを呼び出すことが出来れば、アプリケーションとデータベースの通信は1回で済みます。
ストアドプロシージャのメリット
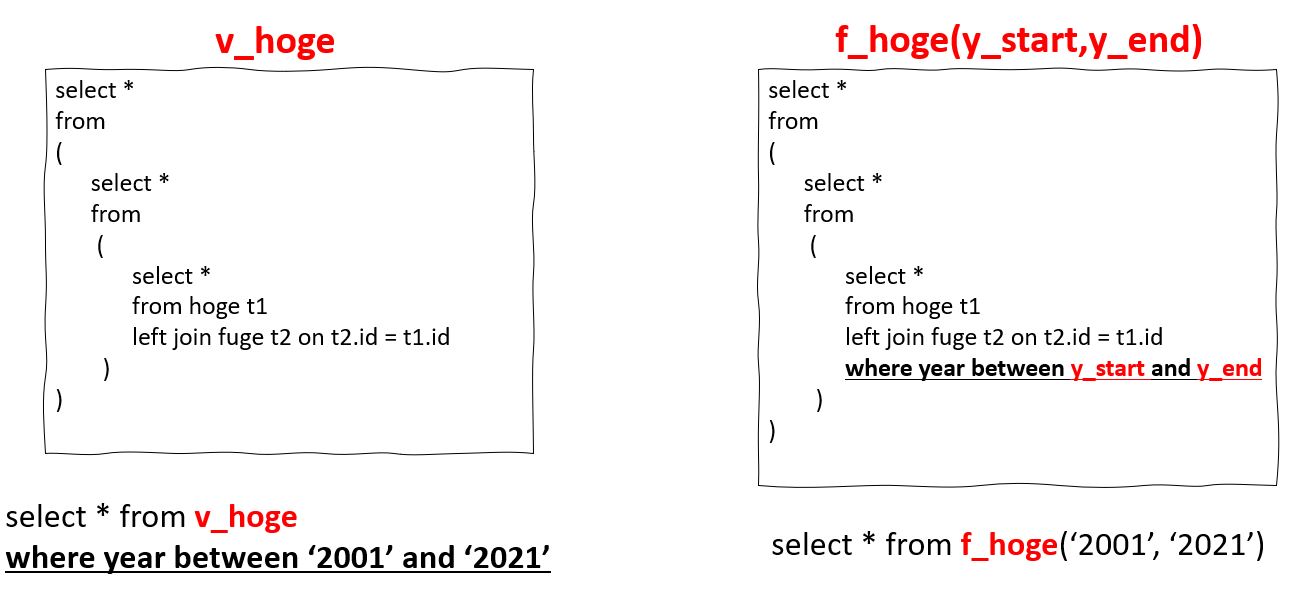
- 大量のSQLを実行するケースにおいて、データベースとの通信量、データベースエンジンのSQL解析時間が大幅に削減されるため、処理時間が短縮できる。
- 副問い合わせを何段にも重ねるVIEWを作る場合、プログラムの中に検索条件を記述することで対象データを絞り込めるため、処理時間が短縮できる。
ストアドプロシージャのデメリット
- データベース毎に用意された専用のプログラミング言語を覚える必要がある
- プログラムで出力項目や検索項目が固定化されるため、VIEWのように臨機応変に出力項目や検索項目を追加することが出来ない。
- プログラムのデバッグがしづらい
ストアドプロシージャの種類
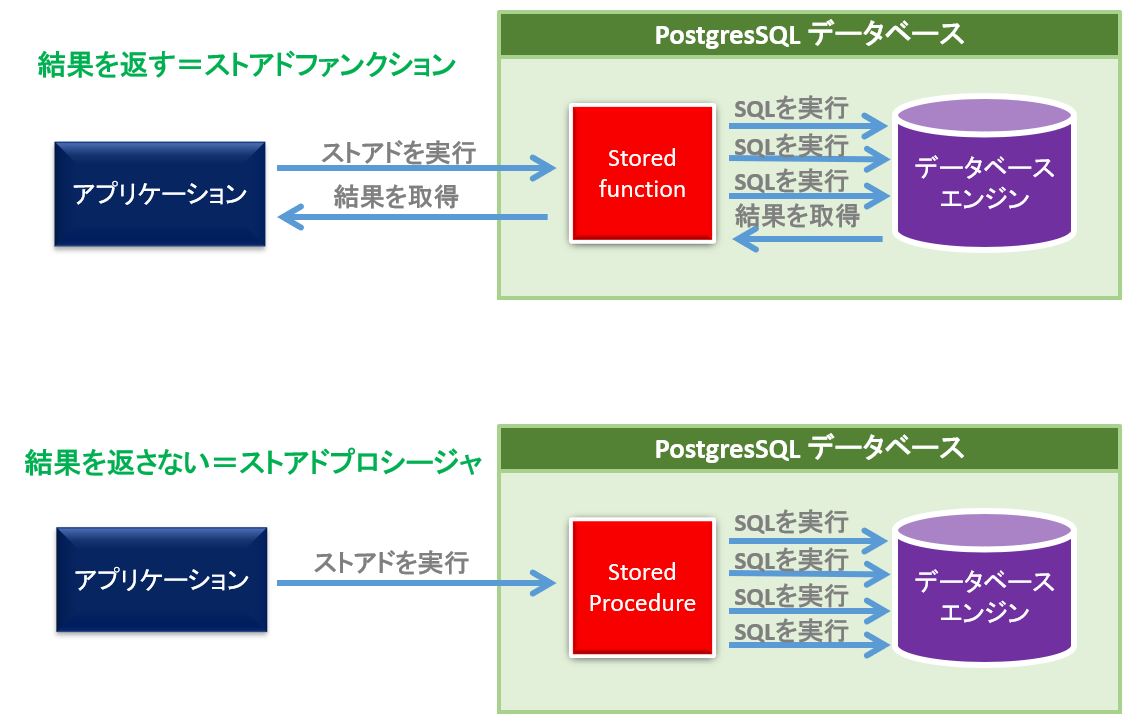
ストアドプロシージャには、「結果を返す」ものと、「結果を返さない」ものが存在します。
「結果を返すもの」はストアドプロファンクション(stored function)と呼んでおり、「結果を返さない」ものはストアドプロシージャ(stored procedure)と呼んで区別します。
しかし、実際の現場では両者をまとめてストアドプロシージャと呼ぶ事も多く、ストアドとか、ストプロという省略後を用いる場合もあります。
この記事では、ストアドと記述する部分がありますが、その場合はストアドプロシージャ、ストアドファンクションの両方について言及していると思ってください。
PostgreSQLで知っておくべき基礎知識
PostgreSQLでストアドを作成する場合、PL/pgSQL (Procedural Language/PostgreSQL Structured Query Language)という専用の言語を使います。
詳細は公式サイトに記述されていますが、非常に分かり難いので、この記事では「これだけ知っていれば困らない」内容について解説したいと思います。
また、書き方については色々とパターンがあり、他のサイトを見比べてみると微妙に記述の仕方が異なっています。
これは、特定のステートメントを省略したり、短縮することがPL/pgSQLの言語仕様として許されているためです。
ユーザーの記述に幅を持たせることでプログラミングを楽にしたり、他のデータベースのストアドへ移植しやすくするためだと思いますが、逆に複数の記述が許されることで初心者は逆に混乱するかもしれません。
このサイトで紹介する記述方法が全てではありませんが、少なくともこのサイトで紹介する内容を覚えておけば、おおよその事は実現できるようになっています。
ストアドの書き方
ストアドプロシージャは「結果を返すもの」と「結果を返さないもの」の2通りありますが、どちらも DECLARE と BEGIN の2つのブロックに分かれており、DECLAREには変数やカーソルなどの定義を、BEGIN には処理の中身を記述します。
両者の違いは、 宣言時における 「CREATE ~ FUNCTION ~」 と 「CREATE ~ PROCEDURE」 のどちらを使うかと、戻り値を返す 「RETURN 戻り値」 が有るか無いかだけです。
<ストアドファンクションの書き方>

<ストアドプロシージャの書き方>

記述上のルール
以下は、プログラミングする上で覚えておきたい基本的なルールです。
- 行末はC#やJavaと同じくセミコロンを使う。(例 SELECT * from HOGE ; )
- 代入は コロンとイコールを続けて書く(例 data := 12345)
- DECLARE~BEGINの間に、プログラム中で使う変数の名前と型を定義する
- BEGIN~ENDまでの間にプログラムを記述する。
- 引数で指定した変数もプログラム内で自由に使うことが出来る。

ストアド内で使える変数は、引数と自分で定義した変数以外に、後述する「カーソル」内で使う変数があり、テーブルのカラム名も含めてプログラム内で利用することになります。
PostgreSQLにストアドを登録する際、例えばカラム名と同じ名前を引数で定義していたり、DECLAREで宣言したりすると、PostgreSQLはどの変数の事を指しているのか判断できずエラーになってしまいます。
これを防ぐために、変数の先頭には、どこで定義されたかを示す接頭語(引数なら"p_"、自分で定義した場合は "v_"など)を付ける方法をお勧めします。
よく使うデータ型
他にもありますが、よく使うデータ型を一覧にまとめました。他にも多くの型がありますので、詳しくはPostgreSQL公式ページをご覧下さい。
| 型名 | 説明 | 補足 |
|---|---|---|
| integer | 4バイトの整数 | -2147483648~ +2147483647 |
| numeric | 整数部と実数部の桁数を指定した 実数 | Create Table では numeric(全桁数,小数部桁数) で記述するが、ストアド内では 単に numeric だけでOK |
| bigint | 8バイトの整数 | -9223372036854775808 ~ +9223372036854775807 |
| double precision | 8バイトの浮動小数点 | |
| varchar | サイズ指定された文字列 | Create Tableでは文字数を 指定するが、ストアド内では 単に varchar だけでOK |
| char | 1文字 | おおよそ 1E-307~1E+308 (最低15桁の精度を保証) |
| text | サイズ指定無しの文字列 | 最大1GBまでの文字列が格納可能 |
| date | 日付 | 年月日 |
| timestamp | 日付と時刻 | 年月日時時分秒 |
| RECORD | 1行を丸ごと格納する型 (SELECTやFETCHなどでデータを 格納した時、変数が生成される) | 「変数名.カラム名」 で各カラムに アクセスが可能 例: v_line 売上明細%ROWTYPE v_line.数量 := 500 |
| テーブル名%ROWTYPE | 1行を丸ごと格納する型 (指定したテーブルと同じカラムと 型を持つ変数を、宣言時に生成) | 宣言時に変数が生成されることを 除いて、RECORDと同じ |
| CURSOL | カーソルを格納する変数 | |
| REFCURSOR | カーソルを格納する型 |
組み込み関数
よく使う組み込み関数をまとめています。詳しくはPostgreSQLの公式ページをご覧下さい。
| 用途 | 書式 | サンプル | 補足 |
|---|---|---|---|
| 型変換 | CAST(値 AS 型) | CAST('12345' AS NUMERIC) CAST(923.5 AS VARCHSR) | 値::型 と書くことも可能 '12345'::NUMERIC 923.5::character varying |
| 日付→文字 | TO_CHAR(値, 書式) | TO_CHAR(current_timestamp ,'YYYY/MM/DD') | YYYY/MM/DD HH24:MI:SS →'2023/01/01 09:08:05' |
| 文字→日付 | TO_DATE(値,書式) | TO_DATE(’2023-01-01' ,'YYYY-MM-DD') | |
| 文字数 | LENGTH(値) | LENGTH('aiueo') | |
| 切り出し | SUBSTR(値,位置、文字数) | SUBSTR('abcd',2,3) | |
| 置換 | REPLACE(値,文字列,文字列) | REPLACE('abcd','bc','BC') | |
| 前後空白削除 | TRIM(値) LTRIM(値) RTRIM(値) | TRIM(' abcde ') LTRIM(' abcde ') RTRIM(' abcde ') | 全角空白は削除されない |
| 文字列位置 | POSITION(値 IN 文字列) | POSITION('12ab3' IN 'ab') | 位置を1以上の値で返す 含まれない場合は0が返される |
| NULLの置換 | COALESCE(値,変換値) | COALESCE(null,0) | 第一引数はnull の可能性がある 変数、第2引数はnullを置換 したい値 |
| 当日の日時 | CURRENT_TIMESTAMP CURRENT_DATE CURRENT_TIME | CURRENT_TIMESTAMPは NOW() でも代用可能 |
尚、PostgreSQLには、日付や時間に関する関数が数多く用意されています。こちらの公式ページに詳細が掛かれていますので、必要に応じてご活用下さい。
知っておきたい構文
ストアドプロシージャの中では、ループや条件分岐が使えます。全てを紹介することが出来ないので、ここではよく使われる構文について触れておきます。
詳細はPostgreSQL公式ページをご覧ください。
| 構文 | 記述方法 | 補足説明 |
|---|---|---|
| IF文 | IF 条件式1 THEN ~条件式1が真だった場合の処理~ ELSIF 条件式2 ~条件式2が真だった場合の処理~ ELSE ~全ての条件式が偽のだった場合の処理~ END IF; | ①ELSIF は省略したり、複数記述することが可能 ②ELSIF は ELSEIF と書くことも可能 ③1つの条件式に複数の条件を書くことも可能 例: IF 200 < cnt and cnt < 500 THEN |
| CASE文 | CASE WHEN 条件式1 THEN ~条件式1が真だった場合の処理~ WHEN 条件式2 THEN ~条件式2が真だった場合の処理~ ELSE ~全ての条件式が偽のだった場合の処理~ CASE END; | IF文と同じ |
| FOR文 | FOR 変数名 IN 1 .. 100 LOOP ~処理~ END LOOP; | ループから抜ける場合は EXIT; ループの先頭に戻る場合は CONTINUE; |
| FOREACH文 | FOREACH 変数名 IN ARRAY 配列名 LOOP ~処理~ END LOOP; | ループ内で、EXITやCONTINUEが使える |
| WHILE文 | WHITE 条件式 LOOP ~処理~ END LOOP; | ループ内で、EXITやCONTINUEが使える |
| LOOP文 | LOOP ~処理~ EXIT WHEN 条件式 ~処理~ END LOOP; | ループ内で、EXITやCONTINUEが使える |
ストアドの呼び出し方
呼び出し方はファンクションとプロシージャで変わります。
ストアドファンクションの場合、テーブルの代わりに使うことが出来ます。
select * from ストアドファンクション名(引数1,引数2,・・・)
一方、ストアドプロシージャの場合は call を使います。
call ストアドプロシージャ名 (引数1,引数2,・・・)
select * from func_hoge('2021/10/10','大阪')
call pro_hoge('2021/10/10','大阪')ストアドの削除方法
ストアドの削除方法については drop を使います。
ただ、PostgreSQLのストアドは引数の数やデータ型が異なれば同じ名前で登録できますので、引数の型まで指定する必要があります。
ストアドファンクションの場合
drop function ファンクション名(引数1 データ型1,引数2,データ型2,・・・)
ストアドプロシージャの場合
drop procedure プロシージャ名(引数1 データ型1,引数2,データ型2,・・・)
drop function func_hoge(yymmde date,area varchar)
drop procedure pro_hoge(yymmde date,area varchar)テストテーブルについて
この記事で紹介するストアドは、以下のテストテーブルに対して動作確認を行いました。
記載内容を再現したい場合は、あらかじめ下記のSQLを実行して下さい。
create table "public"."売上明細" (
"販売日" date not null
, "地域" character varying(50) not null
, "品名" character varying(50) not null
, "数量" integer
, primary key ("販売日", "地域", "品名")
);
create table "public"."集計表" (
"地域" character varying(50) not null
, "数量" integer
, primary key ("地域")
);
insert into 売上明細 values('2021/10/10','愛知','ういろう',230);
insert into 売上明細 values('2021/10/10','沖縄','紅芋タルト',80);
insert into 売上明細 values('2021/10/10','岩手','かもめの玉子',200);
insert into 売上明細 values('2021/10/10','宮城','笹かまぼこ',300);
insert into 売上明細 values('2021/10/10','京都','八つ橋',300);
insert into 売上明細 values('2021/10/10','秋田','だまこ餅',50);
insert into 売上明細 values('2021/10/10','青森','いか墨カスター',80);
insert into 売上明細 values('2021/10/10','大阪','たこやき',250);
insert into 売上明細 values('2021/10/10','長崎','長崎カステラ',100);
insert into 売上明細 values('2021/10/10','東京','東京ばなな',200);
insert into 売上明細 values('2021/10/10','奈良','柿の葉寿司',100);
insert into 売上明細 values('2021/10/10','兵庫','ゴーフル',150);
insert into 売上明細 values('2021/10/10','北海道','白い恋人',50);
insert into 売上明細 values('2021/10/11','愛知','ういろう',50);
insert into 売上明細 values('2021/10/11','沖縄','紅芋タルト',250);
insert into 売上明細 values('2021/10/11','岩手','かもめの玉子',230);
insert into 売上明細 values('2021/10/11','宮城','笹かまぼこ',200);
insert into 売上明細 values('2021/10/11','京都','八つ橋',150);
insert into 売上明細 values('2021/10/11','秋田','だまこ餅',300);
insert into 売上明細 values('2021/10/11','青森','いか墨カスター',250);
insert into 売上明細 values('2021/10/11','大阪','たこやき',300);
insert into 売上明細 values('2021/10/11','長崎','長崎カステラ',150);
insert into 売上明細 values('2021/10/11','東京','東京ばなな',250);
insert into 売上明細 values('2021/10/11','奈良','柿の葉寿司',300);
insert into 売上明細 values('2021/10/11','兵庫','ゴーフル',230);
insert into 売上明細 values('2021/10/11','北海道','白い恋人',80);
insert into 売上明細 values('2021/10/12','東京','東京ばなな',150);
insert into 売上明細 values('2021/10/13','大阪','たこやき',230);
insert into 売上明細 values('2021/10/14','京都','八つ橋',50);
insert into 売上明細 values('2021/10/15','兵庫','ゴーフル',80);
insert into 売上明細 values('2021/10/16','愛知','ういろう',50);
insert into 売上明細 values('2021/10/17','北海道','白い恋人',100);
insert into 売上明細 values('2021/10/18','青森','いか墨カスター',200);
insert into 売上明細 values('2021/10/19','秋田','だまこ餅',50);
insert into 売上明細 values('2021/10/20','長崎','長崎カステラ',250);
insert into 売上明細 values('2021/10/21','岩手','かもめの玉子',300);
insert into 売上明細 values('2021/10/22','宮城','笹かまぼこ',150);
insert into 売上明細 values('2021/10/23','沖縄','紅芋タルト',50);
insert into 売上明細 values('2021/10/24','奈良','柿の葉寿司',80);なお、本記事ではフリーのSQL実行ツール「A5 mk2」を利用しています。必要なかたはこちらからダウンロードして下さい。また「A5mk2」を使ってストアドプロシージャを登録する場合、プロシージャモードに変更しておく必要がありますので、ご注意ください。
ストアドファンクション(Stored Function)の書き方とサンプル
ここで説明する内容はストアドファンクションについての事ですが、戻り値を返す部分以外はストアドプロシージャと共通です。
結果を1つだけ返すストアドファンクション
結果を1つだけ返す場合、次のような記述になります。

このサンプルでは WHERE 地域 like '%' || p_area || '%' としていますが、これはSQLの中で文字列を結合する方法を示したかったので、あえて like を使いました。
CREATE OR REPLACE Function summary(p_area varchar)
RETURNS integer
AS $$
DECLARE
v_suryo integer;
BEGIN
SELECT 数量 INTO v_suryo
FROM 売上明細
WHERE 地域 like '%' || p_area || '%';
RETURN v_suryo ;
END;
$$
LANGUAGE plpgsql;select * from summary('大阪') を実行すると以下の結果が返ります。
| summary |
| 250 |
複数の結果を返すストアドファンクション
多くのプログラミング言語では、1つのファンクションから複数の値を返すことができますが、PostgreSQLのストアドの場合は、少し工夫が必要です。
例えば、
CREATE OR REPLACE Function summary(p_area varchar) RETURNS integer ,varchar
という具合に、RETURNS の後に複数の変数を記述したいところですが、残念ながらこれだとエラーになります。
ただ、複数の結果を返せない訳ではなく、次に説明する SETOF を使うか、後述する TABLE を使う必要があります。
複数行を返すストアドファンクション(SETOF)
SETOFと RETURNQUERY VALUES を使うことで、複数の値を行として取り出す事が出来ます。

CREATE OR REPLACE Function summary(p_area varchar)
RETURNS SETOF varchar
AS $$
DECLARE
v_hinmei varchar;
v_suryo varchar;
v_area varchar;
BEGIN
SELECT 品名,数量::varchar,地域
INTO v_hinmei,v_suryo,v_area
FROM 売上明細
WHERE 地域 like '%' || p_area || '%';
RETURN QUERY VALUES (v_area),(v_suryo),(v_area);
END;
$$
LANGUAGE plpgsql;select * from summary('大阪') を実行すると次の結果が得られます。
| summary |
| 大阪 |
| 250 |
| 大阪 |
結果をテーブル形式で返す ストアドファンクション(TABLE)
この記述をすることで、あたかもテーブルからデータを抽出するような結果が得られます。
先ほど、複数の値を返す方法のところで少し触れましたが、このTABLEを使って1行だけ結果を返すようにすれば、先ほどのことは実現可能です。
しかし本当にメリットがあるのは、複雑な入れ子状態でレスポンスが遅くなったVIEWに対して、この方法でストアド化することです。
VIEWに対して検索条件を指定した場合、一旦VIEWに記述されているSQLが実行されてしまうため、VIEWが複雑だったり大量データだった場合、レスポンスが非常に遅くなります。
しかし、ストアドの中で適切に条件を絞り込んであげることで、劇的にレスポンスが改善できます。

ポイントは次の通りです。
- RETURNS TABLE の後に、返したいカラム名を列挙する。
- DECLARE に 実行したいSQLを記述する。
- BEGIN に FOR 文によるループを記述し、その中に RETURN NEXT を記述しておく。
- RETURNS TABLE TABLE に記述した変数にrec の値を代入する。
CREATE OR REPLACE Function summary(p_area varchar)
RETURNS TABLE(
v_date date,
v_area varchar,
v_hinmei varchar,
v_suryo integer
)
AS $$
DECLARE
cur cursor(c_area varchar) for
SELECT t.販売日,t.地域,t.品名,t.数量
FROM 売上明細 t WHERE t.地域 like '%' || c_area || '%';
BEGIN
FOR rec IN cur(p_area) LOOP
v_date := rec.販売日;
v_area := rec.地域;
v_hinmei := rec.品名;
v_suryo := rec.数量;
RETURN NEXT;
END LOOP;
RETURN;
END;
$$
LANGUAGE plpgsql;
このストアドファンクションに対して select * from summary('大阪') を実行すると、次の結果が返ります。
| v_date | v_area | v_hinmei | v_suryo |
| 2021/10/10 | 大阪 | たこやき | 250 |
| 2021/10/11 | 大阪 | たこやき | 300 |
| 2021/10/13 | 大阪 | たこやき | 230 |
ループを使ったデータの取得方法として、FOR の他に FETCH があります。
FETCH は無条件ループ(LOOP~END LOOP)の中で使い、データが無くなったことで発生するイベント(EXTI WHENNOT FOUNT)を受けてループを抜けるような記述になります。
上記のソースコードのBEGIN~ENDの部分を、下記に置き換えることで、FETCH を使ったデータ取得が可能になります。
どちらを使っても良いのですが、
FETCH cur INTO 変数1,変数2,変数3,・・・
という具合に FOR を使う時よりもデータの取得部分が簡素化できるというメリットがあります。

CREATE OR REPLACE Function summary(p_area varchar)
RETURNS TABLE(
v_date date,
v_area varchar,
v_hinmei varchar,
v_suryo integer
)
AS $$
DECLARE
cur cursor(c_area varchar) for
SELECT t.販売日,t.地域,t.品名,t.数量
FROM 売上明細 t WHERE t.地域 like '%' || c_area || '%';
BEGIN
OPEN cur(p_area);
LOOP
FETCH cur INTO v_date,v_area,v_hinmei,v_suryo;
EXIT WHEN NOT FOUND;
RETURN NEXT;
END LOOP;
CLOSE cur;
RETURN;
END;
$$
LANGUAGE plpgsql;引数に配列を渡す場合のストアドファンクション
引数に配列を渡す場合、引数の型の後ろに[] を付けます
ストアド名(変数名 変数の型[],・・・・)
下記のサンプルでは、p_area に varchar[] を指定しています。
受取った配列をどのように処理するかについては、いくつか方法があるので、それぞれについて解説したいと思います。
FOR IN を使う方法
配列の個数は array_length関数で取得できるので、次のように記述出来ます。
FOR n IN 1..array_length(配列の変数名, 配列の次元数 ) LOOP
今回は1次元配列を使っていますので array_length(p_area,1) になっています。
ちなみに、配列の添え字は1から始まります。

CREATE OR REPLACE Function summary(p_area varchar[])
RETURNS TABLE(
v_date date,
v_area varchar,
v_hinmei varchar,
v_suryo integer
)
AS $$
DECLARE
cur cursor(c_area varchar) for
SELECT t.販売日,t.地域,t.品名,t.数量
FROM 売上明細 t WHERE t.地域 like '%' || c_area || '%';
BEGIN
FOR n IN 1..array_length(p_area,1) LOOP
FOR rec IN cur(p_area[n]) LOOP
v_date := rec.販売日;
v_area := rec.地域;
v_hinmei := rec.品名;
v_suryo := rec.数量;
RETURN NEXT;
END LOOP;
END LOOP;
RETURN;
END;
$$
LANGUAGE plpgsql;
select * from summary(array['大阪','東京']) を実行すると、次の結果が得られます。
| v_date | v_area | v_hinmei | v_suryo |
| 2021/10/10 | 大阪 | たこやき | 250 |
| 2021/10/11 | 大阪 | たこやき | 300 |
| 2021/10/13 | 大阪 | たこやき | 230 |
| 2021/10/10 | 東京 | 東京ばなな | 200 |
| 2021/10/11 | 東京 | 東京ばなな | 250 |
| 2021/10/12 | 東京 | 東京ばなな | 150 |
FOREACHを使う方法
配列のループについては、FOREACHを使って次のように記述することも可能です。
FOREACH 値を受取る変数名 IN array 配列の変数名 LOOP
上記の方がスマートかもしれませんが、値を受取る変数名をDECLAREに定義する必要があるので、それが面倒な場合は、前述の FOR を使う方が良いかもしれません。
以下はFOREACHで書き直したものです。
CREATE OR REPLACE Function summary(p_area varchar[])
RETURNS TABLE(
v_date date,
v_area varchar,
v_hinmei varchar,
v_suryo integer
)
AS $$
DECLARE
cur cursor(c_area varchar) for
SELECT t.販売日,t.地域,t.品名,t.数量
FROM 売上明細 t WHERE t.地域 like '%' || c_area || '%';
v_area varchar;
BEGIN
FOREACH v_area IN array p_area LOOP
FOR rec IN cur(v_area) LOOP
v_date := rec.販売日;
v_area := rec.地域;
v_hinmei := rec.品名;
v_suryo := rec.数量;
RETURN NEXT;
END LOOP;
END LOOP;
RETURN;
END;
$$
LANGUAGE plpgsql;anyを使う方法
配列を使ってループを回すのではなく、in (値1,値2,値3,・・・)のような書き方で 配列が利用できれば便利です。
残念ながらそのような記述はできませんが、代わりに any を使って次のように書くことができます。
select * from hoge where name = any(配列名)
これを使って書き直すと次のようになります。
CREATE OR REPLACE Function summary(p_area varchar[])
RETURNS TABLE(
v_date date,
v_area varchar,
v_hinmei varchar,
v_suryo integer
)
AS $$
DECLARE
cur cursor(c_area varchar[]) for
SELECT t.販売日,t.地域,t.品名,t.数量
FROM 売上明細 t WHERE t.地域 = any(c_area);
BEGIN
FOR rec IN cur(p_area) LOOP
v_date := rec.販売日;
v_area := rec.地域;
v_hinmei := rec.品名;
v_suryo := rec.数量;
RETURN NEXT;
END LOOP;
RETURN;
END;
$$
LANGUAGE plpgsql;
ストアドプロシージャ(Stored Procedure)の書き方とサンプル
戻り値の無いストアドファンクション=ストアドプロシージャになりますので、細かい記述方法はストアドファンクションの章を見ていただくとして、ここではストアドプロシージャに特化した内容について解説します。
Aテーブルの内容を使ってBテーブルを更新する
ストアドプロシージャは戻り値が無いため、INSERT、UPDATE、DELETE を使ったデータの更新処理が中心になります。
例えば、売上明細テーブルからデータを抽出し、集計表テーブルを更新する場合は、次の様に記述します。
下記のサンプルでは、売上明細テーブルからFETCHを使っていますが、もちろんFORを使っても構いません。

ここでは INSERT を1行分だけ実行していますが、同時にUPやDELETEを実行することも可能です。
CREATE OR REPLACE PROCEDURE area_summary(p_area varchar)
AS $$
DECLARE
v_area varchar;
v_sum integer;
cur cursor(c_area varchar) for
SELECT t.地域,sum(t.数量)
FROM 売上明細 t
WHERE t.地域 = c_area
GROUP BY t.地域;
BEGIN
OPEN cur(p_area);
LOOP
FETCH cur INTO v_area,v_sum;
EXIT WHEN NOT FOUND;
INSERT INTO 集計表(地域,数量) values(v_area,v_sum);
END LOOP;
CLOSE cur;
END;
$$
LANGUAGE plpgsql;call area_summary('大阪') でストアドプロシージャを実行すると、集計表には次の値が挿入されます。
| 地域 | 数量 |
| 大阪 | 780 |
上記ストアドプロシージャを2回実行すると、重複キーエラー(一意制約例外)になりますのでご注意下さい。
動的SQLを使ったストアドのサンプル
動的SQLとは
ストアドにSQLを記述する場合、そのSQLは外部から変更できませんから固定になります。
しかし、例えばAテーブルの内容を見てSQLを変えたい場合、IF文を多用する必要があり、処理が煩雑になります。
あるいは、Aテーブルの特定カラムに登録されている文字列をSQLとして実行したい場合は、今までのストアドの書き方だと実現出来ません。
この様な場合、SQLの文法で書いた文字列を、SQLとして解釈して実行してくれたら便利ですよね。
これが動的SQLです。

文字列をSQLとして解釈して実行するには EXECUTE を使います
Aテーブルの内容を使って動的SQLでBテーブルを更新する
では、先ほどのストアドプロシージャのINSERT部分を、動的SQLに書き換えると次の様になります。
EXECUTEに続けてINSERT文を文字列として渡していますので、売上明細テーブルから取得した値はSQLの文字列連結方法に従っています。

CREATE OR REPLACE PROCEDURE area_summary(p_area varchar)
AS $$
DECLARE
v_area varchar;
v_sum integer;
v_sql varchar;
cur cursor(c_area varchar) for
SELECT t.地域,sum(t.数量)
FROM 売上明細 t
WHERE t.地域 = c_area
GROUP BY t.地域;
BEGIN
OPEN cur(p_area);
LOOP
FETCH cur INTO v_area,v_sum;
EXIT WHEN NOT FOUND;
EXECUTE 'INSERT INTO 集計表(地域,数量) values(''' || v_area || ''',' || v_sum || ')';
END LOOP;
CLOSE cur;
END;
$$
LANGUAGE plpgsql;call area_summary('京都') を実行すると、集計表テーブルは次の結果になります。
| 地域 | 数量 |
| 京都 | 500 |
動的SQLでAテーブルの内容を取得し、動的SQLでBテーブルを更新する
今度は、取得元と更新先の両方について動的SQLを使ったサンプルです。
BEGINの中にSQLを書くと煩雑になるので、DECLARE に記述しています。
また、今回は format 関数を使って、SQLの文字列に引数を埋め込むようにしました。
尚、like ''%s'' や values(''%s'',%s) の '' はダブルクォートではなく、シングルクォート2つ並べています。SQLの文字列はシングルクォートで括るので、その中にシングルクォートを書く場合は2つ並べてエスケープする必要があります。

CREATE OR REPLACE PROCEDURE area_summary(p_area varchar)
AS $$
declare
v_area varchar;
v_sum integer;
v_sql1 varchar := 'select 地域,sum(数量) from 売上明細 where 地域 like ''%s'' group by 地域';
v_sql2 varchar := 'INSERT INTO 集計表(地域,数量) values(''%s'',%s)';
cur refcursor;
BEGIN
OPEN cur for EXECUTE format(v_sql1,p_area);
LOOP
FETCH cur INTO v_area,v_sum;
EXIT WHEN NOT FOUND;
EXECUTE format(v_sql2,v_area,v_sum);
END LOOP;
CLOSE cur;
END;
$$
LANGUAGE plpgsql;例外処理
ストアドプロシージャ/ファンクションの中で、予期せぬエラー(例外)が発生した場合、次の記述で例外を補足し、対処することができます。
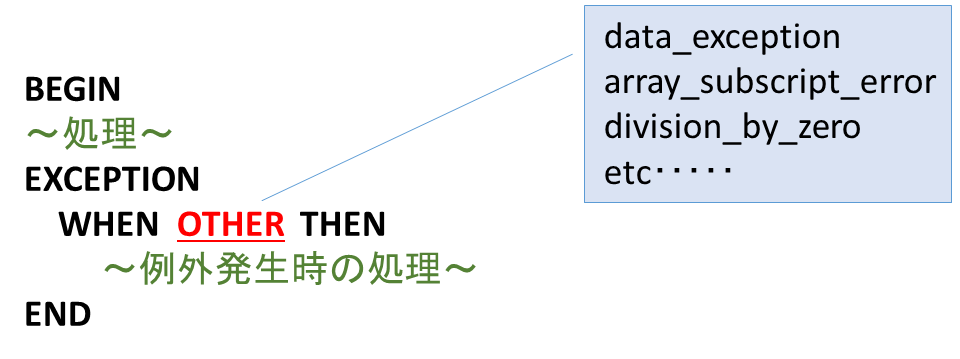
例外処理は1つのプロシージャ内にいくつでも記述することが可能で、WHEN~THEN により特定の例外のみを補足することができます。すべての例外を補足したい場合は、OTHER を指定します。
また、特定の例外だけを特別に処理したい場合は次の様に書くことができます。

PostgreSQLには100種類以上の例外が用意されていますので、詳しくは公式ページをご確認下さい。バージョンは少し古いですが、これより新しい情報が見つからなかったので、おそらく今も変わっていないのだろうと思います。
プロシージャの中で例外処理を行った場合、呼び出し側には例外は通知されません。呼び出し側にも例外を通知したい場合は、明示的に RAISE を記述します。
次の例は、何らかの例外が発生した場合、RAISEを使って呼び出し側に例外を通知するサンプルです。
CREATE OR REPLACE FUNCTION one_summary(p_area varchar,p_sum int)
RETURNS numeric
LANGUAGE plpgsql
AS $function$
DECLARE
BEGIN
BEGIN
DELETE FROM 集計表 WHERE 地域 = p_area;
INSERT INTO 集計表(地域,数量) values(p_area,p_sum);
EXCEPTION
WHEN others THEN
RAISE;
END;
RETURN 0;
END;
$function$トランザクション制御
トランザクション制御は、更新処理が完了しない間に例外が発生することにより、データが中途半端な更新状態になることを防ぎます。
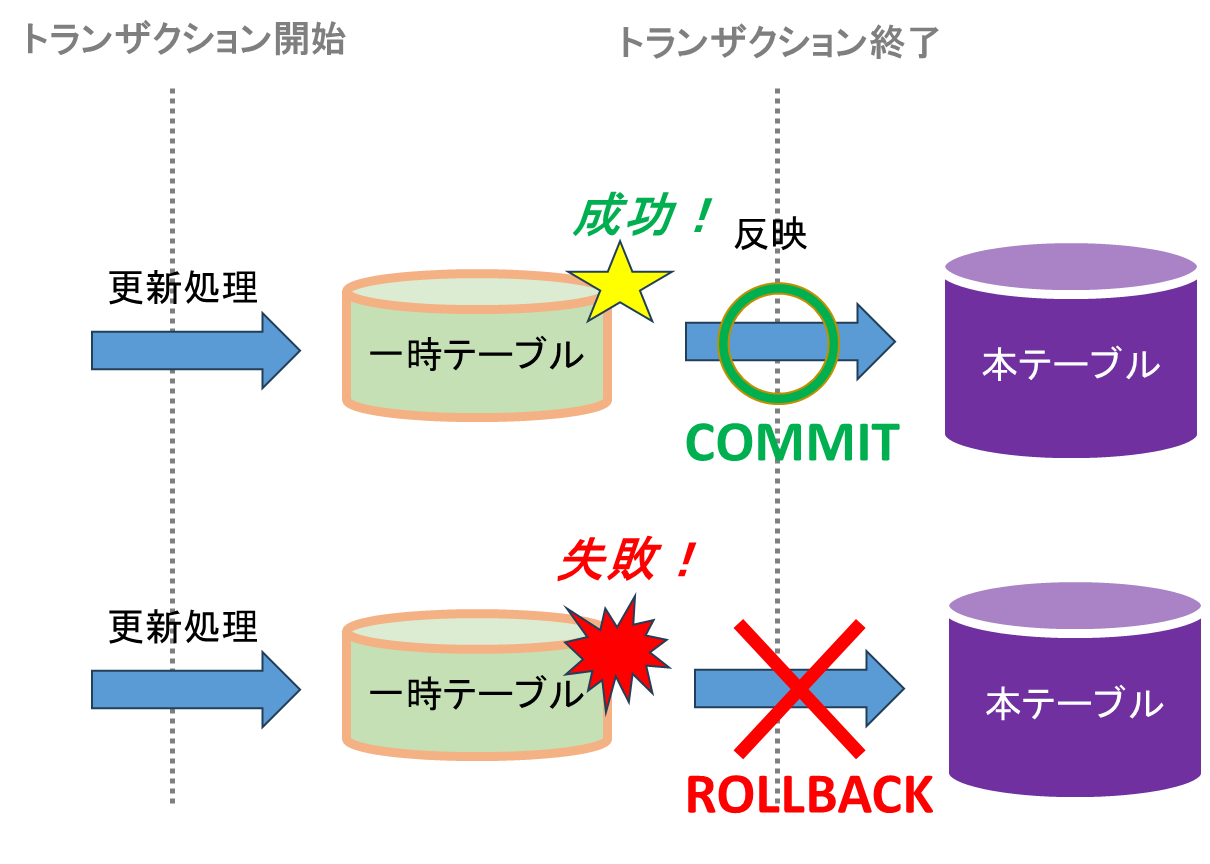
トランザクションを開始すると、その後の更新内容は一時テーブルに保存されます。そして、トランザクションを終了させた時に、一時テーブルの内容が本番テーブルに反映されます。
もし、例外が発生した場合は、一時テーブルの内容を破棄し、本テーブルへの反映は行われません。
トランザクション制御を行うには、トランザクションの開始と終了を明示的に指定する必要があります。
また、トランザクション終了時は、一時テーブルの内容を本テーブルに反映させるか、あるいは破棄するかのどちらかを指定しなければなりません。
PostgreSQLの場合は、トランザクションの開始は BEGIN 、終了は END を記述し、例外が発生した場合は ROLLBACKを記述します。そして、COMMITは明示的に記述しません。

次のサンプルは、前述した area_summary にDELETE文とトランザクション制御を実装したものです。
前述のarea_summary は2回目の実行で重複キーエラー(一意制約例外)が発生しましたが、DELETE文を追加することで解決しています。
CREATE OR REPLACE PROCEDURE area_summary(p_area varchar)
AS $$
DECLARE
v_area varchar;
v_sum integer;
cur cursor(c_area varchar) for
SELECT t.地域,sum(t.数量)
FROM 売上明細 t
WHERE t.地域 = c_area
GROUP BY t.地域;
BEGIN
BEGIN
OPEN cur(p_area);
LOOP
FETCH cur INTO v_area,v_sum;
EXIT WHEN NOT FOUND;
-- トランザクション内で削除を行う
DELETE FROM 集計表 WHERE 地域 = p_area;
-- トランザクション内でインサートを行う
INSERT INTO 集計表(地域,数量) values(v_area,v_sum);
END LOOP;
CLOSE cur;
EXCEPTION
-- トランザクションが失敗した場合はロールバック
WHEN others THEN
-- ロールバック
ROLLBACK;
END;
END;
$$
LANGUAGE plpgsql;PostgreSQLでトランザクション処理を行う場合、次の制約があることは覚えておきましょう。
- トランザクション制御は入れ子にできない。
- ストアドプロシージャ/ファンクションに親子関係がある場合、トランザクション制御は親でしか使えない。

一般的には親でトランザクション制御を行い、子はトランザクション制御を行わないものなので特に問題はありませんが、たまに子でログ出力させたい場合もあります。この場合は親のロールバックによりログ出力も破棄されるため、子で例外処理を行い、親には戻り値で通知するなどの工夫が必要になります。
まとめ
今回はPostgreSQL のストアドファンクション、ストアドプロシージャについて、
- 前提となる基礎知識
- ストアドファンクションの書き方とサンプル
- ストアドプロシージャの書き方とサンプル
- 動的SQLの使い方
- 例外処理
- トランザクション制御
について解説致しました。
色々な書き方がありますが、まずはこの記事の内容をテンプレートとして使っていただければ、一通りの事は出来ると思います。
今までいろいろなサイトを見て理解しようとして、今一理解できなかった方に対して、この記事が手助けになれば幸いです。








コメント