「【総まとめ】UPSERTとは?DBごとの違いは?」では、主要なDBごとの書き方をざっくり説明しました。
今回は、SQL Server(及びSQL Database)でのUpsertに焦点を絞り、深堀していきたいと思います。
参考までに、DataFrameからUpsertを生成するPython関数も紹介していますので、必要に応じてコピぺしてご利用下さい。
SQL Server は MERGE ~ で Upsertを行う
SQL Server でUpsertを行う場合は、MERGE INTO ~ WHEN ~を使います。

MERGE INTO ~に更新先(インサート先)のテーブル名、 USING ~に更新元のテーブル名、ON ~ にユニークキーを指定します。
そして、WHEN MATCHED THEN ~ にキーが存在した場合の処理(通常はUpdate文)、WHEN NOT MATCHED THEN ~ にキーが存在しなかった場合の処理(通常は Insert文)を記述します。
また、任意の値を Upsert したい場合は、 USINGに続けて (select 値1,値2,・・・)と記述します。
-- table_B から table_AにUpsertする場合
merge into table_A t1
using table_B t2
on (t1.shop = t2.shop and t1.name=t2.name)
when matched then update set t1.age = t2.age
when not matched then insert values (shop,name,age);
-- table_A に1行登録する場合
merge into table_A t1
using (select 1 as shop,'yamada' as name,15 as age) t2
on (t1.shop = t2.shop and t1.name=t2.name)
when matched then update set t1.age = t2.age
when not matched then insert values (shop,name,age);、ユニーク制約に名前を付けると、少しだけ記述が簡単になります。
検証データ
本記事のUpsert文を実際に試してみたい場合は、以下のSQLを実行して下さい。
--サンプルテーブルの作成とテストデータ登録
CREATE TABLE oders
(
shop_no integer not null,
order_date datetime not null,
product_id integer not null,
count integer not null,
constraint oders_p_key primary key (shop_no,order_date,product_id)
);
insert into oders values(1,'2023/01/01 09:00:00',10000,5);
insert into oders values(1,'2023/01/01 09:10:00',10000,15);
insert into oders values(1,'2023/01/01 09:20:00',10000,25);
--下記はテーブル間のUpsert確認用(odersを丸ごとコピー)
select * into old_oders from odersテーブル間でUpsertする

テーブル間でUpsertする場合は次のように記述します。

この時、テーブルAとテーブルBのどちらに所属する列名であるかが明確になるよう、エイリアス名(又はテーブル名)を列名の先頭に付与する必要があります。
ただし、insert (列名1,列名2,・・・)の列名だけは例外で、逆にエイリアス名を付けるとエラーになるのでご注意ください。
merge into oders t1
using old_oders t2
on (t1.shop_no = t2.shop_no and t1.order_date=t2.order_date and t1.product_id=t2.product_id)
when matched then
update set t1.count = t2.count
when not matched then
insert(shop_no,order_date,product_id,count)
values (t2.shop_no,t2.order_date,t2.product_id,t2.count);実は、以下の通り insert の部分については、少しだけ省略した書き方ができます。

下記は 省略した例です。
merge into oders t1
using old_oders t2
on (t1.shop_no = t2.shop_no and t1.order_date=t2.order_date and t1.product_id=t2.product_id)
when matched then
update set t1.count = t2.count
when not matched then
insert values (shop_no,order_date,product_id,count);1行をUpsertする

任意の値をUpsertしたい場合は、USING テーブル名 の代わりに、(select 列名1 AS 値1,・・・)と記述します。「1行だけの一時的なテーブルを作って、それを USINGに指定する」と考えると分かり易いでしょう。

下記は、サンプルテーブルに (1,'2023/01/01 09:00:00',10000,5) のデータをインサートし、レコードが既に存在していれば 数量(count)を 5に更新するサンプルです。
merge into oders t1
using (select 1 shop_no,'2023/01/01 09:00:00' order_date,10000 product_id,5 count) t2
on (t1.shop_no = t2.shop_no and t1.order_date=t2.order_date and t1.product_id=t2.product_id)
when matched then update set t1.count = 5
when not matched then insert values (1,'2023/01/01 09:00:00',10000,5);ON~に記述する結合条件が真なら MATCHED THEN ~を、偽なら NOT MATCHED THEN ~を実行してくれるため、テーブルBとは全く異なる値でUpdateやInsertを行うことも、やろうと思えば可能です。
例えば、キーが存在しなければ Insert 時に count を 5で登録し、キーが存在すれば count を 15で Updateするという事もできます。
通常は、テーブルAとテーブルBを同じ内容にするためのUpsertですから、直値をあちこち記述するのではなく、列名を使って更新すべき値を指定します。
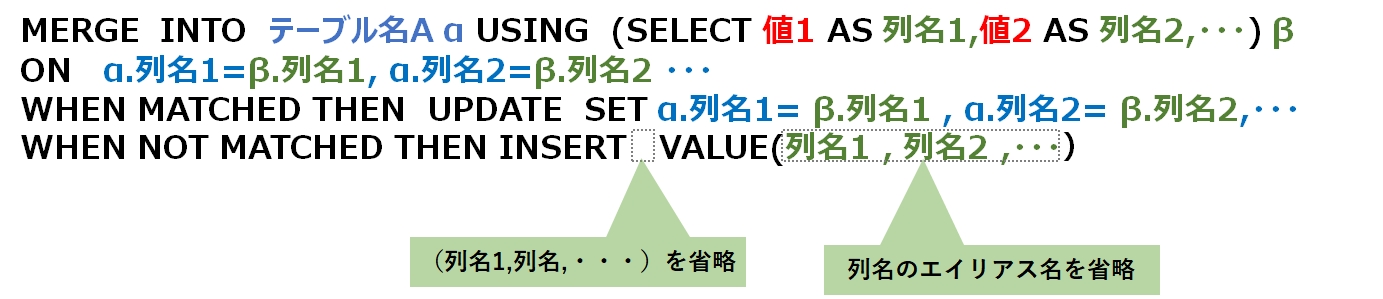
このMERGE文は、USING 部分を除いて、テーブルBからテーブルAへUpsertする時と全く同じです。
下記は簡略化した時のサンプルですが、 USING (SELECT ~)の AS も省略しています。
merge into oders t1
using (select 1 shop_no,'2023/01/01 09:00:00' order_date,10000 product_id,5 count) t2
on (t1.shop_no = t2.shop_no and t1.order_date=t2.order_date and t1.product_id=t2.product_id)
when matched then update set t1.count = t2.count
when not matched then insert values (shop_no,order_date,product_id,count);複数行をまとめてUpsertする
SQL Serverでは、1回のInsert文で複数行(複数レコード)をまとめて登録する マルチインサート文が使えますが、Upsertについても同様のことが行えます。
ポイントは、using の部分を union でつなげるところです。こうすることによって、複数行を持つテーブルが一時的に出来たように見え、テーブル間のUpsertが実行できます。
merge into oders t1
using
(
select 1 shop_no,'2023/01/01 09:10:00' order_date,10000 product_id,15 count
union
select 1 shop_no,'2023/01/01 09:20:00' order_date,10000 product_id,110 count
union
select 1 shop_no,'2023/01/01 09:30:00' order_date,10000 product_id,115 count
) t2
on (t1.shop_no = t2.shop_no and t1.order_date=t2.order_date and t1.product_id=t2.product_id)
when matched then update set t1.count = t2.count
when not matched then insert values (shop_no,order_date,product_id,count); 尚、下図のように1回のUpsertの中で キーが重複するデータをInsertした場合、「PRIMARY KEY違反 〇〇〇は重複するキーを挿入できません」又は「同じ行に対してUPDATE又はDELETEが実行されました」というエラーになります。

UpsertでInsertだけ行う(Updateしない)

WHEN MATCHED THEN UPDATE SET ~ の記述をしなければ、Updateされません。
-- oders に向けてインサートを行うが、既に存在する場合は何もしない
merge into oders t1
using (select 1 shop_no,'2023/01/01 09:00:00' order_date,10000 product_id,115 count) t2
on (t1.shop_no = t2.shop_no and t1.order_date=t2.order_date and t1.product_id=t2.product_id)
when not matched then insert values (shop_no,order_date,product_id,count);
-- old_odersから oders に向けてインサートを行うが、既に存在するレコードには何もしない
merge into oders t1
using old_oders t2
on (t1.shop_no = t2.shop_no and t1.order_date=t2.order_date and t1.product_id=t2.product_id)
when not matched then insert values (shop_no,order_date,product_id,count);Pythonのサンプル
それでは、参考例としてDataFrameの値からUpsert文を生成するPythonのサンプルプログラムについてご紹介します。
使い方のサンプル
create_upsert にDataFrame、テーブル名、ユニークキーのリストを指定するだけで、Merge文を生成してくれます。
尚、下記サンプルで生成したUpsert文は、冒頭に紹介したサンプルテーブルに対して実行が可能です。
datas = [
[1,'2023/01/01 09:00:00',10000,55],
[1,'2023/01/01 09:10:00',10000,65],
[1,'2023/01/01 09:20:00',10000,75]
]
df = pd.DataFrame(datas,columns=['shop_no','order_date','product_id','count'])
sqls = create_upsert(df,'oders',['shop_no','order_date','product_id'])
for sql in sqls:
print(sql)関数のソースコード
以下は、関数本体のソースコードになります。数値以外のデータ(文字列、日付)はシングルクォートで括る必要があるので、dtype が 'object' か否かで判断しています。
また、insert into ~ values ~ の values に渡すカラム値は、文字列に変換後、'nan'⇒NULL に置換しています。もし値に 'nan' が含まれるとNULLに変換されてしまう点にご注意下さい。
def create_upsert(df,table,key_columns):
'''
DataFrameの内容からUpser文を作成する
Parameters
----------
df : DataFrame
データを格納したDataFrame
table : str
Upsert対象のテーブル名
key_columns : list of str
ユニークキーのカラム
例:['shop_no','order_date',・・・]"
Returns
----------
res:str
生成されたマルチテーブルインサート文
'''
# df から全てのカラム名を取り出す
columns = ",".join([i for i in df.columns])
# シングルクォート格納用のリストを作り、カラムの型がobjectの場合のみシングルクォートをセット
quote = ["'" if str(dtype) == 'object' else '' for dtype in df.dtypes]
sqls = []
# 全ての行を取り出す
for row in df.itertuples():
# 0カラム名(行インデックス)を飛ばし、必要に応じて各カラム値をシングルクォートで括る。
items = [ f'{quote[i]}{str(row[i+1])}{quote[i]} AS {df.columns[i]}' for i in range(len(df.columns))]
# merge句の作成
values = ','.join(items).replace("'nan'", "NULL")
merge = f'merge into {table} t1 using (select {values}) t2 '
# on句の作成
keys = ' and '.join([ f't1.{x}=t2.{x}' for x in key_columns])
condition = f'on ({keys}) '
# matched句の作成
set_list = ','.join([f't1.{x}=t2.{x}' for x in df.columns if x not in key_columns])
matched = f"when matched then update set {set_list} "
# unmatched句の作成
column_list = ','.join(df.columns)
unmatched = f"when not matched then insert values({column_list}) "
# insert、conflict、updateを結合
sqls.append(merge + condition + matched + unmatched)
return sqlsまとめ
今回はSQLServerのUpsertに焦点を絞って詳細を解説しました。
SQLServerでUpsertを行うには、Merge into ~ に更新先テーブル名、using ~に更新元テーブル名、on ~ に結合条件を記載します。そして、 when not matched then ~ にキーが存在しなかった処理(通常は insert文)、when matched then ~ にキーが存在した時の処理(通常はUpdate文)を記述します。
また、キーが存在した場合、Updateしたくないなら when matched then ~を省略することで実現できます。
SQLServerでUpsertが必要になった時は、是非この記事を参考にしてください。








コメント