PostgreSQL、MySQL、SQLite など、主なデータベースには Window 関数なるものが備わっており、日付や値の大小で並んだデータに対して、1つ前の値との差分を計算したり、累積値を求めるようなことが簡単に出来るようになっています。
ただ、Window 関数を始めて使う人にとっては、パーティションといった考え方に戸惑うことも多いのではないかと思います。
そこで、この記事では、その肝となるパーティションの考え方をやさしく解説し、Windows関数の使い方について理解して頂くといった内容になっています。
SQLのWindow関数とは
何らかの条件で並んでいるデータに対して、特定の範囲のデータのみ参照できるようにする機能が用意されており、これをWindowと呼んでいます。
ちょうど窓を開けて全体の中の一部を覗くようなイメージでです。
そして、このWindowに対して、最大、最小、合計、平均などの集計を行う関数が用意されており、これらのことをWindow関数と呼んでいます。
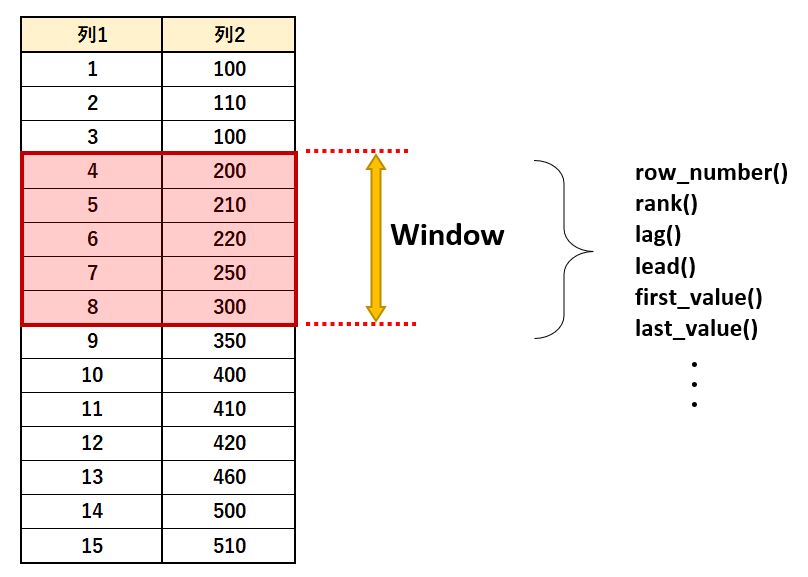
Window関数の基本
Window関数は、必ず OVER キーワードと一緒に使います。
Window関数() Over()
そして、関数と名が付く通り、実行した結果1つの値が返されます。
つまり、select 文で返される1行1行について、Window関数が実行されるのです。
従って、 Windows関数は、select文の中に記述します。
select
column1,
column2,
sum(column1) over(partition by column1 order by column2)
from hogeこのOVER() のカッコの中に、Partition by や Order by を指定することで、グルーピング(=パーティション)した中身をソートし、それぞれに対してWindows関数が実行されるのです。
では、最初に用意されているWindows関数を見てから、Partition by 、Order by の順で説明してきます。
用意されているWindows関数
用意されているWindow関数の数は、データベース製品によって多少違いますが、おおよそ以下の関数が用意されています。
| 関数名 | 内容 |
|---|---|
| AVG(カラム名) | 指定したカラムの平均を求める。 |
| COUNT(*) | 件数 を求める。 |
| MAX ( カラム名 ) | 指定したカラムの 最大 を求める。 |
| MIN ( カラム名 ) | 指定したカラムの 最小 を求める。 |
| SUM ( カラム名 ) | 指定したカラムの 合計 を求める。 |
| LAG ( カラム名 , [オフセット] , [初期値]) | 指定したカラムにおいて、前の行の値を取得する。 [オフセット] さかのぼる行数。省略した場合は1 [初期値] 値が存在しなかった場合に返される値。 省略時はNULL |
| LEAD ( カラム名 , [ オフセット ] , [ 初期値 ]) | 指定したカラムにおいて、次の行の値を取得する。 [オフセット] 先を見る行数。省略した場合は1 [初期値] 値が存在しなかった場合に返される値。 省略時はNULL |
| FIRST_VALUE ( カラム名 ) | 最初の行の値を取得する。 |
| LAST_VALUE ( カラム名 ) | 最後の行の値を取得する。 |
| ROW_NUMBER() | ソート順で1からの行番号を取得する |
| RANK() | ソート順でランク付け(1からの連番)を取得する。 同じ値がある場合、ランクは飛び番になる。 例:1,2,3,3,5,5,5,8 |
| DENSE_RANK() | ソート順でランク付け(1からの連番)を取得する。 同じ値がある場合、ランクは飛ばない。 例:1,2,3,3,4,5,5,5,6 |
Partiton by によるグルーピング
OVER の中に Partition by を書くことで、指定した項目でグループ化することが可能です。
Window関数() OVER(Partitiion by カラム1,カラム2,・・・)
これは、SQL の Group by 句 でグルーピングするのと同じ動作になります。
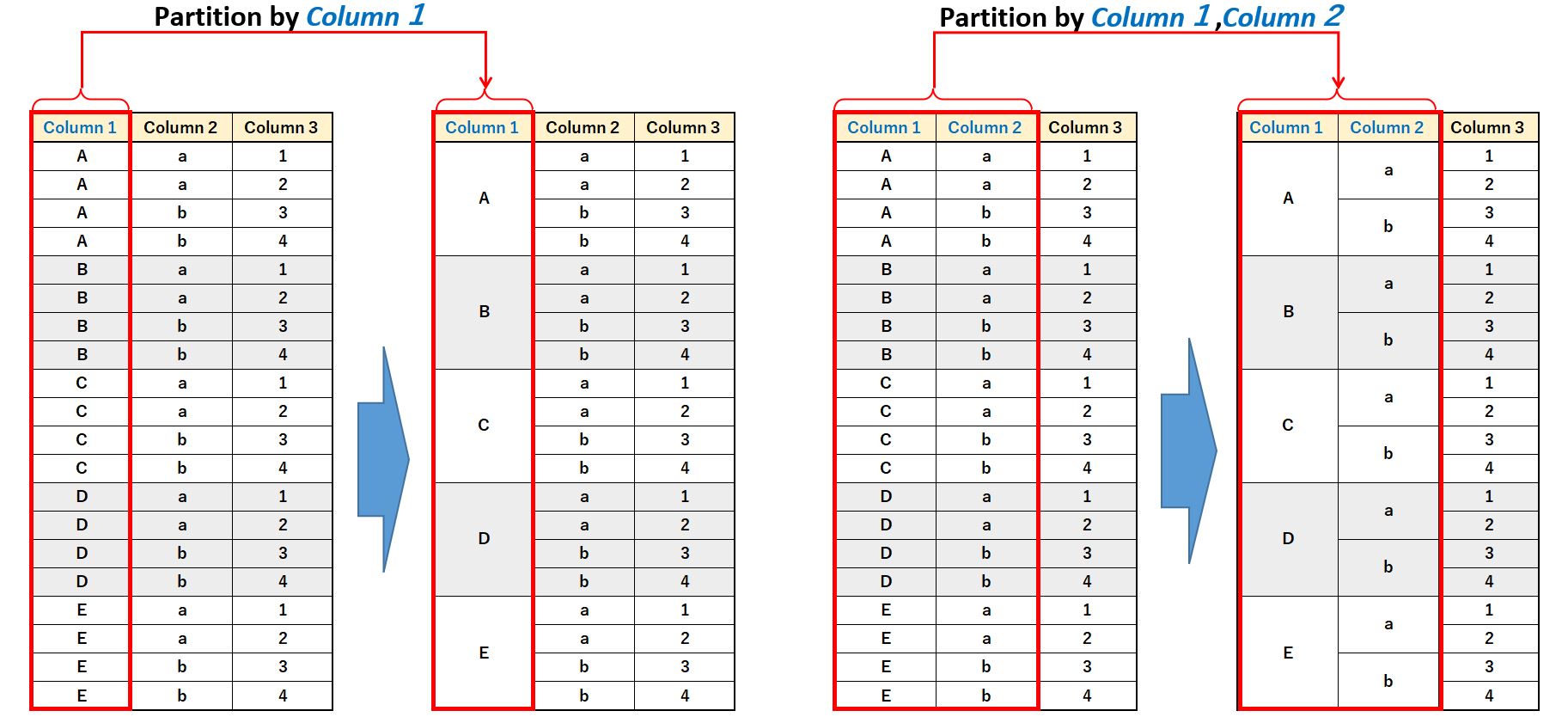
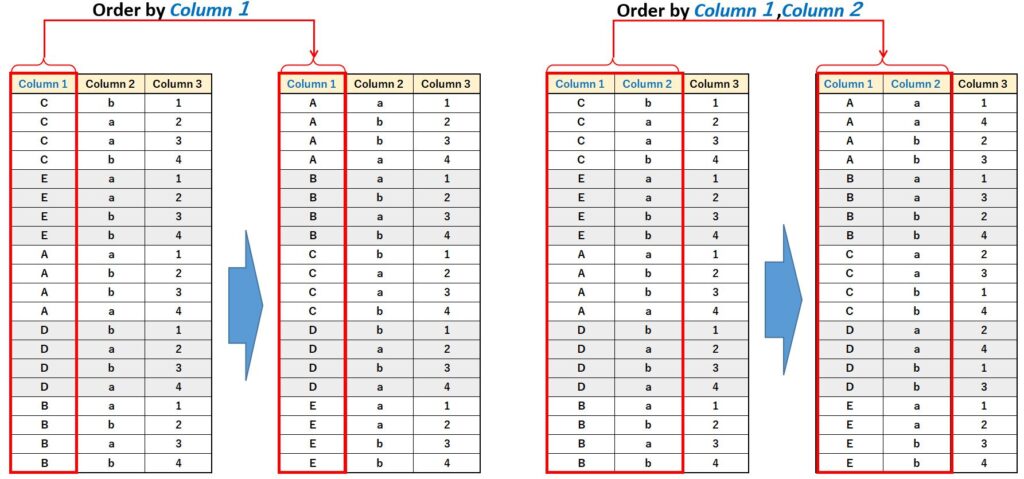
Order by によるソート
OVER の中に Order by を書くことで、指定した項目でソートすることが可能です。
Window関数() OVER(Order by カラム1,カラム2,・・・)
これも SQL の Order by 句でソートするのと同じ動作になります。
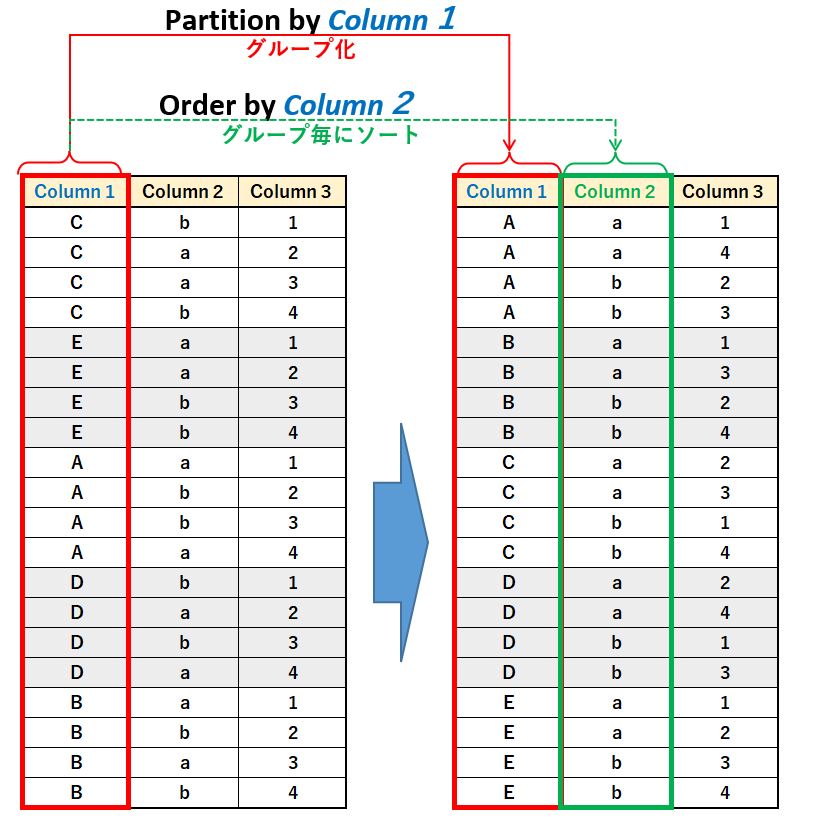
Partition by と Order by の組み合わせ
OVER() の中に Partition by と Order by を書くことで、指定したカラムでグルーピングし、それぞれのグループ内でソートすることが可能です。
Window関数() OVER(Partition by カラム1,・・・ Order by カラム1,・・・)
これを用いると、例えば店舗コードでグルーピングし、その中で売上金額でソートし、売上金額が一番多かった年月日を求めるといったことも可能になります。
Order by による集計対象範囲の指定
Over() の Order by で指定したソート対象のカラムに対して、Window関数を適用する集計対象範囲を指定することが出来ます。
集計対象範囲は「開始点」と「終了点」が指定可能であり、省略した場合は「開始点」はソートされた先頭行、「終了点」は「現在行」が採用されます。
「現在行」とは、カーソル行と表現した方が分かりやすいかもしれません。
通常、SELECT 文は、内部的にループ処理を行いながら、条件に一致する行を1行づつ順番に取り出します。
「現在行」とは、まさに今取り出した行のことを指します。
これを使うことで、指定した範囲の累積値や移動平均を求めることが出来るようになります。
尚、「開始点」「終了点」の指定の仕方には、ソートした結果の行番号を使う方法(ROWS)と、カラムの値(RANGE)を使う方法の2通り用意されています。
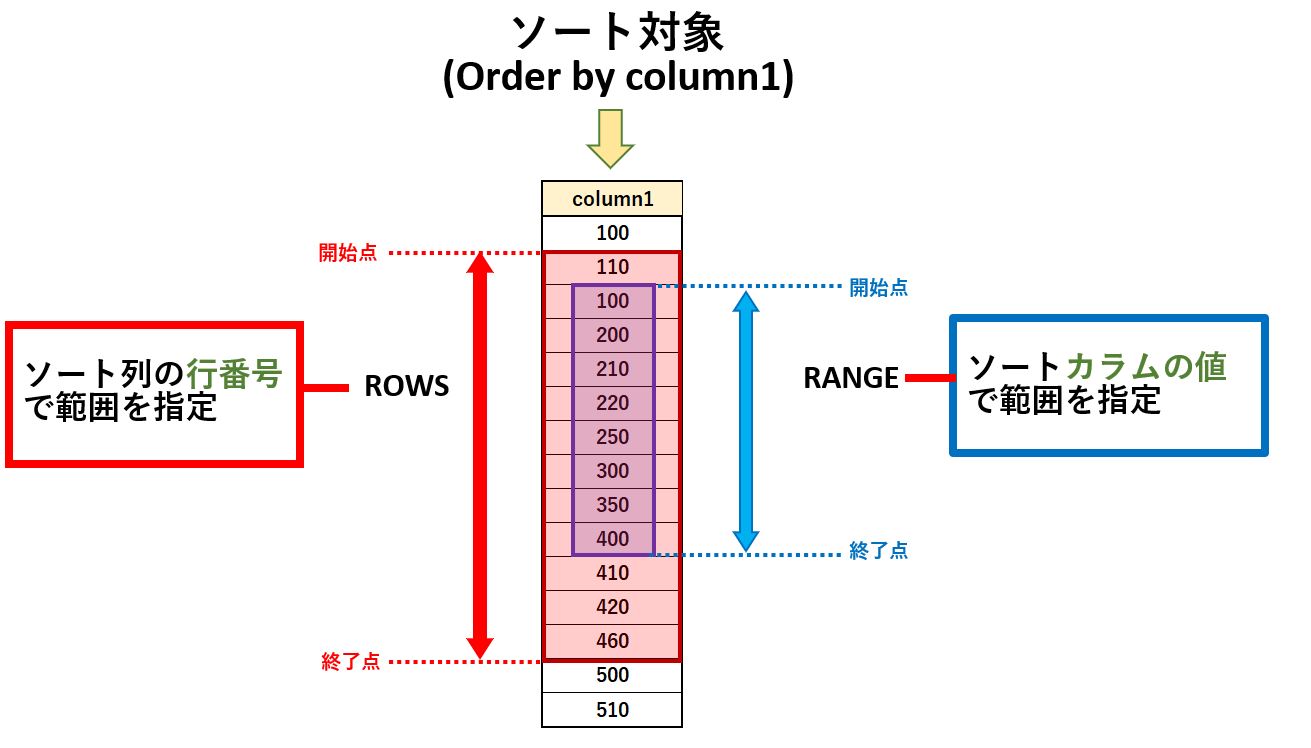
具体的な範囲指定は、次のキーワードを使います。
| キーワード | 意味 |
|---|---|
| UNBOUNDED PRECEDING | 先頭の行を指定する。終了点としては使えない。 |
| UNBOUNDED FOLLOWING | 末尾の行を指定する。開始点としては使えない。 |
| CURRENT ROW | 現在行(カーソル行) |
| <値> PRECEDING | ROWSを指定した場合は、現在行より<値>行前。 RANGEの場合はカラムの値が<値>の前。 |
| <値> FOLLOWING | ROWSを指定した場合は、現在行の値が<値>行後。 RANGEの場合はカラムの値が<値>の後。 |
上記のキーワードを「開始点」「終了点」に指定し、 BETWEEN を使って次のように表します。
ROWS BETWEEN 「開始点」 AND 「終了点」
RANGE BETWEEN 「開始点」 AND 「終了点」
ROWS BETWEEN 4 PRECEDING AND CURRENT ROWGroup by と Window関数との違い
今までの説明を読まれた方は、SQL の Group by 句や Order by 句で良いんじゃないかと思われるかもしれません。
しかし、両者には大きな違いがあります。
Group ByとOrder by の効くタイミングの違い
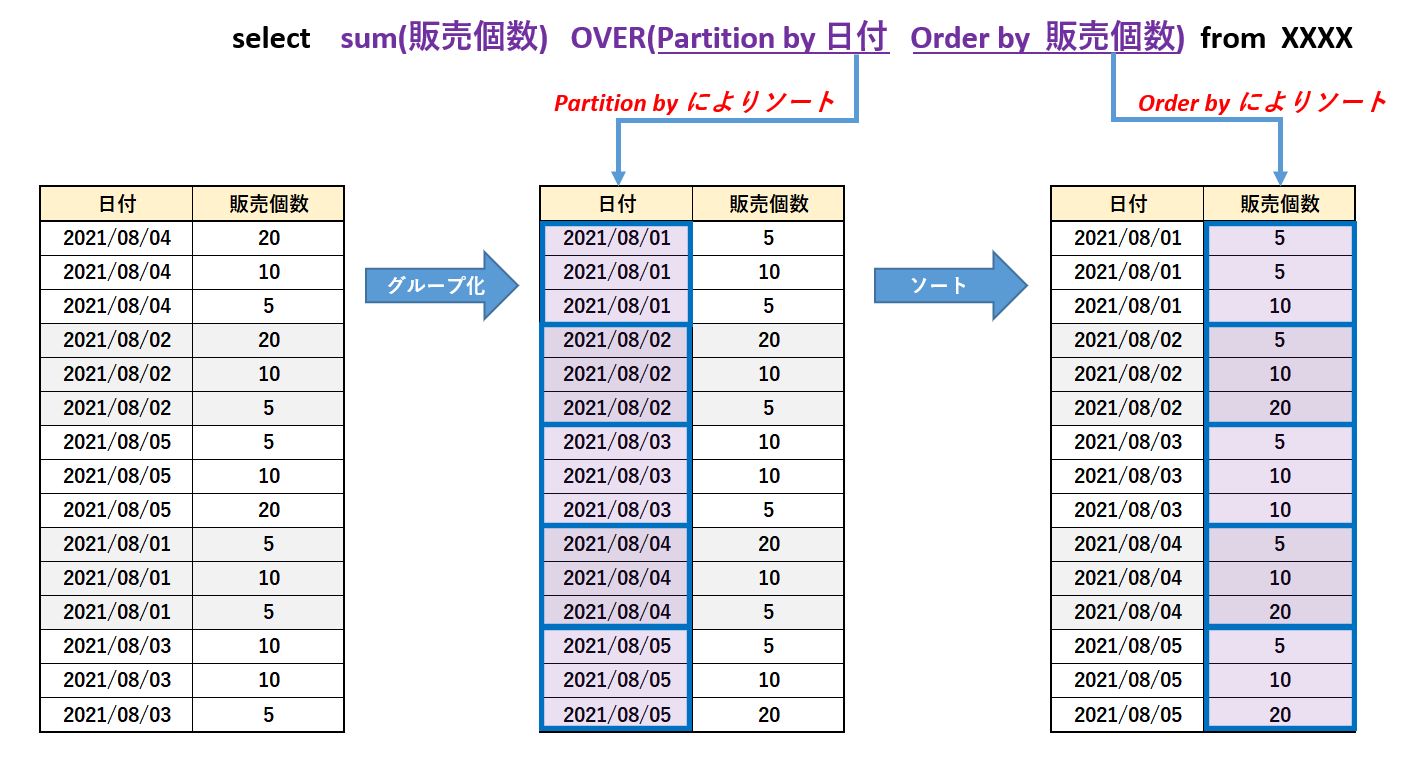
Group by 句 はグループ毎に集計を行うもので、その結果に対して Order by 句によりソートが行われます。

それに対して Window関数の Partition by と Order by は、グループ毎にグループの中身をソートするという違いがあります。
ちなみに、下図は sum(販売個数)の計算前の結果をイメージで表したものです。
sum(販売個数)の挙動は次の章で説明します。
集計結果の現れ方の違い
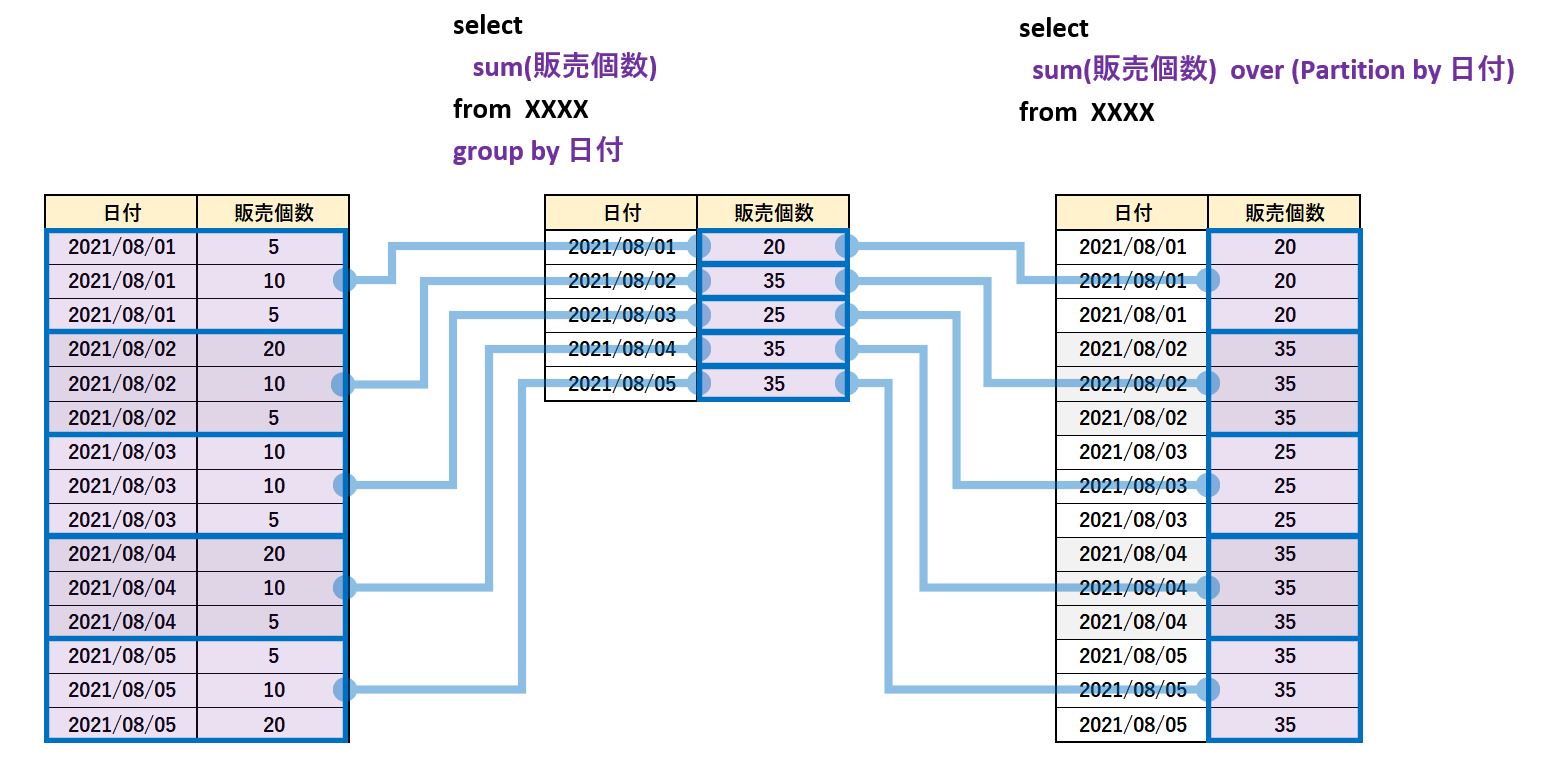
集計結果の現れ方は、Group By 句と Partition by では全く異なります。
先ほどの説明と重複しますが、Group By 句 やグルーピングして出来上がったグループに対して、それぞれに集計結果が計算され、その結果が Order by 句 でソートされます。
一方、OVER() では、 Partition by で グルーピングされ、さらにその中で Order by によってソートされ、その集計結果がそれぞれの行に付加されます。
当然といえば当然の結果なのですが、Window関数は select 句 の中に記述しているので、結果として返される1行1行に集計結果が返って来ます。
良く使われるWindow関数のサンプル
では、良く使われるサンプルのSQLをいくつか紹介しておきます。ご自身のテーブルや条件に合わせてカスタマイズの上、お使いください。
累積
累積を求める場合は次のように記述します。
ROWS UNBOUNDED PRECEDING と記述することで、行番号による指定を行い、「開始点」はソート範囲の先頭を指定しています。
「終了点」は省略していますので、「現在行」が指定されたことになります。
SELECTで1行取り出しては、「先頭行」から「現在行」までの値をsum() で合計する=累積するという動作を行っています。
select
"日付",
"ページビュー",
SUM("ページビュー") OVER(ORDER BY "日付" ROWS UNBOUNDED PRECEDING) as 累積
from v_収益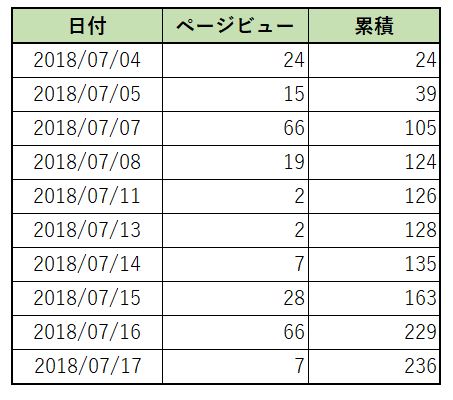
1つ前の値(差分)
1つ前の値を求める場合は lag を使用して次のように記述します。
lagの第2引数はオフセット値(何個前の値を参照するか)であり、1の場合は省略可能です。
差分を求める場合、現在値から1つ前の値を引くことで計算できます。
select
"日付",
"ページビュー",
LAG("ページビュー",1) OVER(ORDER BY "日付") as 1つ前の値
from v_収益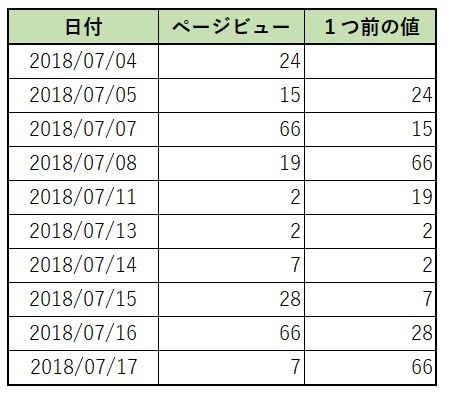
移動平均
移動平均は、 ROWS BETWEEN 件数 PRECEDING AND CURRENT ROW と記述することで実現できます。
サンプルでは BETWEENを使って 4 PRECEDING(=現在行より4つ前) から CURRENT ROW (=現在行)の範囲をしていしていますので、現在行を含めて5点の移動平均を求めています。
select
"日付",
"ページビュー",
AVG("ページビュー") OVER(ORDER BY "日付" ROWS BETWEEN 4 PRECEDING AND CURRENT ROW) as 移動平均
from v_収益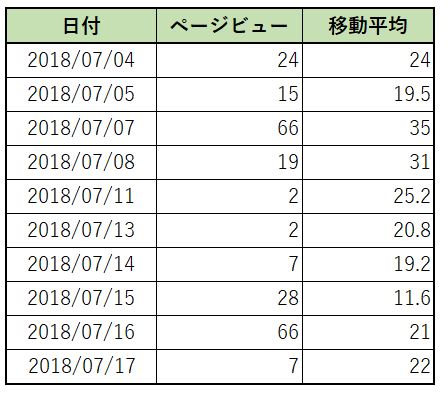
結果を見ていただけると分かると思いますが、この移動平均は '2018/07/04' の結果は1件の平均、'2018/07/05' の結果は2件の平均・・・という具合に、移動平均で指定した件数に達していない場合でも平均を計算します。
5つ揃わない時は計算したくない場合は、結果を受取ってから最初の結果を削除するなどの工夫が必要です。
まとめ
今回は SQL の Window関数における Partition by や order by の考え方、SQLのGroup by や Order by との違い、良く使われる Window関数に使用例について紹介しました。
従来は自分自身に条件を付けて結合する(自己結合)でしか実現できなかった集計が、Window関数を使えばいとも簡単に実現できてしまいます。
最初のうちは少し取っつきにくいかもしれませんが、覚えれば大変便利ですので、まだ使ったことの無い方は、是非お試しください。
この記事が皆様のプログラミングやSQLによる集計の一助になれば幸いです。








コメント