前回の記事では、Stable Diffusion Web UI のインストール方法について解説しました。
今回は、モデルファイルをダウンロードして、Stable Diffusion Web UI で使えるようにするまでの手順を解説します。
他のサイトではあまり紹介されていない「ボタン一発で完了するプロンプトの入力方法」や、「プロンプトの登録&呼び出し方法」についても詳しく解説しますので、これから Stable Diffusion Web UI を使おうと思っている方は、是非ご一読ください。
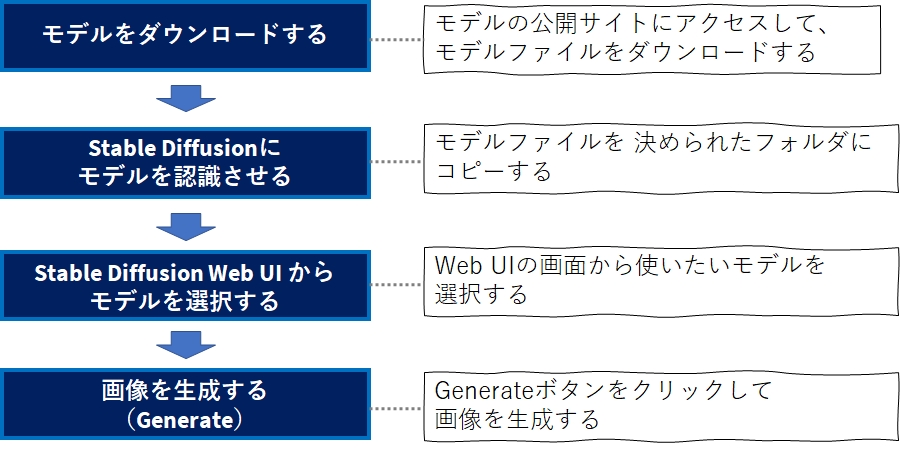
モデルのダウンロードから使えるようになるまでの手順
本記事では、4つのステップについて順を追って紹介します。
モデルのダウンロードで知っておくべきこと
Stable Diffusion で使えるモデルの種類について簡単に解説しておきます。
モデルには大きく分けて2種類が存在します。
1つは Checkpoint とよばれる数GBのファイルで、これが正真正銘のモデルファイルになります。
もう1つは、モデルファイルに対して、別の要素を追加学習させた差分ファイル(追加学習ファイル)のことで、最近脚光を浴びている LoRA(Low-Rank Adaptation)がこれに該当します。
LoRAは、特定の人物や背景、服装、ポーズなど、様々なものが用意されており、1つのモデルファイルに対して、いくつも適用することが可能です。

モデルファイル、LoRAとも、拡張子は同じですが、ファイルのサイズが1桁ほど異なるので、これで区別することは可能です。
ちなみに、拡張子 *.ckpt は任意のコードが実行できるためセキュリティ的に危険です。もし同じモデルで*.safetensorsが用意されていれば、こちらを使うようにしましょう。
| 拡張子 | ファイルサイズ | |
|---|---|---|
| モデルファイル | *.safetensors *.ckpt | 数GByte |
| 追加学習ファイル | *.safetensors *.ckpt *.lora | 数百MByte |
モデルのダウンロードサイトに掲載されるサンプル画像の中には、特定の追加学習ファイル(LoRA)を使用しているものも存在します。
サンプル画像に限りなく近づけたい場合は、LoRAファイルも併せてダウンロードしておきましょう。
モデルをダウンロードする
モデルのダウンロードサイトは2つあります。1つは、civitai もう1つは Hugging Face です。
どちらのサイトもユーザー登録しなくてもモデルのダウンロードは可能ですが、civitai に関しては一部のサンプル画像に「ぼかし」が掛かっており、それを解除したい場合はユーザー登録が必要となります。
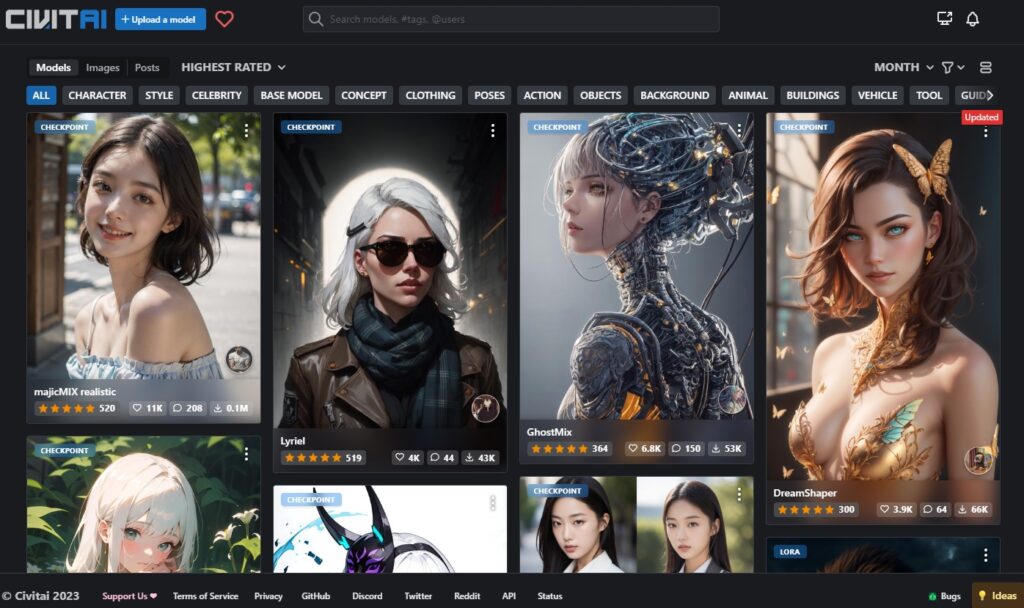
civitai は、モデルごとの生成画像がサムネイル形式で表示されているため、画像を見ながら直感的にモデルを探すのに適しています。
一方、hugging face はモデルがテキスト形式で一覧表示されているため、モデル名またはモデル名の一部で検索したい場合に利用します。
もちろん civita でも検索することは可能ですが、モデルによってはどちらか一方のサイトにしか登録されていない事もあるので、両方のサイトが必要になります。
civitai からのダウンロード
サムネイルを見ながら画面をスクロールし、気に入った画像が見つかったらそれをクリックします。するとダウンロードページに移動しますので、画面右上の「Download」ボタンをクリックします。
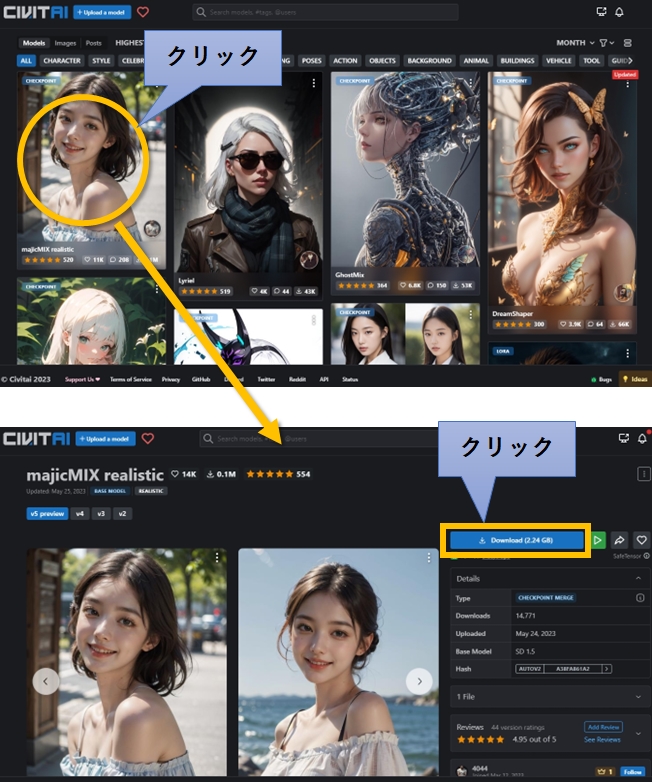
モデルファイルは数GBもあるので、ディスク容量には気を付けてください。
また、表示されるサムネイル画像はモデルファイルだけでなく、LoRAも含まれています。LoRAだけでは画像生成できませんのでご注意ください。

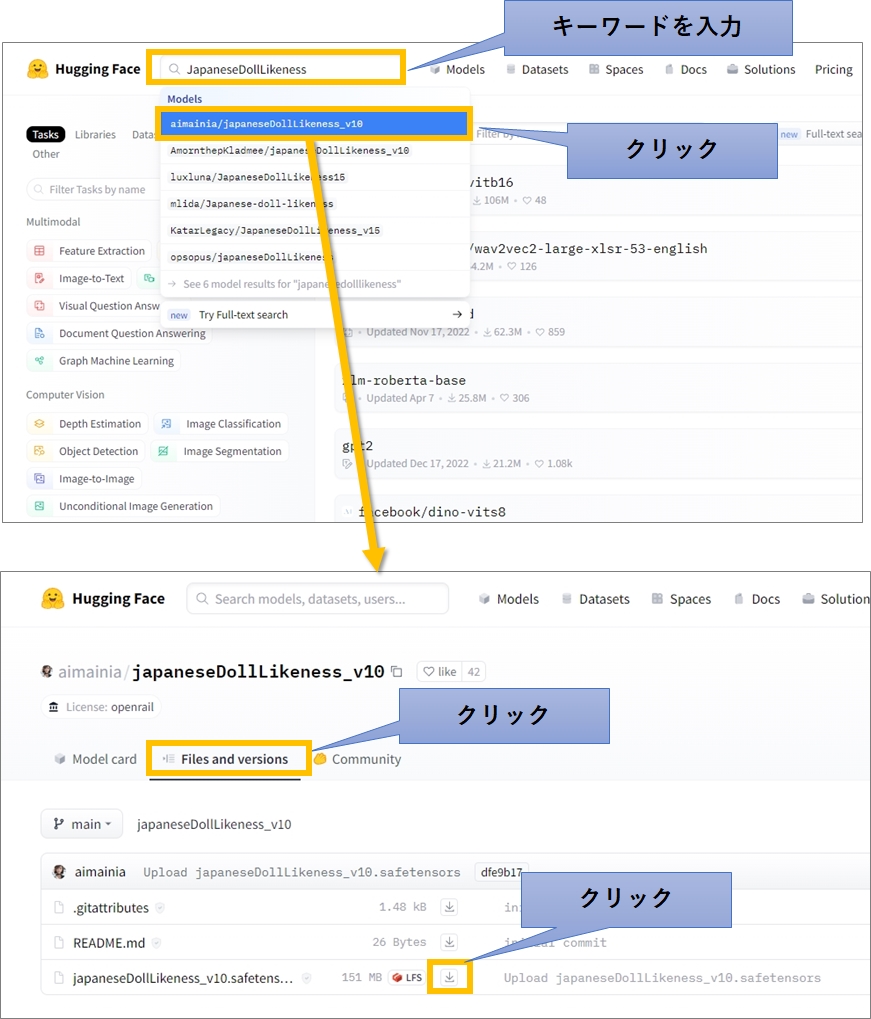
hugging face からのダウンロード
検索したいキーワード(モデル名など)を入力すると、候補がドロップダウンリストに表示されます。該当のものが見つかったら、クリックします。
すると、ダウンロードページが表示されるので「Files and versions」タブをクリックし、画面下に表示されるモデルファイルのリンクをクリックすれば、ダウンロードできます。
Stable diffusion にモデルを認識させる
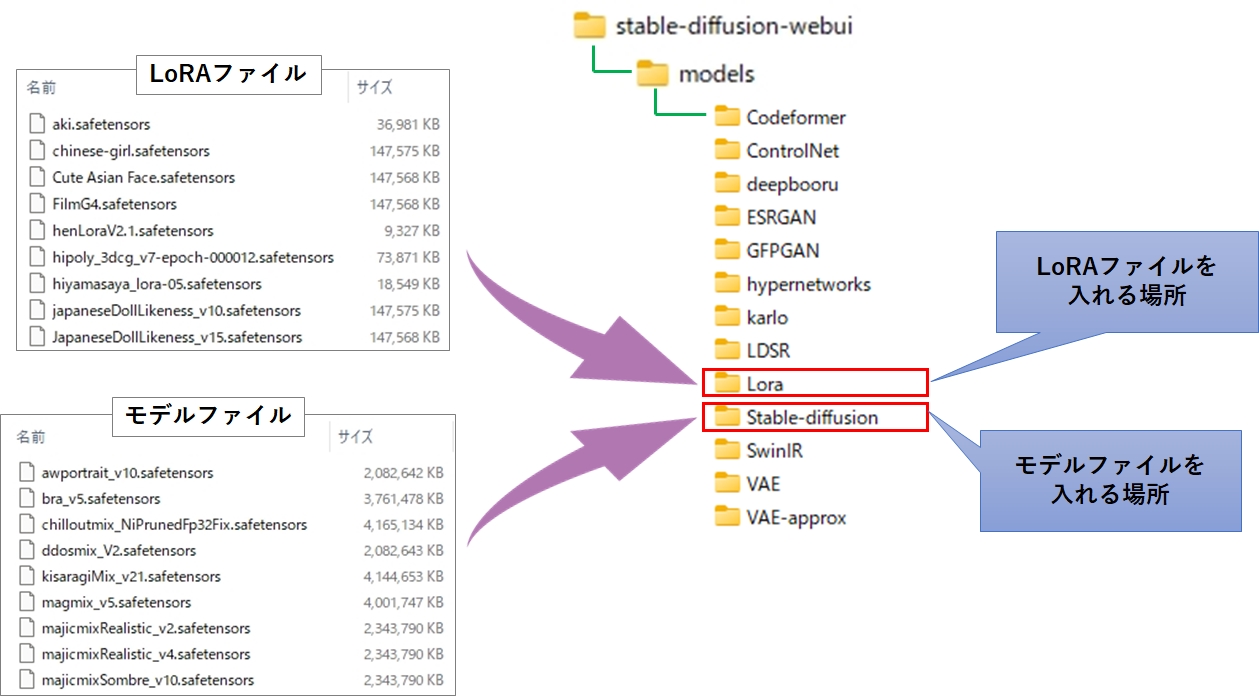
Stable Diffusion にモデルファイル、LoRAファイルを認識させるには、以下の手順を実行します。
- モデルファイル → modelsフォルダ直下のStable-diffusion フォルダにコピー
- (必要に応じて)LoRAファイル → modelsフォルダ直下のLora フォルダにコピー
- Stable Diffusion の「checkpointリフレッシュボタン」クリック
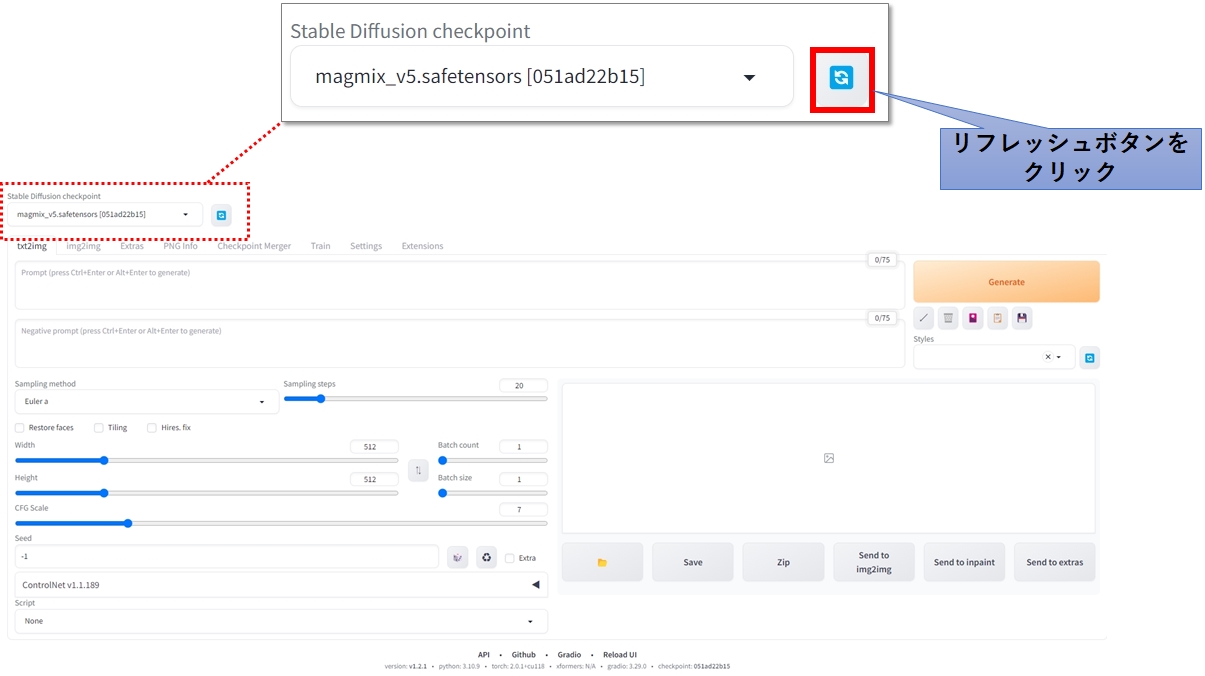
Stable Diffusion の「CheckPointリフレッシュボタン」は下記の場所にあります。この操作により、ドロップダウンリストからモデルファイルが選択できるようになります。
尚、表示されるのはモデルファイルのみで、LoRAファイルはここには表示されませんのでご注意ください。
モデルを選択する
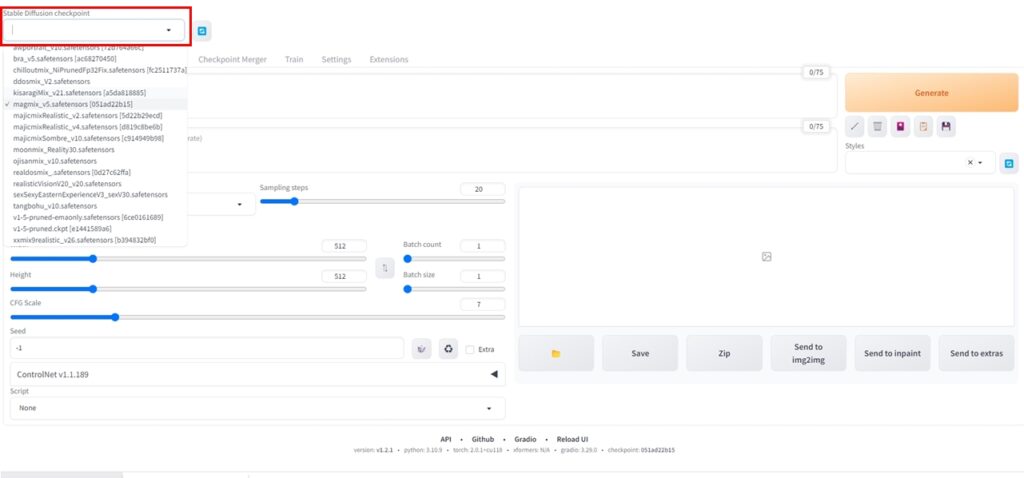
Stable Diffusion checkpoint のドロップダウンリストから、モデルを選択します。
画像を生成する
モデルを選んで 「Generate」ボタンをクリックすると、数秒後(PCによっては数分後)に画像が生成されます。
ちなみに、縦512×横512の画像を1枚だけ生成する場合、 ミドルクラスのゲーミングPCだと数秒から十数秒、エントリーモデルなら数分、ビデオカードを搭載しないビジネスパソコンの場合は十数分程度掛かります。
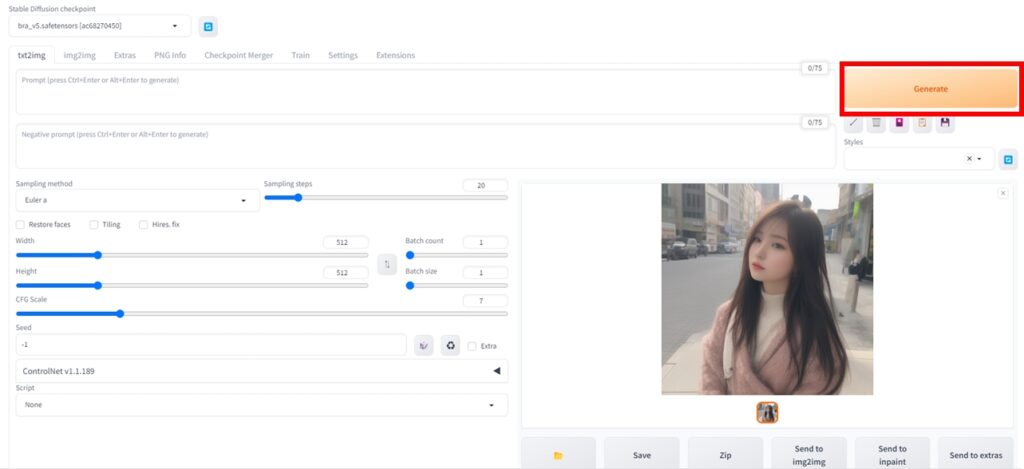
参考までに、私のメインPC(CPU:Core-i5 13400 メモリ:32GB GPU:RTX-3060)で生成させた場合、1枚5秒程で生成できました。
便利機能の紹介
Stable Diffusion Web UI の機能は非常に豊富で奥が深いため、全てを説明することはできません。そこで、本記事では知っておくと便利な機能について紹介したいと思います。
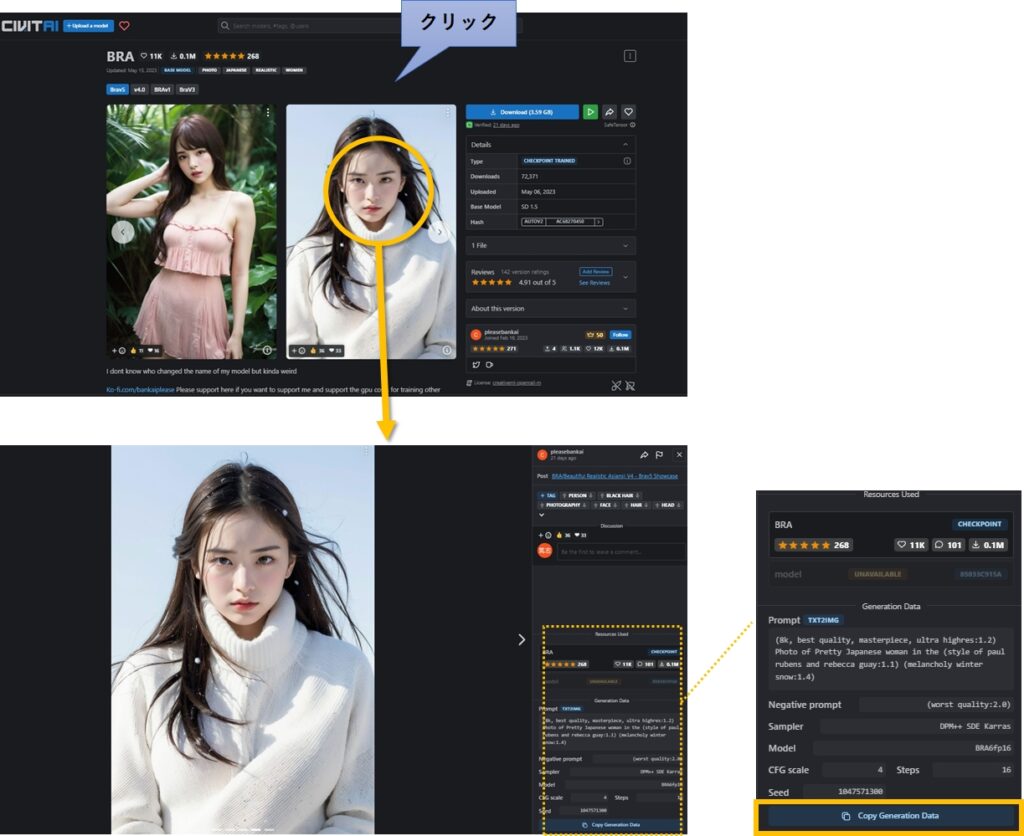
civitaのサンプル画像を「Copy Generation Data」で再現する方法
モデルのダウンロードページに移動し、表示されるサンプル画面の中から再現したいサンプル画像をクリックします。
すると右下(破線部分)に設定情報が表示されるので、「Copy Generation Data」をクリックして下さい。
次に、Stable Diffusion Web UI に戻って、プロンプト入力欄にCtrl+Vでペーストし、斜め線(実際は矢印マーク)をクリックしてください。
これでペーストした設定情報が、各設定個所に反映されます。あとはGenerateボタンをクリックして画像を生成します。
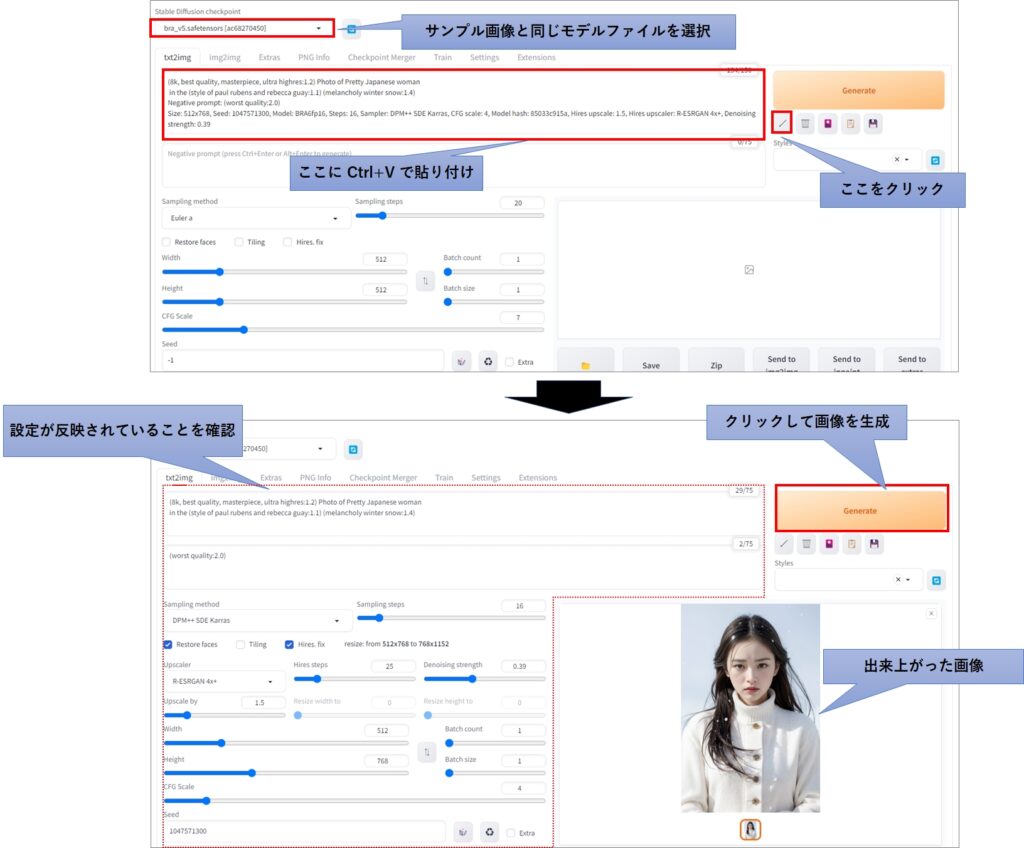
最初に断っておきますが、実際に100%再現できるわけではありません。中には再現できるものもありますが、多くの場合は服装が異なったり、ポーズが異なったりします。
今回の例で取り上げたサンプル画像と、生成された画像を見比べると、雪の分布や大きさ、服装が異なっていることがお分かりいただけるでしょう。
この状態ではGenerateボタンを何度クリックしても、同じ画像しか生成しません。画像を変えたい場合はプロンプトの文字列を変更するか、他の設定を変更してください。
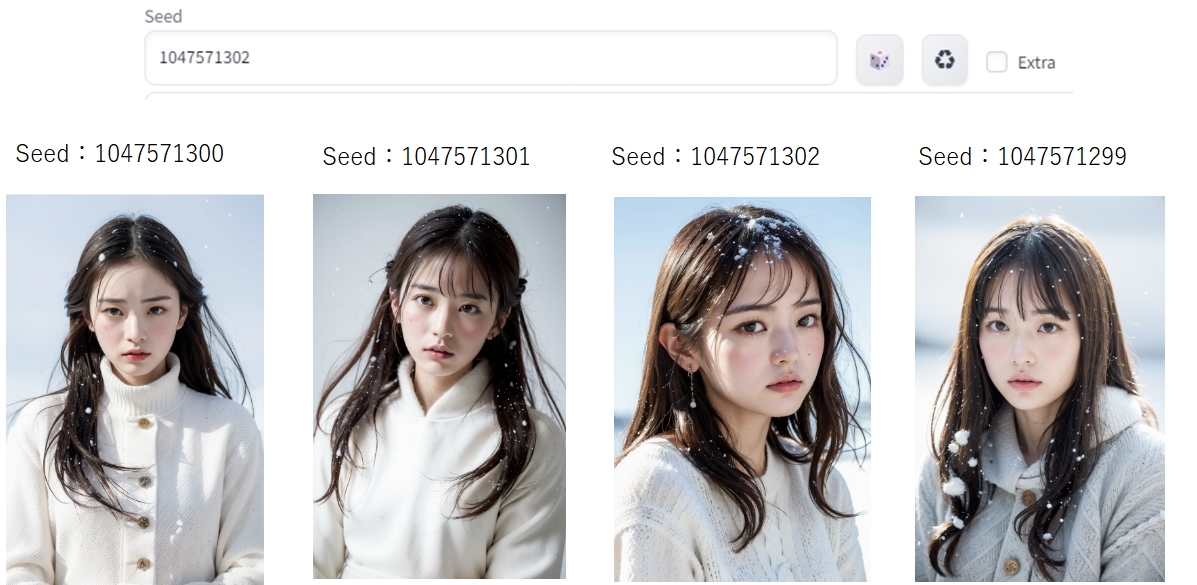
たとえば、サンプル画像のSeed値は1047571300でしたが、値を少し変更するだけで、色々なバリエーションを生成してくれます。
生成した画像からプロンプトなどの設定情報(パラメータ)を取得する方法
Stable Diffusion Web UI のタブから PNG Info を選択します。

次に、設定情報を表示した画像をドラッグ&ドロップしてください。すると、この画像を作った時の設定情報(パラメータ)が右側に表示されます。
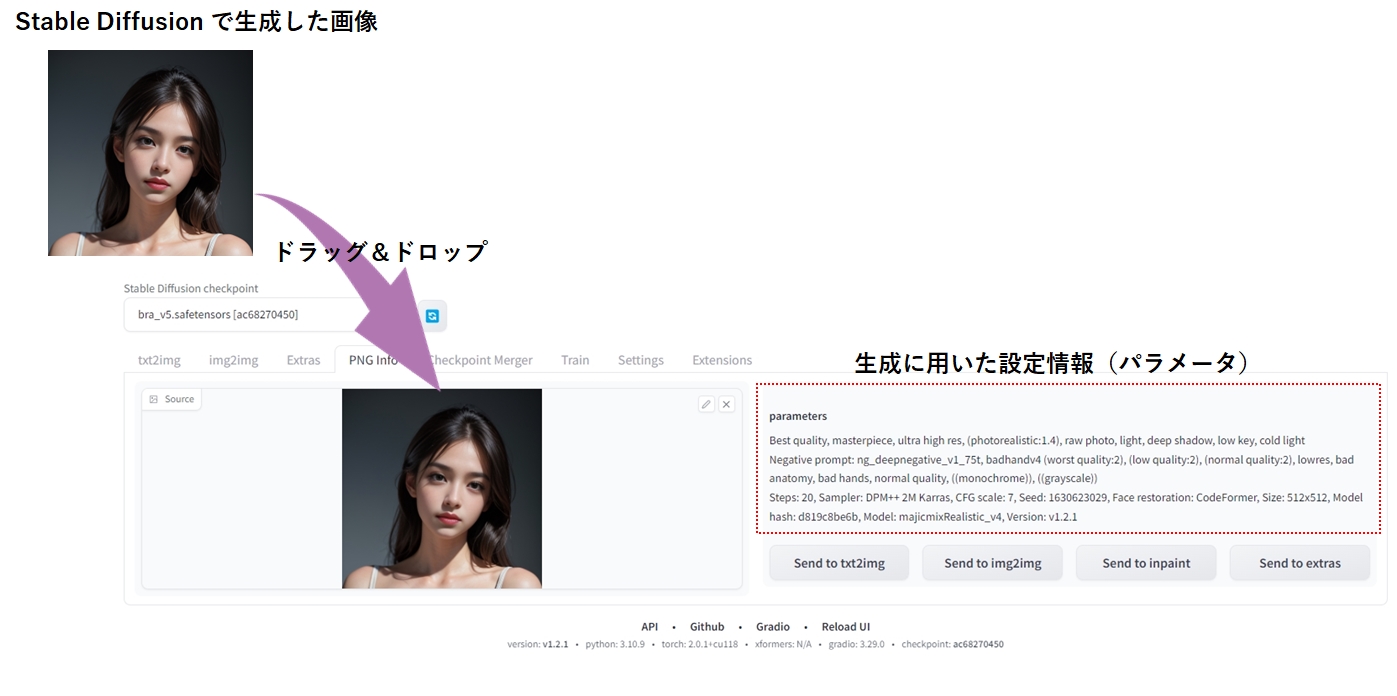

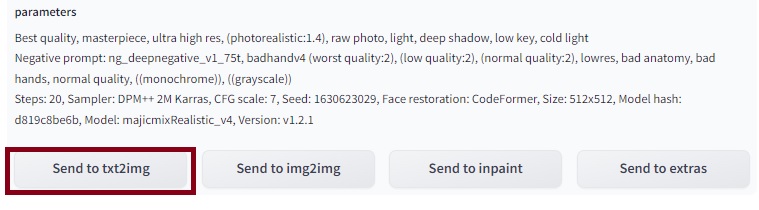
設定情報はCIVITAIのCopy Generation Dataと同様のフォーマットになっているため、「txt2Img」のタブにあるプロンプトに張り付けて、斜め線(実際は矢印マーク)をクリックれば設定の復元は可能ですが、この画面には「Send to txt2img」ボタンが用意されているので、これをクリックするだけで復元できます。
ただし、モデルについては復元されないので、画面から自分で再選択する必要があります。
下記は、上記で取得した設定情報を使って、異なるモデルで生成した結果です。このように色々なモデルで試してみると、お気に入りが見つかるかもしれません。

Best quality, masterpiece, ultra high res, (photorealistic:1.4), raw photo, light, deep shadow, low key, cold light
Negative prompt: ng_deepnegative_v1_75t, badhandv4 (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, normal quality, ((monochrome)), ((grayscale))
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1630623029, Face restoration: CodeFormer, Size: 512x512, Model hash: d819c8be6b, Model: majicmixRealistic_v4, Version: v1.2.1プロンプトの保存
現在入力されているプロンプトを、任意の名前で保存したり、呼び出したりすることが可能です。
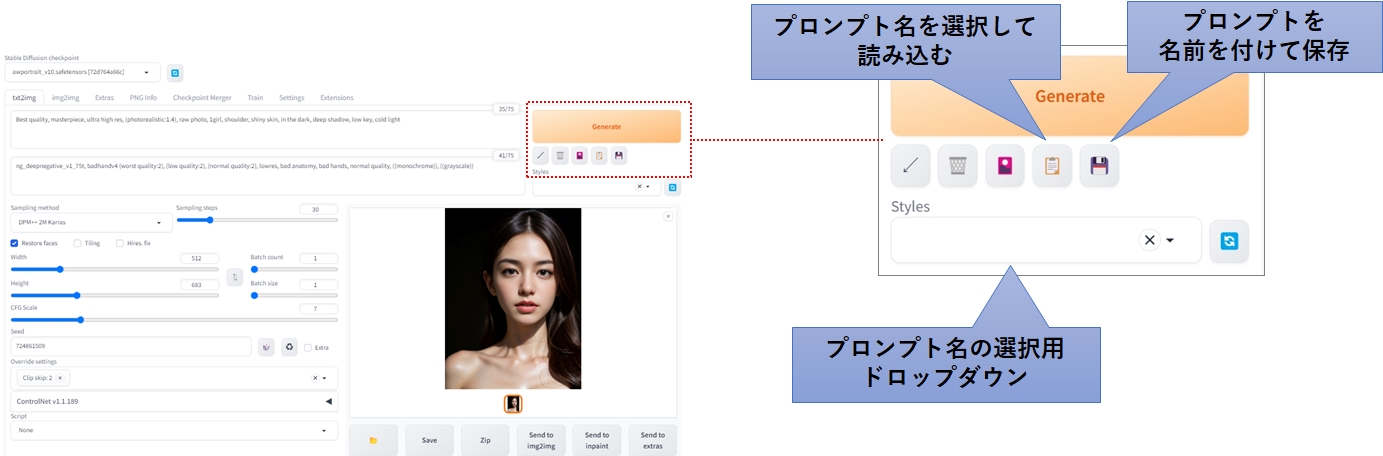
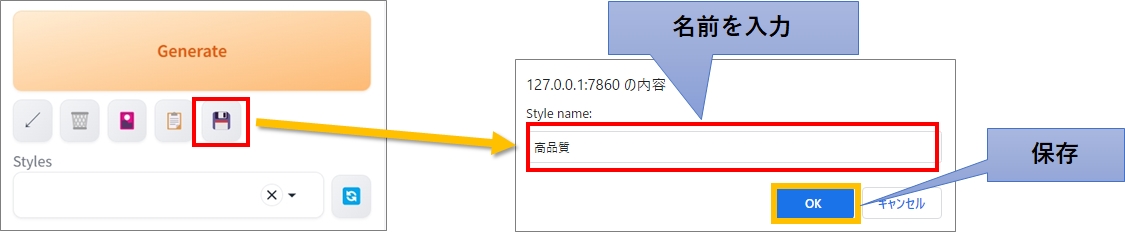
フロッピーディスクのアイコンをクリックすると、スタイル名の入力ウィンドウが表示されるので、任意の名前を入力してください。
保存されるのはプロンプト(ポジティブプロンプト、ネガティブプロンプトの両方)のみで、その他の設定情報は保存されません。
保存したプロンプトは、ドロップダウンをクリックして呼び出すことが可能です。この時、複数のプロンプトを一度に選択できます。
選択が終わったら、クリップボードようなアイコンをクリックすることで、現在のプロンプトに追加されます。
アイコンを何度もクリックすると、同じ内容のプロンプトが複数追加されますのでご注意ください。
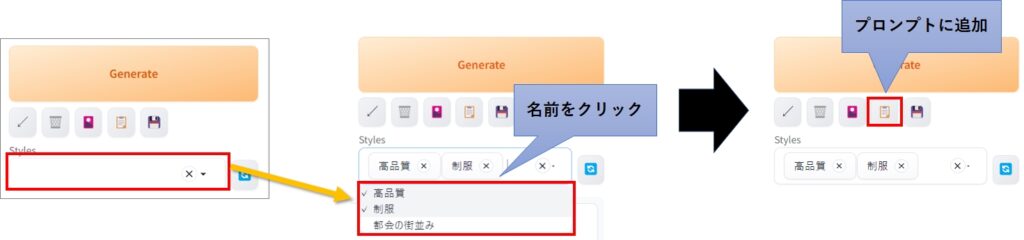
保存されたプロンプトは、stable-diffusion-webui フォルダ直下の styles.csv に保存されています。保存したプロンプトを削除したい場合、メモ帳などで開いて不要な行ごと削除してください。
尚、styles.csv を削除してしまっても、次回のプロンプト保存時にファイルが自動生成されます。

LoRAの使い方
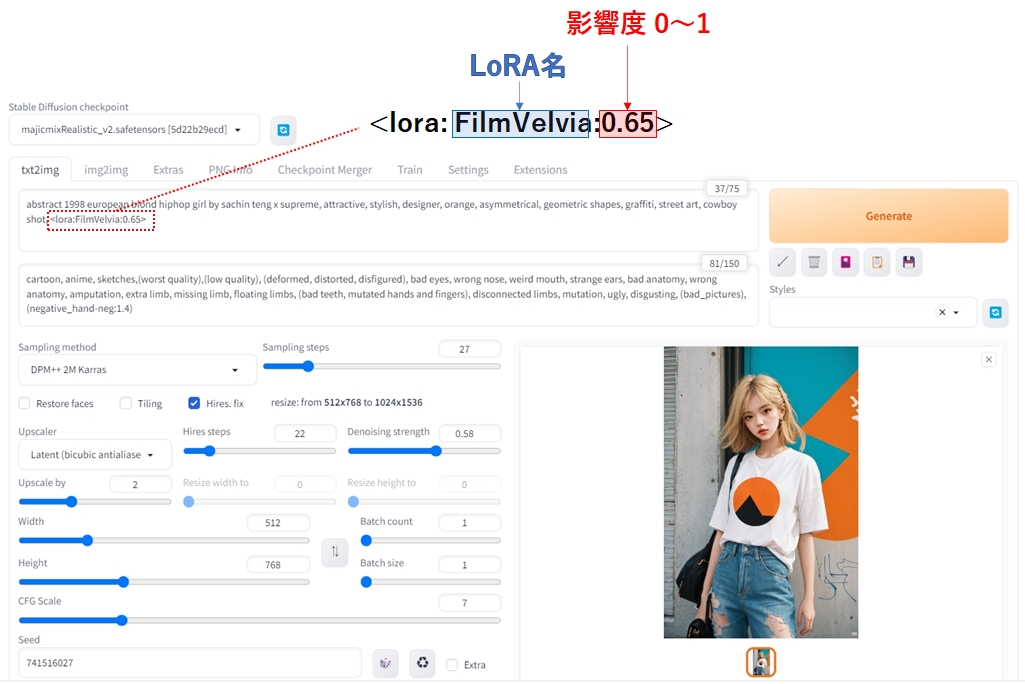
LoRAはプロンプトの中に次の書式で記述します。
<lora:LoRA名 : 影響度>
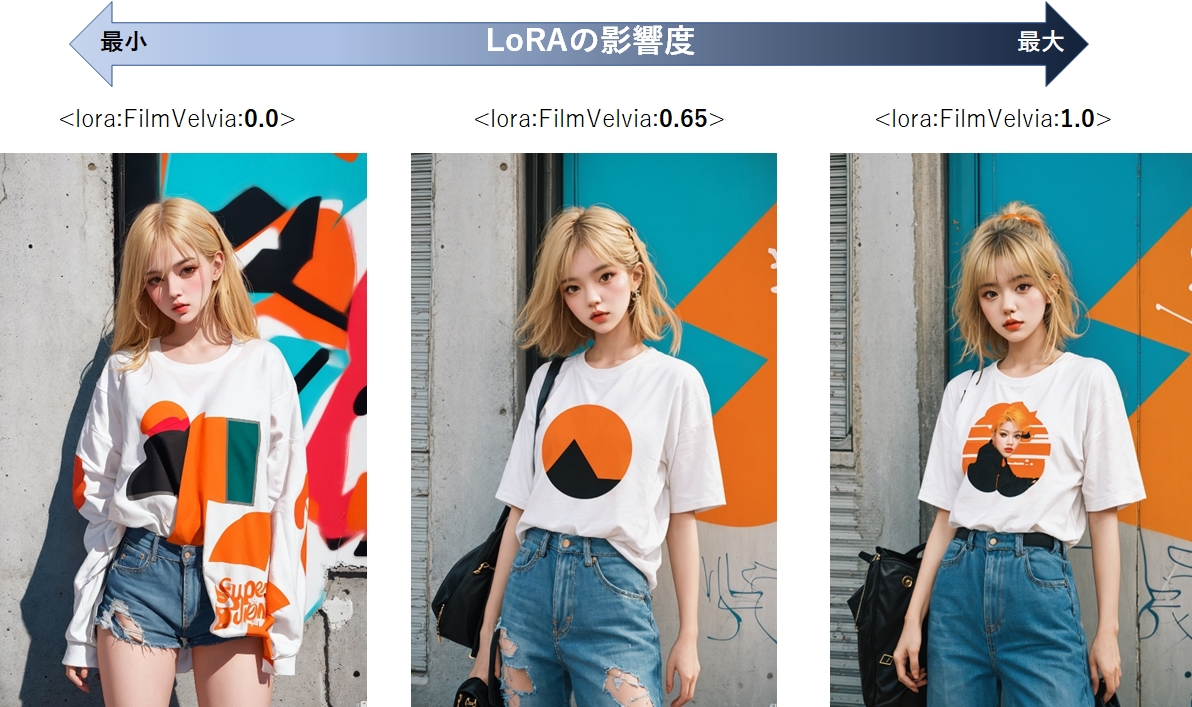
影響度は0~1までの値が指定可能で、1になるほど追加学習の影響を強く受けます。
また、LoRAは様々な種類が登場しているため、プロンプト内に複数のLoRAを記述することが可能です。
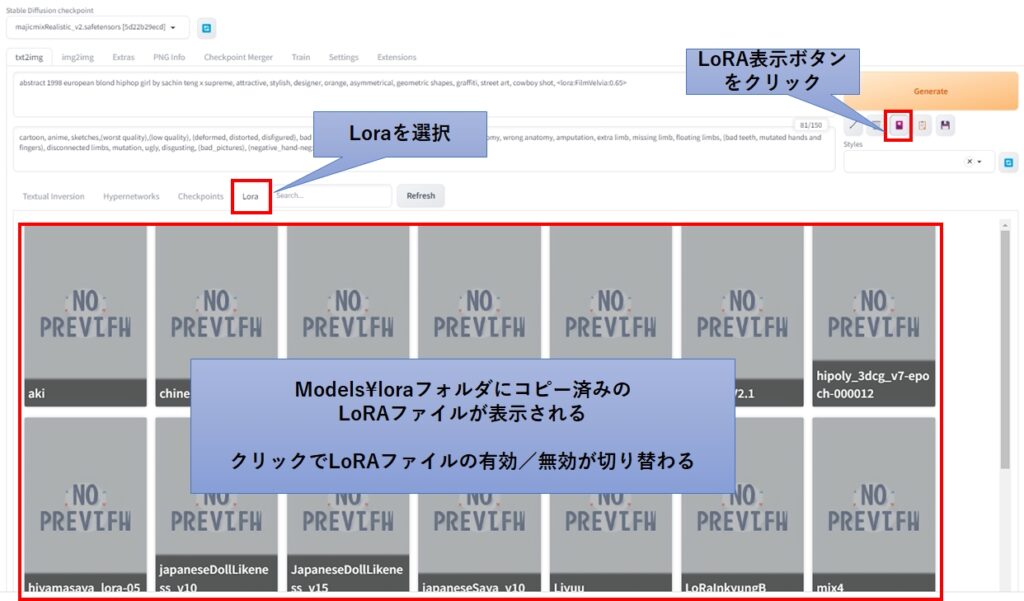
Stable Diffusion Web UI の画面からLoRAを選択することも可能です。Gelerateボタンの下にある花札のようなアイコンがLoRAの表示ボタンです。
これをクリックし、Loraのタブを選択すると、サムネイルの一覧が表示されます。
画像は特に表示されておらず、Loraの名前だけが表示されるので、直感的にどれを選べばよいか分からないですが、仕方ありません。
サムネイルはLoRAの有効/無効を切り替えるトグルスイッチになっていて、1回クリックするとプロンプトに <lora : ~ : 1> が追加され、再度クリックするとプロンプトから <lora : ~ : 1>が消えます。
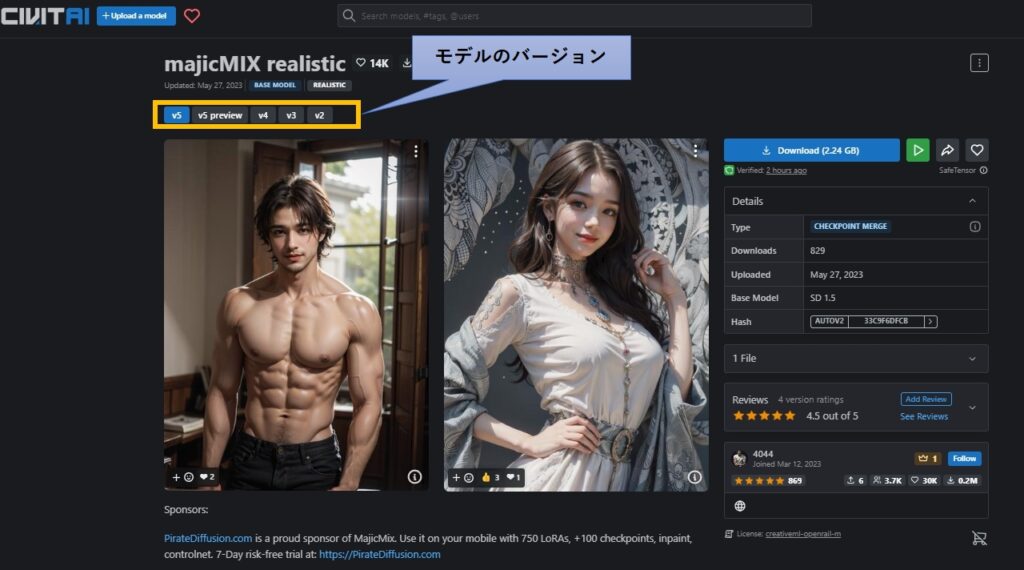
モデルのバージョンについて
モデルは常にバージョンアップがされていて、数日で新しいバージョンが登場することも珍しくありません。
モデルの各バージョンごとにサンプル画像が用意されており、同様の画像を生成させたい場合、過去バージョンをダウンロードする必要があります。
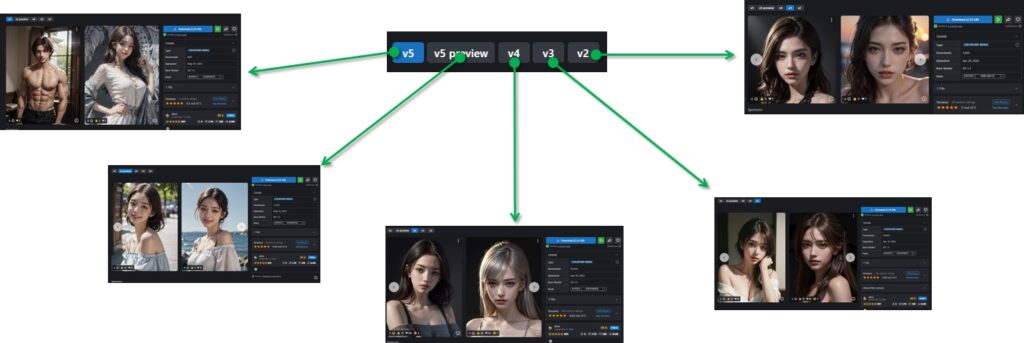
magicmixRealistic V2 のサンプル画像の設定を使って、V3からV5までのバージョンで画像生成したところ、下記の結果になりました。

基本的には最新バージョンで良いと思いますが、バージョンによって雰囲気が違うので、こだわりたい方は過去バージョンをダウンロードしてはいかがでしょうか。
まとめ
今回は Stable Diffusion を使うために必要なモデルのダウンロードと、その使い方について解説しました。
私の経験をもとに「これだけは最初に知っておきたかったこと」を、1つの記事としてまとめたつもりです。
他のサイトでもこの辺の情報は詳しく解説されていますが、断片的な記事になっているため、初心者にとっては分かりにくいかと思いますので、是非参考にしてください。
この記事が Stable Diffusion を始める方のお役に立てれば光栄です。



コメント