時系列データを使った分析では、しばしば移動平均を計算する必要に迫られます。
python には移動平均を簡単に計算できる方法が用意されていますので、今回はそれについて解説します。
pandas と numpy のどちらでも可能なので、両方を載せておきます。
pandasで移動平均
pandas で移動平均を計算するには rolling メソッドを使います。
rolling(データ個数).mean()
例えば、5個のデータで移動平均を求める場合は、次の様に記述します。
import pandas as pd
data = pd.Series([1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
print('移動平均',data.rolling(5).mean())結果は以下の通りです。
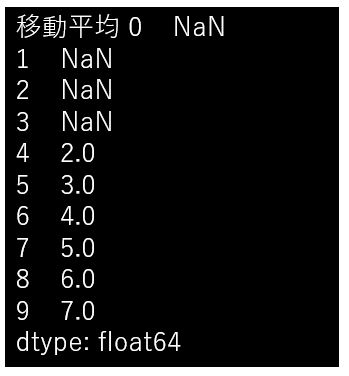
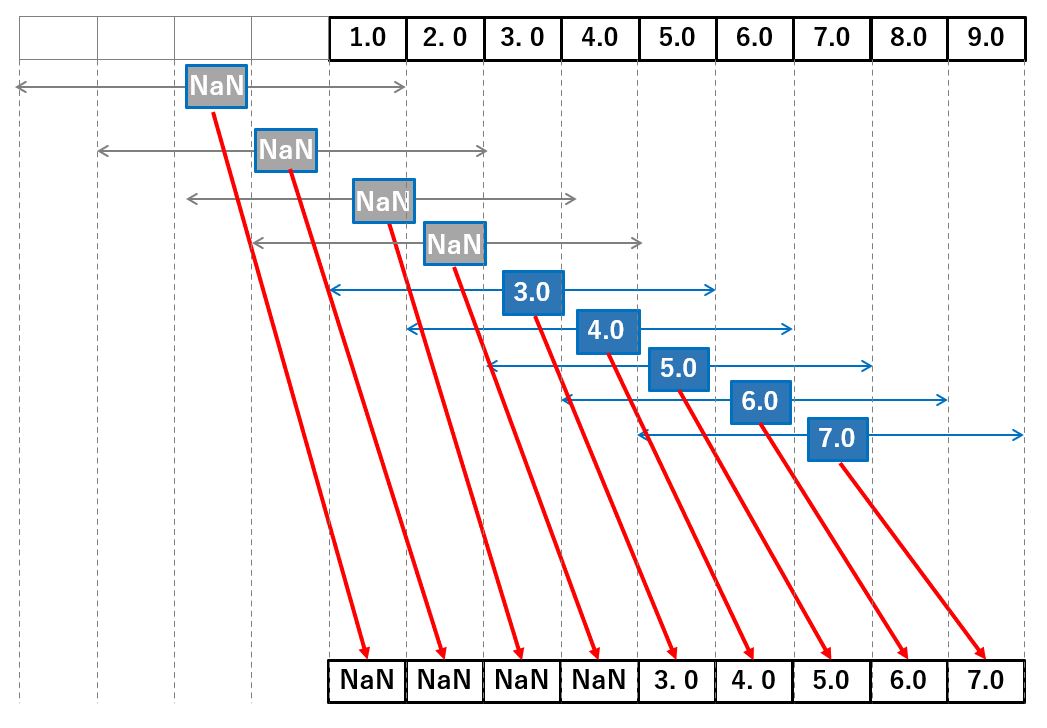
今回は5個のデータで移動平均を算出しているため、データが5個揃うまでは平均値が計算がされず、その結果 NaN が先頭に埋められています。
rolling には、続けて apply(関数) を指定することで、任意の関数を適用することが可能です。
下記の様rに、平均を求める関数を用意することで、同じことが実現できます。
def func(x):
return x.mean()
print(data.rolling(5).apply(func))
#又はラムダ式を使って下記の様にも書ける
print(data.rolling(5).apply(lambda x: x.mean()))numpy で移動平均
numpy で移動平均を計算する場合、convoluve メソッドを使います。
convolve(データ,np.ones(個数), mode='valid') / 個数
もともと、この convoluve メソッドは畳み込み用のメソッドなのですが、移動平均でも利用されています。
np.ones() は引数で指定した個数の配列を作るメソッドで、値は全て1.0 が格納されます。
convoluve は、第一引数で渡されたデータと np.ones() で作成した配列の値で内積の和を順次計算していくので、np.onse()の値を個数分で割るか、convoluve の戻り値を個数分で割ることで、結果的に移動平均を求めることが出来ます。
pandas の移動平均では、先頭の部分は値が揃わないため NaN が出力されていましたが、convoluveでは mode='valid' を指定することで、値が揃った位置から計算をしてくれるため、先頭の NaN は入りません。
以下は、5個の移動平均を求めるサンプルです。
import numpy as np
data = np.array([1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
#np.ones()の値を個数で割る方法
print('移動平均',np.convolve(data,np.ones(5)/5, mode='valid'))
#convolveが返す結果を個数で割る方法
print('移動平均',np.convolve(data,np.ones(5), mode='valid') / 5)結果は次のようになります。
移動平均 [3. 4. 5. 6. 7.]
pandas の時と同じ答えが返ってきています。
bottleneck による移動平均
bottleneck というモジュールにも移動平均のメソッドが用意されています。
これは
import numpy as np
import bottleneck as bn
data = np.array([1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
print('移動平均',bn.move_mean(data, window=5))結果は以下の通りです。
移動平均 [nan nan nan nan 3. 4. 5. 6. 7.]
どれが一番速いか
今回紹介した方法で、どれが一番速いかを簡単に調べてみました。
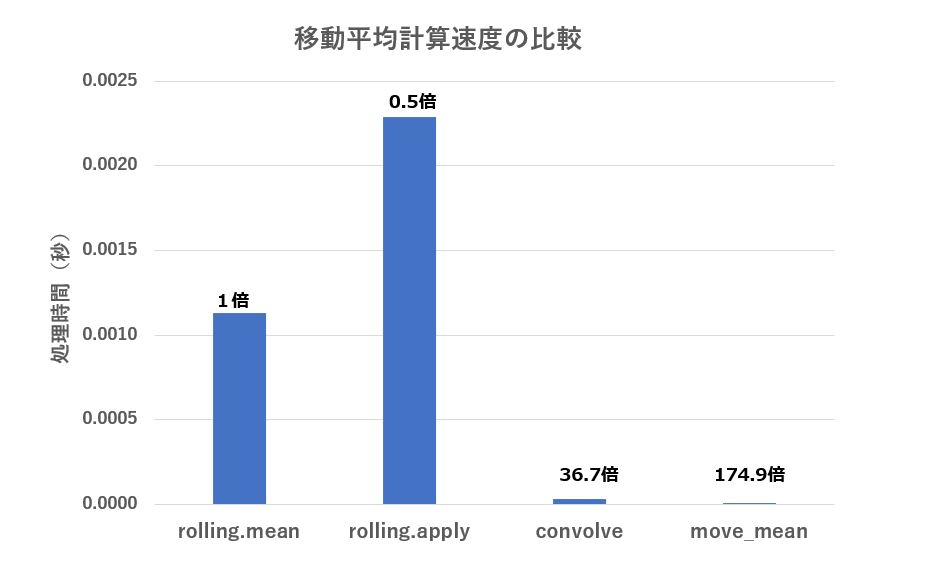
その結果、move_mean がダントツで、次に convolve 、3番目は rolling.mean、一番遅いのはrolling.apply という結果でした。
| メソッド | 処理時間(秒) | rolling.meanを1とした倍率 |
|---|---|---|
| rolling.mean | 0.001130 | 1 |
| rolling.apply | 0.002287 | 0.49 |
| convolve | 0.000031 | 36.67 |
| move_mean | 0.000006 | 174.88 |
今回は非常に小さなデータで試したので、あくまでも参考値として見ていただければと思います。
#rolling.mean
data = pd.Series([1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
data.rolling(5).mean()
#rolling.apply
data = pd.Series([1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
data.rolling(5).apply(lambda x: x.mean())
#convolve
data = np.array([1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
np.convolve(data,np.ones(5), mode='valid') / 5
#move_mean
data = np.array([1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0])
bn.move_mean(data, window=5)まとめ
今回は移動平均について、pandas で2 種類 、nampy で1 種類 、bottleneck で1 種類 の合計4種類について、具体的な使い方を解説致しました。
処理速度についても、bottleneckの move_mean() が最も高速でしたが、よほど大量のデータに対して移動平均を何度も計算するような場合でなければ、pandas でも全く問題が無いと思います。
今回の記事が皆さんのお役に立てれば幸いです。








コメント