ChatGPTを筆頭に、Google Gemini、Windows11に標準搭載された Copilt など、LLM(Large Langage Model)が身近になってきました。
これらを実現するための技術として、深層学習(=ディープラーニング)があります。深層学習は、「多層のニューラルネットワークを用いた機械学習の手法」なのですが、なんのこっちゃ分かりにくいですよね。
また、LLM の性能や規模を示す表現としてパラメータ数というのがあります。ChatGPTで使われているGPT3.5は1750億、Google Geminiの場合は6000億といわれていますが、このパラメータにはどんな意味があるのでしょうか。
そこで、今回は、深層学習の仕組みとパラメータの意味について、図を使って丁寧に解説したいと思います。
ChatGPTを理解するうえでの基礎知識となりますので、興味のある方は是非ご一読下さい。
深層学習(ディープラーニング)とは
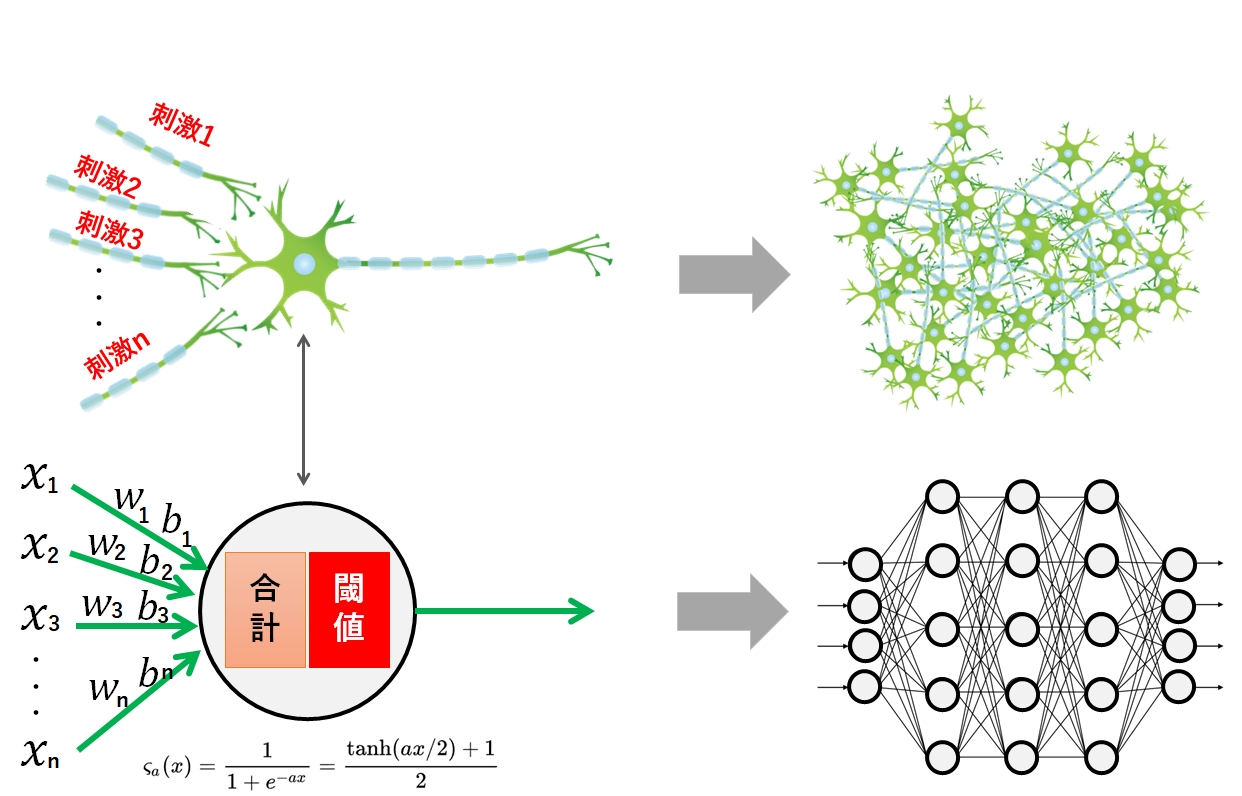
人間の脳には860億個の神経細胞が存在します。そして、目や耳や体から得られる情報をもとに、神経細胞同士が結合しながら判断や記憶などの処理を行っています。
この脳の構造(メカニズム)を数式で模倣したもをニューラルネットと呼んでおり、深層学習(ディープラーニング)の元になっています。
もう少し細かく説明すると、神経細胞1つに対する挙動を数式で表現し、それをいくつも束ねて1つの層を作り、更に「入力」「中間」「出力」の3重構造にします。
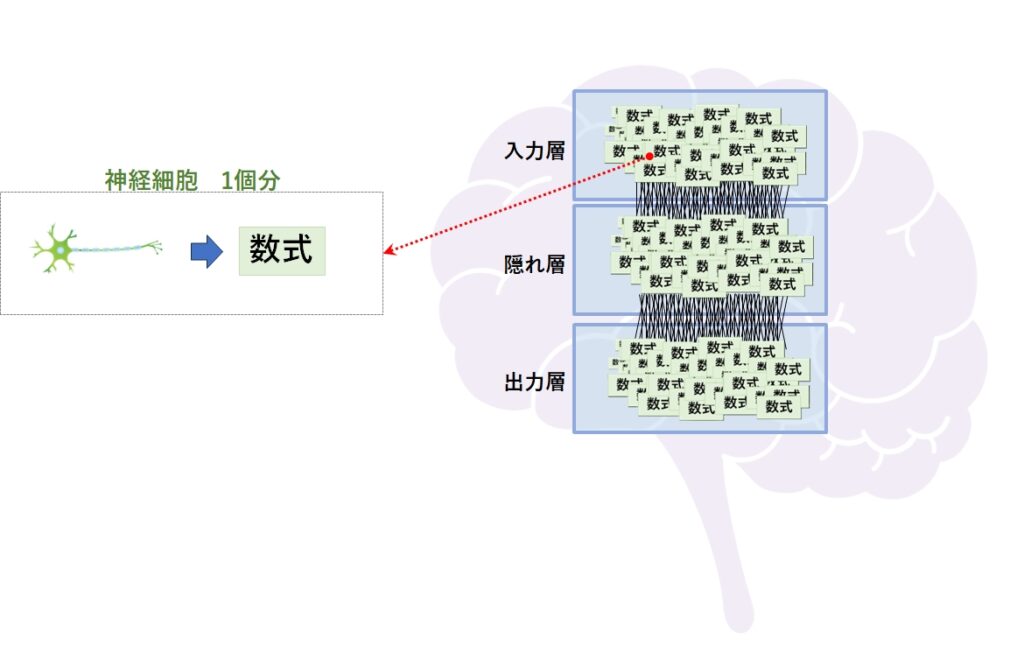
こうすることで、インプットしたデータを学習したり、分類することができるようになるのです。
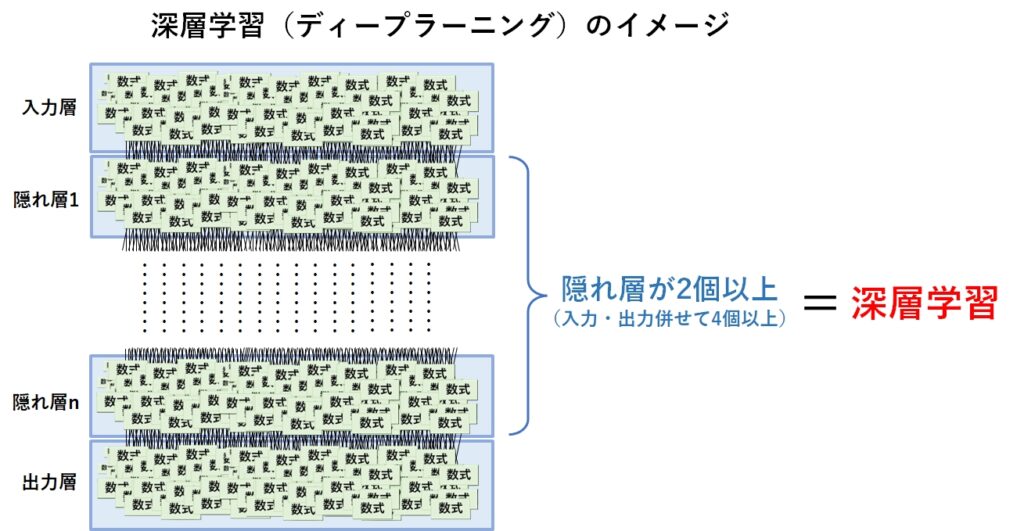
この階層構造の数を増やせば、より複雑な学習や分類ができるようになるのですが、計算量の多さを含む様々な課題があり、3層以上増やすことができませんでした。
昨今のコンピュータの技術的進歩とニューラルネットワークにおける研究の成果により、4層以上に増やすことが可能になりました。今では数百や数千の層を持たせることも珍しくありません。
そして、以前の3層構造のニューラルネットと区別するために、4層以上のニューラルネットのことを深層学習(ディープラーニング)と呼んでいます。
ニューラルネットは、学習と推論では層の使われ方が異なります。学習時は学習データ(教師データ)と呼ばれる問題と解答が1つになったデータを大量に入力し、学習させます。
具体的には、隠れ層が問題を解いて答えを出力層に伝えます。出力層は答え合わせを行った後、間違いがあったことを隠れ層に知らせます。隠れ層が正しい回答を返すまで、このサイクルは何度も繰り返されますが、この作業を学習と呼んでいます。
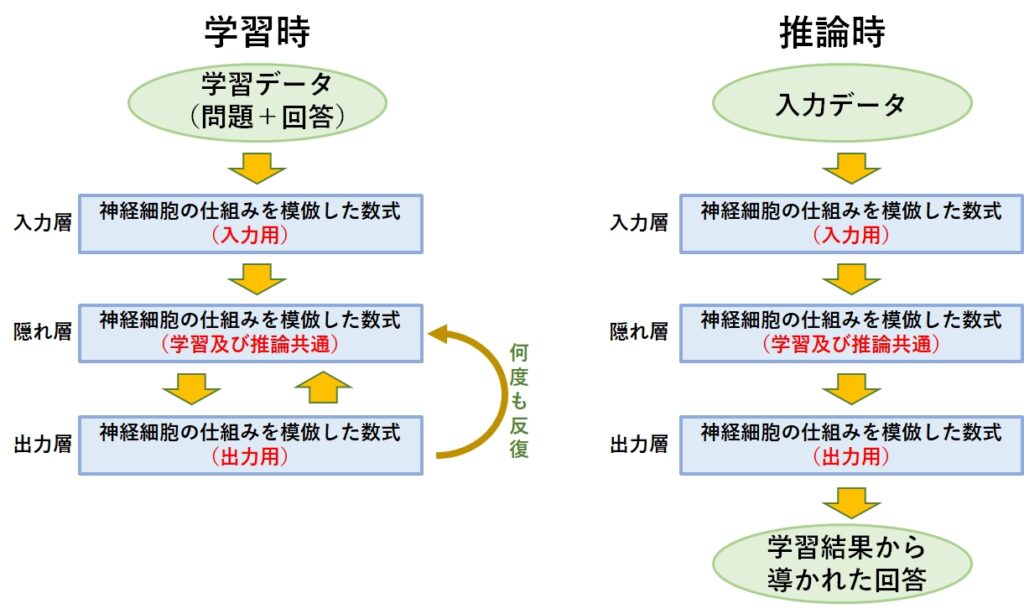
隠れ層は、出力層から受け取った間違いの情報を参考し、回答に使った計算方法の微調整を行います。この微調整する値をパラメータと呼んでいます。ChatGPTでは1470億個のパラメータがあるといわれていますが、1回の計算で1470億個の微調整が必要になるのです。
また、ChatGPTが満足のいく答えを返すまで何回も隠れ層と出力層の間でやりとりするため、その計算量は膨大な値となることは、ここからも想像できると思います。
ニューラルネットの概要
前章で概要は説明しましたので、ここからはもう少し詳しく説明していきます。その前に、人間の脳のメカニズムをおさらいしておきましょう。
人間の脳のメカニズム
人間が何かを考えたり記憶する場合、脳の神経細胞が互いに結合しながら、刺激として情報を伝達、処理します。
神経細胞同士は「シナプス」と呼ばれる結合部位を使って互いに結合するのですが、このことを「シナプス結合」と呼んでいます。
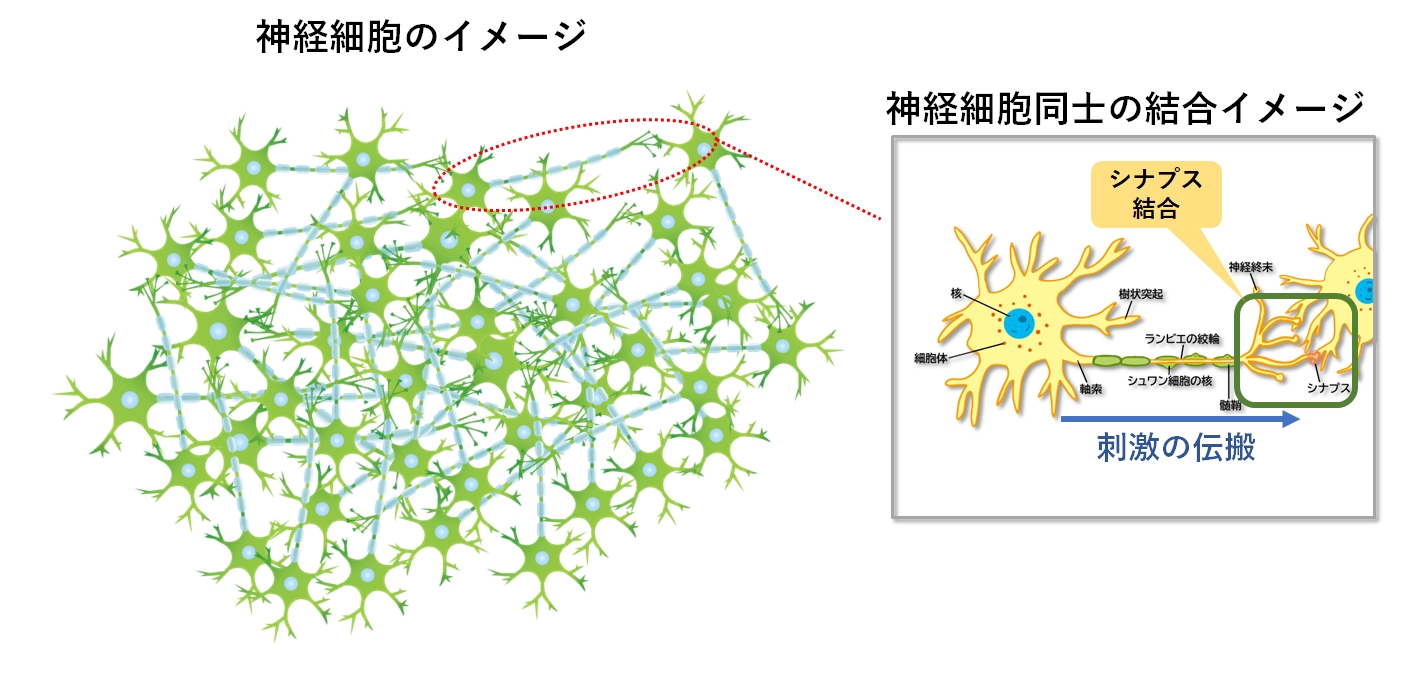
そして、人間が外界から受けた刺激(視覚、聴覚、触覚など)の強さによってシナプス結合の量が増え、それに伴い脳の機能(認知、感覚、運動など)も向上することが知られています。
ここでのポイントは、刺激の強さがどのように次の神経細胞に伝搬していくかです。
神経細胞同士が結合したからと言って、右から左に刺激が伝搬するわけではなく、ある一定量の刺激を超えたとき、はじめて次の神経細胞に刺激が伝搬されます。
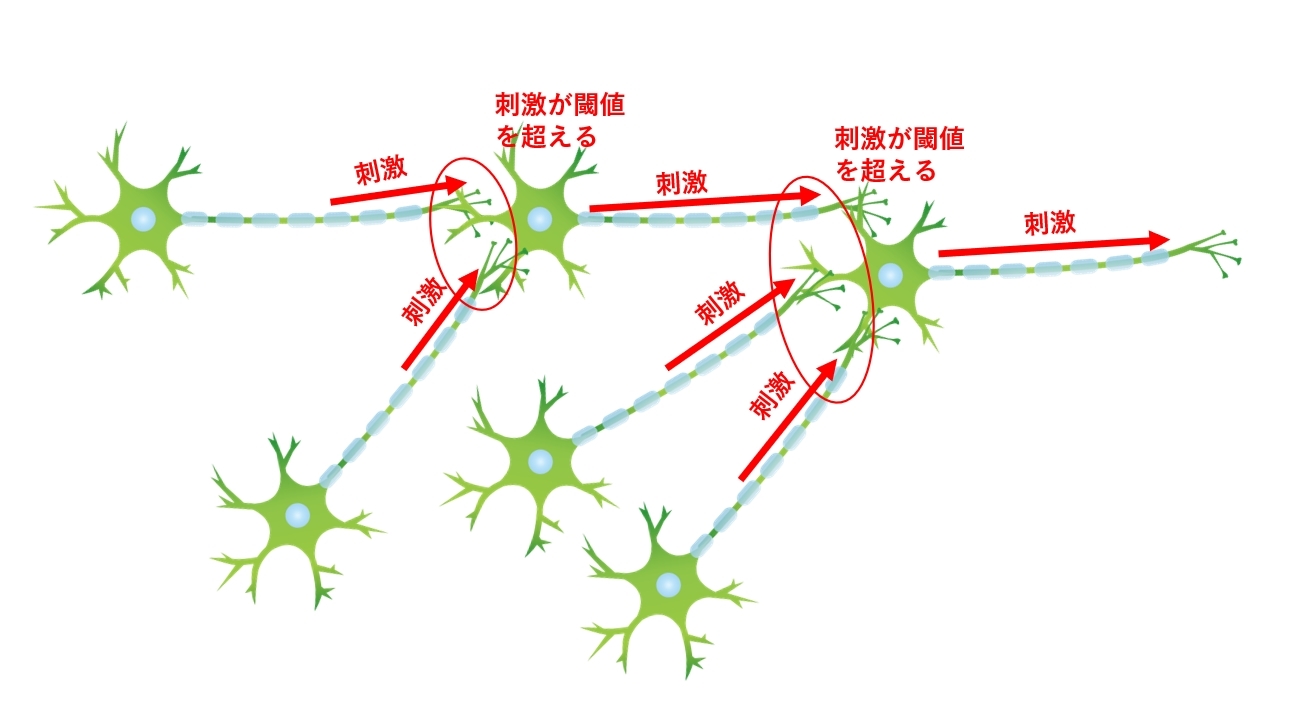
こでまでのことを整理すると次の3点になります。
- 神経細胞はシナプスと呼ばれる部位で他の神経細胞と結合する
- 神経細胞の結合量(シナプスの結合量)が多いほど、脳の機能が向上する
- 神経細胞は複数の神経細胞の刺激を受け取るが、伝達する相手は1つだけ
- 神経細胞が一定量の刺激を超えたとき、はじめて次の神経細胞に刺激を伝搬する
シナプス結合の数式化
神経細胞は複数の神経細胞と結合しますが、受けた刺激を次の神経細胞に伝搬する相手は1つだけです。そして、受けた刺激が一定量を超えたとき、次の神経細胞に刺激を伝達します。
このルールは次のように言い換えることができます。
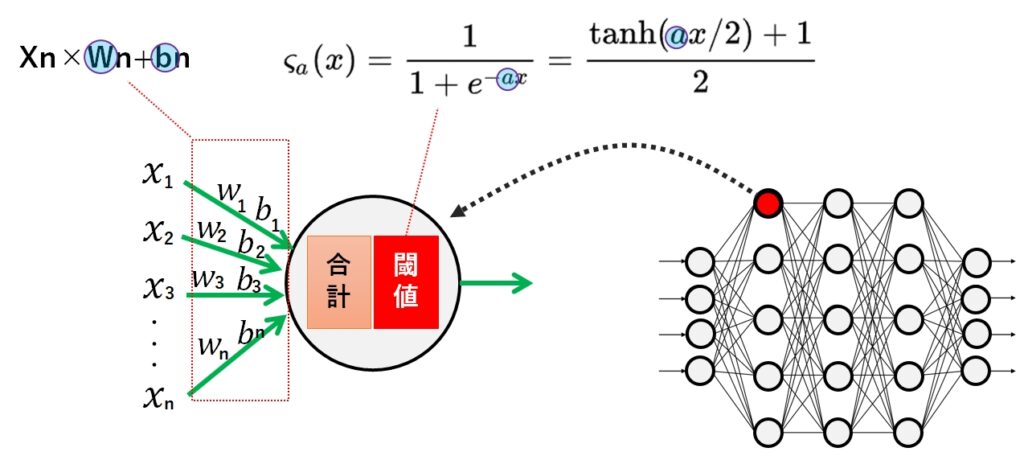
「複数の入力値(X1・・・Xn) という入力を受け取り、その値を合計した結果が閾値を超えたら、何らかの値を出力する」
つまり、このルールを数式にできれば、脳のメカニズムを数式化できたことになります。
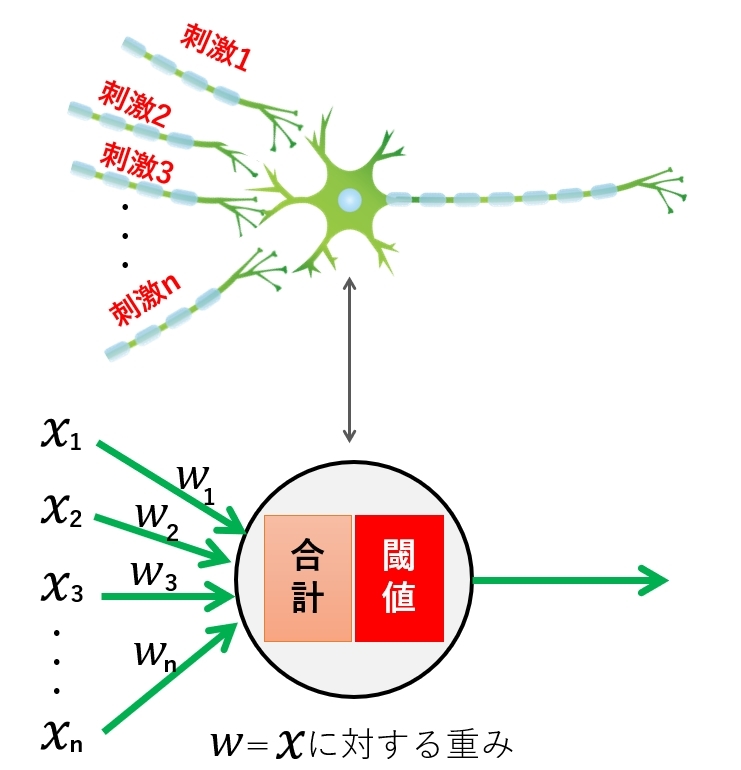
まず、1つの神経細胞に1つの刺激(入力値)が伝えられた場合に着目してみます。
神経細胞は0や1の数値が伝搬されているわけではなく、神経伝達物質(アミノ酸やペプチドなどの化合物)で情報を伝達しているので、子のメカニズムを数値として扱う場合、何かの値を掛けたり足したりできるほうが都合がいいのです。
そこで、入力値 X に何らかの重みWを掛けて、バイアス値として b を足してあげることを考えます。
X1×W1+b1
1つの神経細胞に複数の刺激(入力値)がある場合は、単純に次の様になります。
X1×W1+b1 + X2×W2+b2 + ・・・・・Xn×Wn+bn
これで複数の刺激を計算することができました。次は、この計算結果が閾値を超えると1になるような数式を考えれば良さそうです。
ある閾値を超えると1になる曲線としてはロジスティック曲線があるので、これが使えそうですね。
実際には、より緩やかなカーブを描くシグモイド関数が使われますが、原理としては入力値を0~1までの値で表す数式を使うことで、神経細胞の出力を模倣することができます。
尚、数式の内容を理解する必要はありません。数式で表現できるという点だけ覚えておいてください)
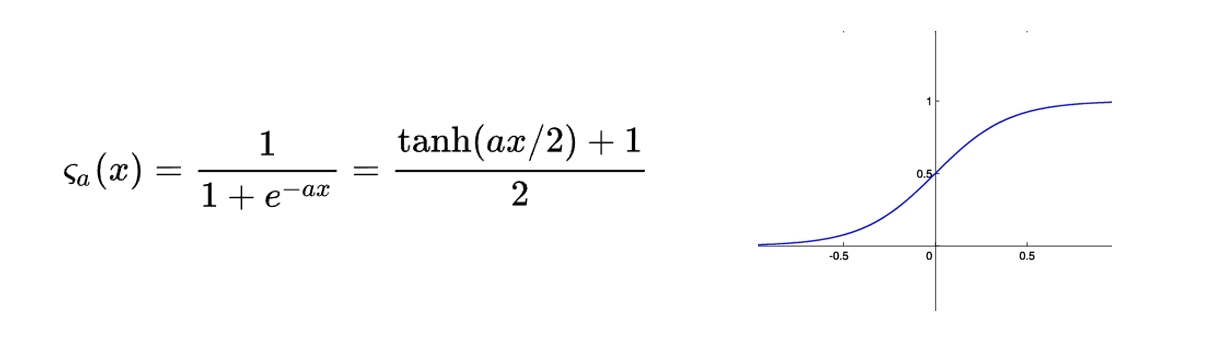
ニューラルネットのメカニズム
冒頭でも申しましたが、人間の脳は860億個の神経細胞で構成されています。ここまで説明してきたのはたった1つの神経細胞なので、これを860億個とは言わないまでも、ある程度の個数を用意して、結合させる必要があります。
つまり、実際の神経細胞のネットワークと同じように、数式化した神経細胞を複数個繋げてネットワーク化したものがニューラルネットです。
実際には、仮にA、B、Cという3つの神経細胞の数式があったとします。これらの計算結果をDという神経細胞の入力として使い、これを繰り返すことでネットワーク化しています。
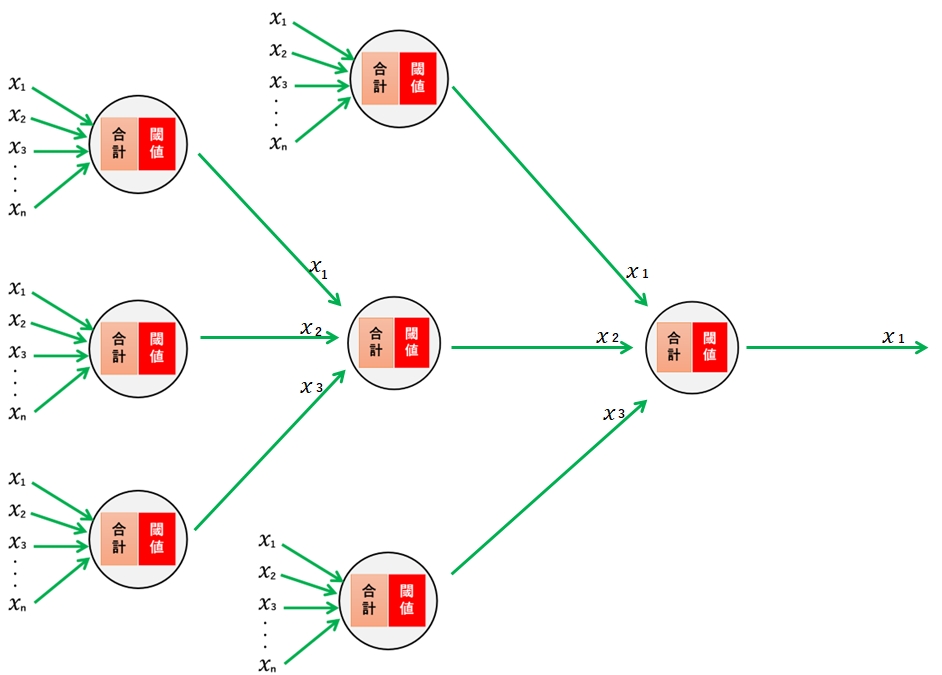
上記の図で分かるように、ニューラルネットは入力と出力を1つの層として考えると、複数の層で構成されていることがわかります。
層にも呼び方があって、最初の入り口(データの受け口)が「入力層」、最終結果を出す最後の層(計算結果の出力)が「出力層」、入力層と出力層の間にある層が「隠れ層」とか「中間層」と呼んで区別しています。
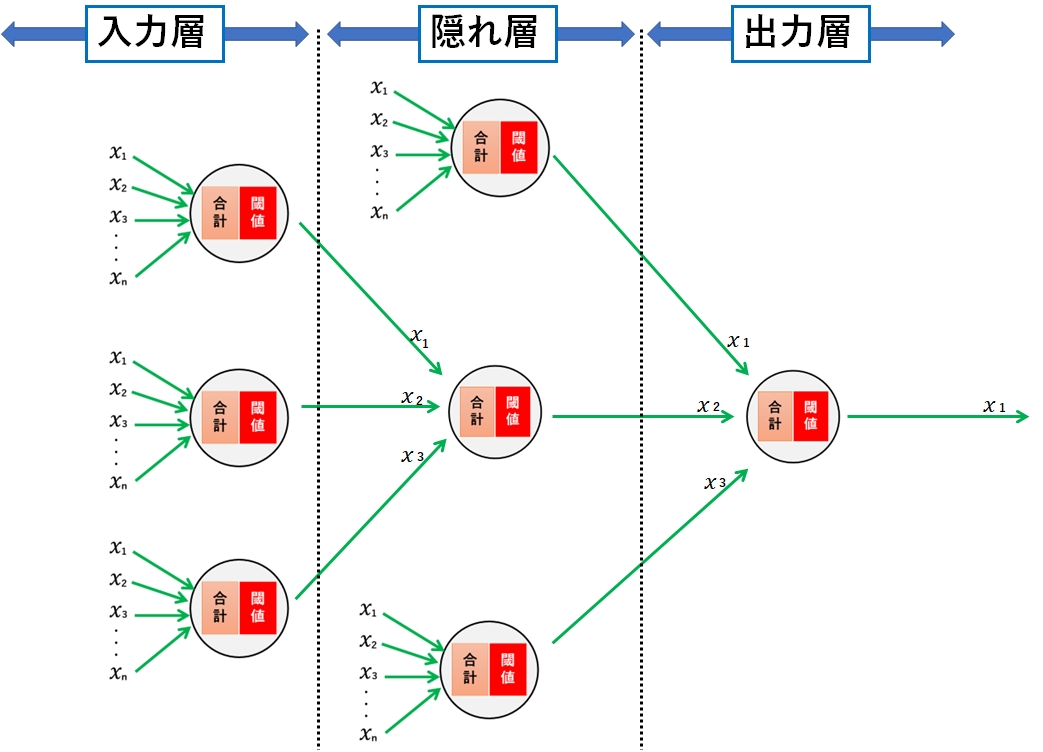
深層学習(ディープラーニング)とは
ニューラルネットを理解していただければ、深層学習(ディープラーニング)の理解は簡単です。
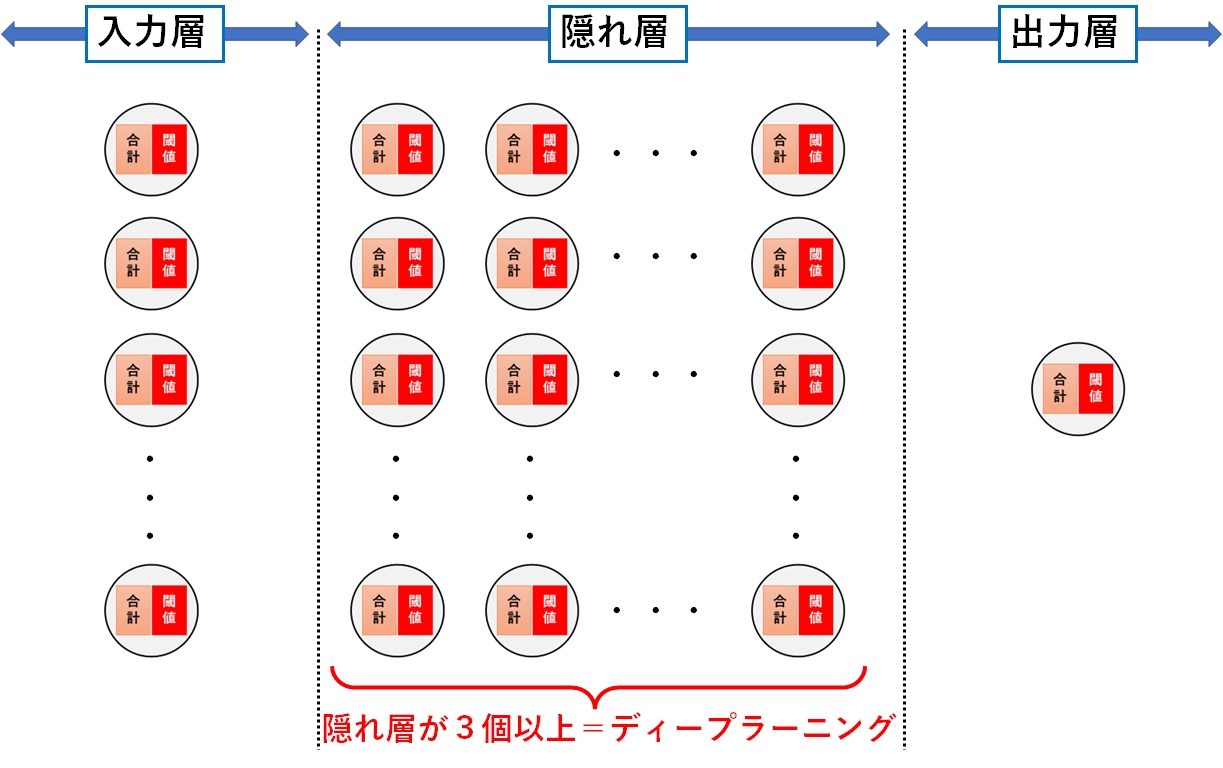
層が3層以上あるものを深層学習(ディープラーニング又はディープニューラルネットワーク)と呼んでいます。
深層学習(ディープラーニング)の歴史
ニューラルネットワークが登場した時は、隠れ層を増やすことで複雑な問題が解けるようになると期待されていました。
しかし、層と層の間は総当たり的な計算が必要だったため、層を増やすごとに計算量は指数関数的に増加し、当時(1950年代)のコンピュータ能力では計算が追い付かず、せいぜい3層(入力層、出力層、隠れ層)までが限界でした。
それ以外にも、計算結果が収束(誤差が減らない)しない、学習に使ったデータ以外は精度が出ない(過学習)など、いくつかクリアすべき課題があり、長い間実用化されませんでした。
それでも、2010年ころから徐々に画像認識や音声認識での実用化が進み、2016年にGoogleが「AlphaGo」を開発、プロ棋士に勝利したことで一気に盛り上がりました。
その後ディープラーニングは急激に進化を遂げ、翻訳や画像生成、文書生成の分野で次々と成果を出してきました。
そして2022年11月にChatGPTが、2023年3月にはGPT4 が登場したことで、深層学習(ディープラーニング)を用いたAIが、我々の日常に浸透しようとしています。
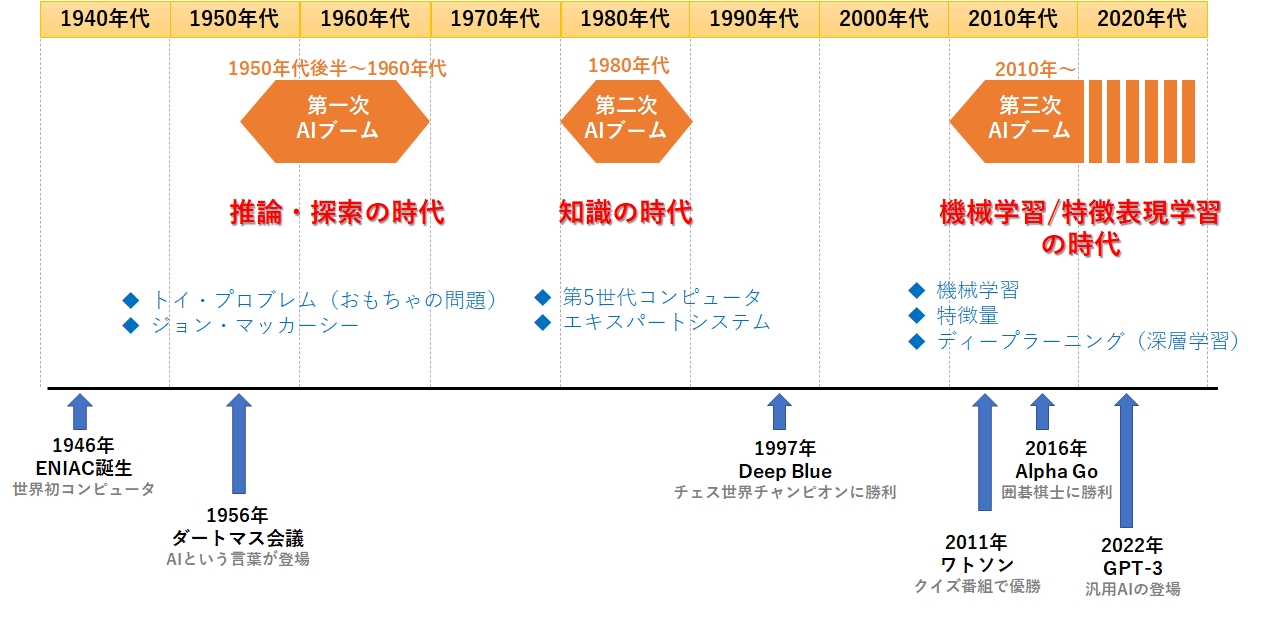
ディープラーニングのパラメータとは
深層学習(ディープラーニング)では、パラメータという言葉がよく出てきます。例えばGPT-3のパラメータ数は1750億個にも及びます。
では、このパラメータとは一体何でしょうか。
答えは下図にある通り、数式における W、n、a の値です。
GPT-3の層の数は96層であると言われています。
ディープラーニングでは、各層に何千~何万もの神経細胞に相当する数式が置かれており、その数分のパラメータが存在します。
そして、次の3つのステップを何度も繰り返しながら、誤差が一番小さくなるパラメータの値(W、n、a )を求めます。
- 入力値に対して誤差が小さくなるようパラメータを調整(初回は適当に決める)
- 計算結果と正解値の誤差を計算
- 誤差を最上位の相に戻す
この作業がパラメータを調整するということです。
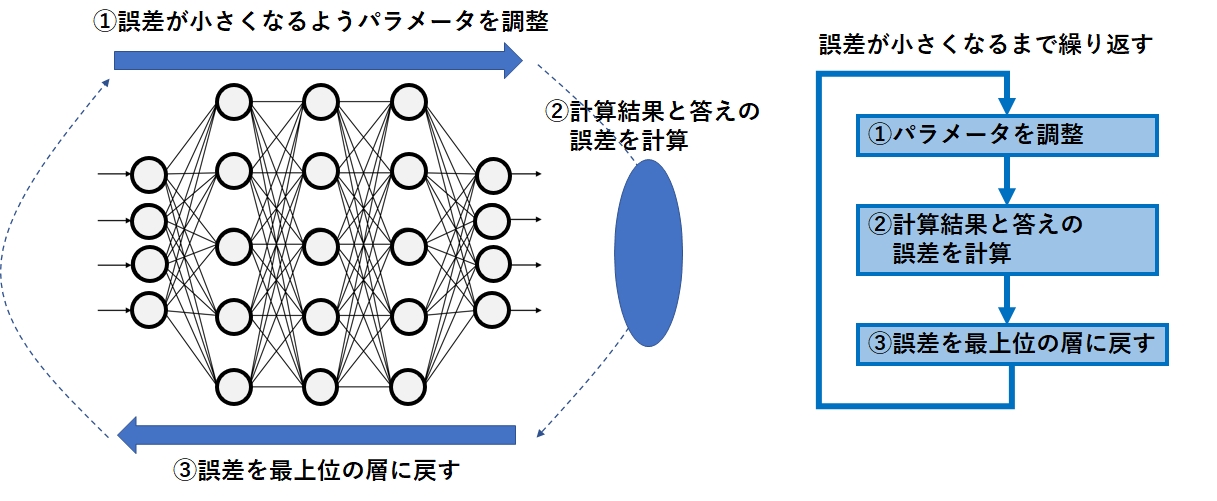
実際はもっと色々な点を考慮する必要があるため、もっと複雑になりますが、基本の考え方は上記のようになります。
実際のソースコード
では、実際にどのようなプログラムを書けば良いのでしょう?
Pythonの基本構文だけでディープラーニングのプログラムを書くと、それだけでソース量が多くなるので、ここではディープラーニング専用のライブラリ(フレームワーク)を使うことにします。
フレームワークにはいくつかの種類が存在しますが、下記の例は keras というフレームワークを使った例です。
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
# 入力層。4次元の入力を受け取り、8個のニューロンに変換する。
model.add(Dense(8, input_dim=4, activation='sigmoid'))
# 隠れ層兼出力層 1個のニューロンで出力を決定する。
model.add(Dense(1, activation='sigmoid'))
# モデルのコンパイル
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])このプログラムは4つの入力を受け取り、1つの出力(True/False)を返す最も簡単なサンプルプログラムです。入力1層、隠れ層兼出力層1層、合計2層の構成になっています。
ディープラーニングでは、この隠れ層を3個以上用意します。
入力が4つしかないので計算量は少ないですが、例えば1024×768の画像を入力とし、隠れ層を3個用意した場合、飛躍的に計算量が増えることは想像できると思います。
次は GPT-3の元となるトランスフォーマのソースコードのサンプルです。様々な考慮を省いた最も単純なサンプルではありますが、中身はともかくとして、かなりソースコード量が増えたことがお分かりいただけると思います。
from tensorflow import keras
from tensorflow.keras import layers
input_shape = (1024,)
num_layers = 24
embed_dim = 768
num_heads = 12
ff_dim = 3072
# Create input layers
input_ids = layers.Input(input_shape, dtype=tf.int32)
attention_mask = layers.Input(input_shape, dtype=tf.int32)
# Create embedding layers
embedding_layer = layers.Embedding(input_dim=50000, output_dim=embed_dim)
token_embeddings = embedding_layer(input_ids)
# Add positional encoding
position_embedding_layer = layers.Embedding(input_dim=1024, output_dim=embed_dim)
position_embeddings = position_embedding_layer(tf.range(start=0, limit=1024, delta=1))
position_embeddings = layers.Dropout(0.1)(position_embeddings)
# Add attention layers
for i in range(num_layers):
attention_heads = []
for j in range(num_heads):
attention_layer = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim//num_heads)
attention_heads.append(attention_layer(token_embeddings, token_embeddings, attention_mask))
attention_outputs = layers.Concatenate()(attention_heads)
attention_outputs = layers.LayerNormalization(epsilon=1e-6)(attention_outputs)
attention_outputs = layers.Dropout(0.1)(attention_outputs + token_embeddings)
# Add feedforward layers
feed_forward_layer = keras.Sequential([
layers.Dense(ff_dim, activation="relu"),
layers.Dense(embed_dim),
])
feed_forward_outputs = feed_forward_layer(attention_outputs)
feed_forward_outputs = layers.Dropout(0.1)(feed_forward_outputs + attention_outputs)
token_embeddings = layers.LayerNormalization(epsilon=1e-6)(feed_forward_outputs)
# Add output layer
outputs = layers.Dense(50000, activation="softmax")(token_embeddings)
# Create the model
model = keras.Model(inputs=[input_ids, attention_mask], outputs=outputs)
# Compile the model
optimizer = keras.optimizers.Adam(learning_rate=5e-5)
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = keras.metrics.SparseCategoricalAccuracy("accuracy")
model.compile(optimizer=optimizer, loss=[loss, *[None] * num_layers], metrics=[metric])GPT-3は、これより遥かに複雑なプログラムで構成され、かつ数百GBの学習データを使っているため、普通のパソコンで計算できるレベルを超えていることがうかがえます。
深層学習で出来たモデルは謎だらけ
ここまでの説明を理解していただければ、深層学習は「脳の神経細胞を数式に置き換えて、総当たりの計算を繰り返してパラメータを調整しただけ」に過ぎません。
では、なぜこのような単純な構造で、ChatGPTをはじめとする文書作成、画像生成、様々な推論ができるのでしょうか?
なぜ深層学習のモデルを使えば、ここまでのことが出来るのか?その答えは誰にも分かっていません。
人間の脳についても未知の部分がほとんどですが、それを模倣した深層学習も同様に未知の部分が多いのです。
深層学習を使えば、人間と同じような思考ができること、その結果が人の役にたつことが分かったので、急速に普及しているのです。
ChatGPTに命令をすることを「プロンプトを作る」と言いますが、「プロンプト」の良し悪しがChatGPTの精度に大きく関わることが分かってきました。
これからは、深層学習で作られたモデルに対して、「適切なプロンプトの作成」ができるエンジニア(=プロンプトエンジニア)が重要なスキルになってくるでしょう。
まとめ
今回は、深層学習(=ディープラーニング)の仕組みが概念的に理解できるよう、図を使って説明しました。
深層学習は脳の神経細胞を数式に置き換えたもので、数式の中に含まれる定数をパラメータと呼んでいます。
そして学習時は、与えられた答えとの誤差が小さくなるよう、何度も何度もパラメータを微調整するという作業を繰り返し、最終的なパラメータの値を決定していきます。
そこには、気が遠くなるような計算量が必要であり、GPT-3に至っては普通のパソコンでは計算できないくらいの計算量が必要となります。
そんなすごいAIが、無料で利用できるようになるのは、すごいことです。
今回の記事が、深層学習(ディープラーニング)やChatGPT(GPT-3,GPT-4)を理解する手助けになれば幸いです。



コメント