今まではバッチ処理といえばJavaかC#だったんですが、最近はAIブームの影響を受けてか、Pythonによるバッチ処理も増えてきています。
Pythonはインタープリタ(逐次実行)型の言語であるため、処理速度はJavaやC#に劣ると言われてきましたが、実際はどうでしょう?
一説によると、Pythonのライブラリ(pandas や numpy)を使うと、処理速度はC#やPythonに引けを取らないという説もあります。
仕事でC#の処理をPythonに移植することになったので、これを機にケースごとの処理速度を計測してみましたので、紹介します。
実験の概要と注意事項
今回の実験は、C#、C#スクリプト、Pythonの3種類の言語に対して、次の5種類の実験を行い、速度計測(各10回づつ実施した平均値を採用)をしました。
- 一覧形式のデータに対して、列を追加する(関数名=func1)
- 一覧形式のデータに対して、行番号と列名でセルを指定して値を更新(関数名=func2)
- 一覧形式のデータに対して、欠損値(NaN)に0を代入(関数名=func3)
- クラスのインスタンス生成(関数名=func4)
- リストデータへのデータ追加(関数名=func5)
ここで登場する一覧形式のデータは、C#とC#スクリプトについては DataTable を、Pythonについては Panda の DataFrameを使いました。
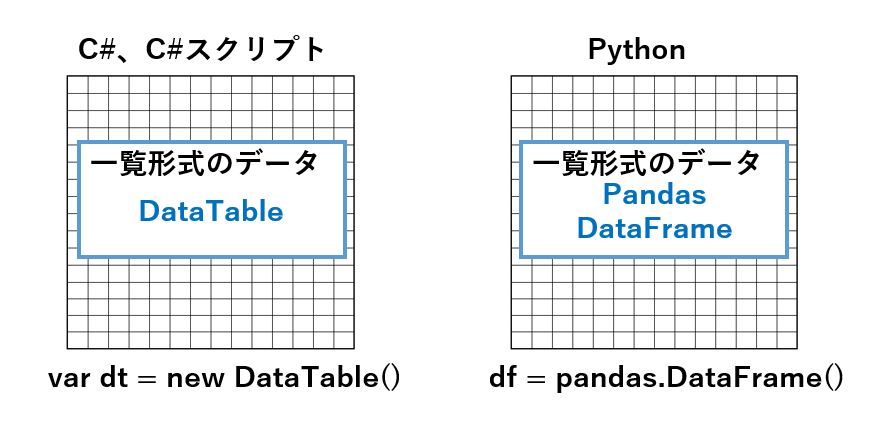
C#については、Visual Studioのデバッグを前提としたデバッグ用ビルドとリリースを前提としたリリース用ビルド+最適化オプション=ONの2通りについても計測しております。
| デバッグ用ビルド | Visual Studioのデバッグを前提としたコードが埋め込まれ、 且つ処理速度の最適化が図られていない。 Visual Studioの初期設定はこの状態。 |
| リリース用ビルド + 最適化=ON | Visual Studioのデバッグ用コードが除外される。 リリース用ビルドのみ「最適化オプション」有効にできるので、 今回はONにした。 これにより、処理速度向上の為にコードが最適化される。 |
実験環境(PC)のスペックは次の通りです。
| 項目 | 内容 |
|---|---|
| OS | Windows 10 Pro 20H2 |
| CPU | Intel(R) Core(TM) i5-9400 (6コア6スレッド)2.90GHz |
| メモリ | 32.0 GB |
実験結果サマリ
計測結果は次のようになりました。
| 関数名 | 説明 | C#最適化ON | C#最適化OFF | C#スクリプト | python |
|---|---|---|---|---|---|
| func1 | 一覧形式データへの列追加 | 0.02370 | 0.03875 | 0.02366 | 0.02895 |
| func2 | 行Noと列名を指定したセルへの値の代入 | 0.03640 | 0.03911 | 0.03724 | 1.57433 |
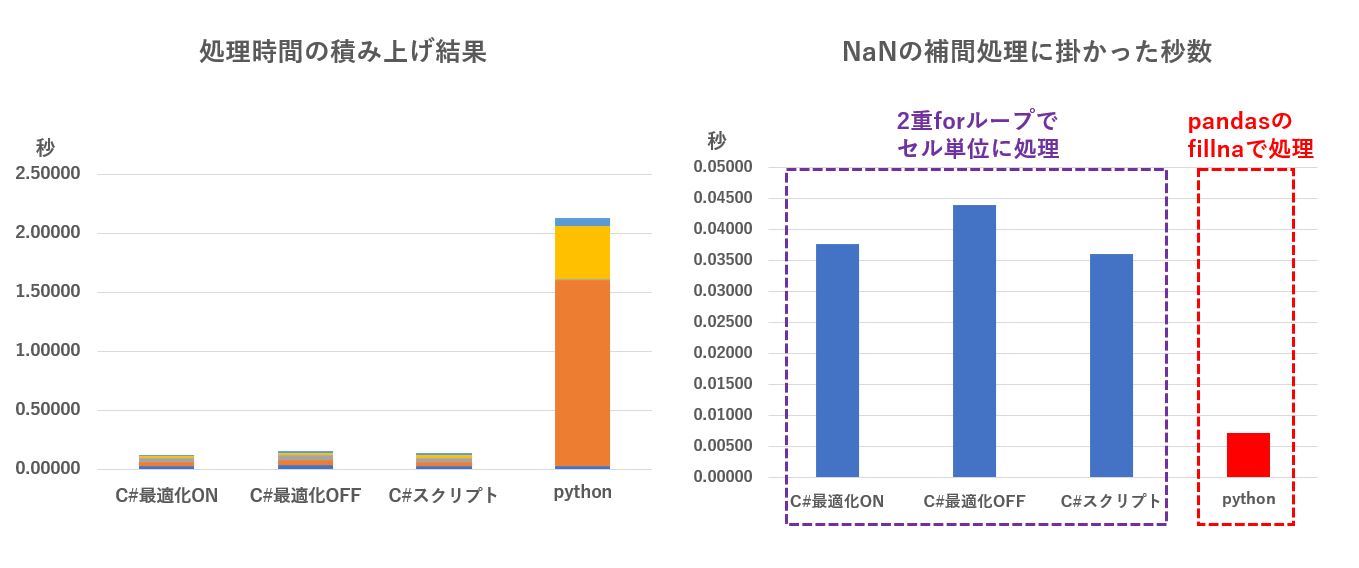
| func3 | NaNの補間処理 | 0.03761 | 0.04387 | 0.03593 | 0.00715 |
| func4 | クラスの呼び出し (100万回) | 0.01511 | 0.02004 | 0.02759 | 0.44559 |
| func5 | リストへの値の追加 (100万回) | 0.01040 | 0.01052 | 0.01629 | 0.07438 |
下記は、C#の最適化をOFF(Visual Studioの初期状態)にした処理速度を1にした時の倍率です。
| 関数名 | 説明 | C#最適化ON | C#最適化OFF | C#スクリプト | python |
|---|---|---|---|---|---|
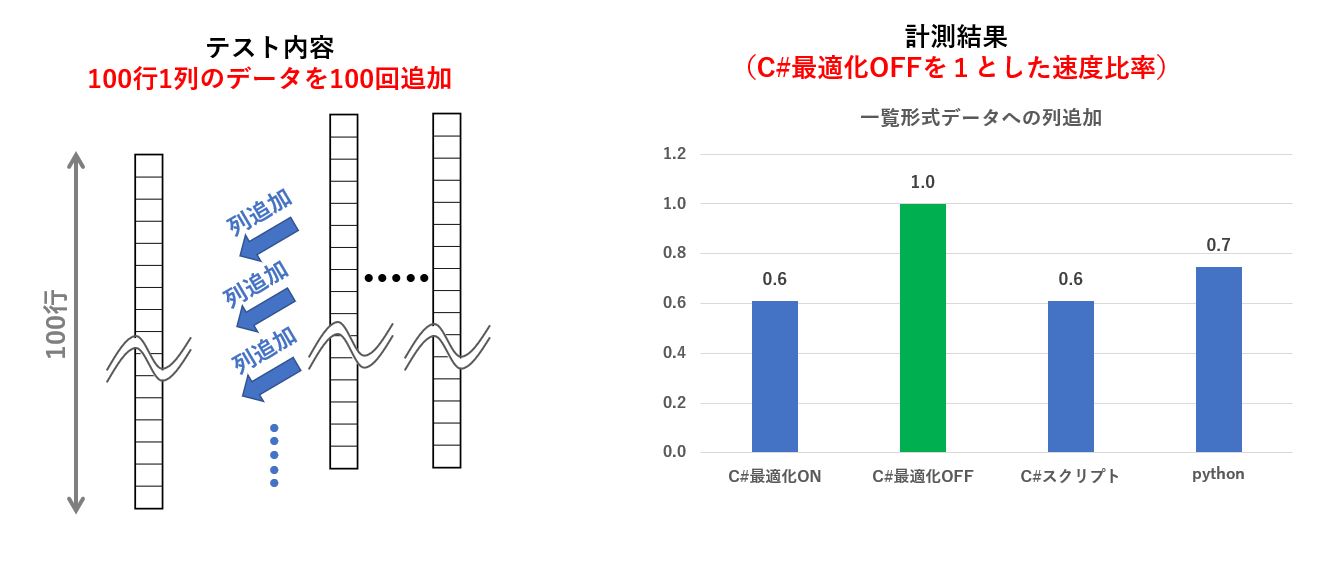
| func1 | 一覧形式データへの列追加 | 0.6 | 1.0 | 0.6 | 0.7 |
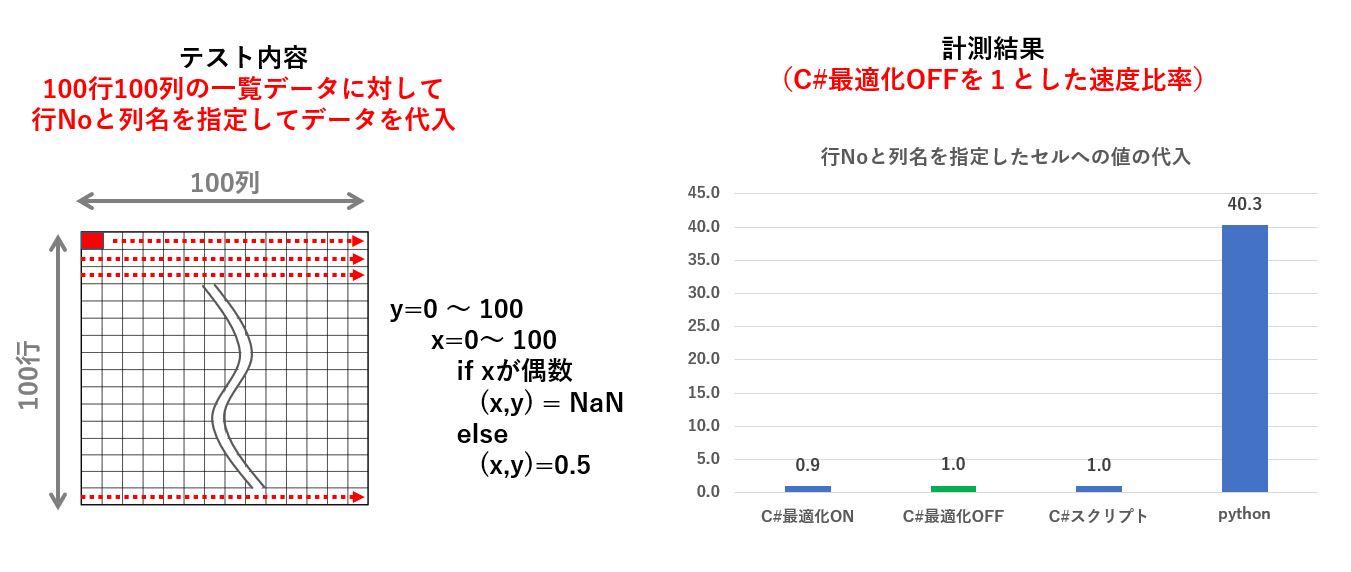
| func2 | 行Noと列名を指定したセルへの値の代入 | 0.9 | 1.0 | 1.0 | 40.3 |
| func3 | NaNの補間処理 | 0.9 | 1.0 | 0.8 | 0.2 |
| func4 | クラスの呼び出し | 0.8 | 1.0 | 1.4 | 22.2 |
| func5 | リストへの値の追加 | 1.0 | 1.0 | 1.5 | 7.1 |
総合的に分析すると、やはりC#に比べてPythonは圧倒的に遅いというのが分かります。
特にループの中で何らかの処理を行う場合の速度低下は顕著です。
しかし、Pythonの欠損値補間は pandas の fillna で行ったのですが、このケースのみ Python の方が圧倒的に高速です。
よく言われることですが、やはりPython の数値計算系ライブラリ(pandas や numpy)は C++で書かれてあるだけに高速ですね。
Pythonでもうまく処理すればC#やJavaより高速なバッチ処理が行えるという事が言えそうです。
個々の計測結果
では、それぞれの計測結果について、もう少し詳しく見ていきます。
func1 :一覧形式のデータに対して、列を追加する)
この実験は空のDataTable 又は DataFrame に対して、100行1列のデータを100回追加するという内容です。
意外なことに、C#でビルドしたものより、C#スクリプトで記述した方が高速でした。
C#スクリプトの方が多少なりとも最適化されているということなんでしょうか。
また、Pythonの場合は DataFrame に列を追加するのは高速に処理されるようで、C#の場合とほぼ互角と言ったところです。
下記はテストコードですが、この手の処理はPythonの方が圧倒的にコード量が少なく手済みますね。
for(int i = 0;i < COUNT;i ++)
{
dt.Columns.Add("Col" + i.ToString(),typeof(double));
if(i == 0)
{
Enumerable.Range(0, COUNT).Select(j => dt.Rows.Add()).ToArray();
}
Enumerable.Range(0, COUNT).Select(j => dt.Rows[j][i] = j).ToArray();
}
for i in range(COUNT):
df['Col'+str(i)] = [x for x in range(COUNT)]func2 :一覧形式のデータに対して、行番号と列名でセルを指定して値を更新
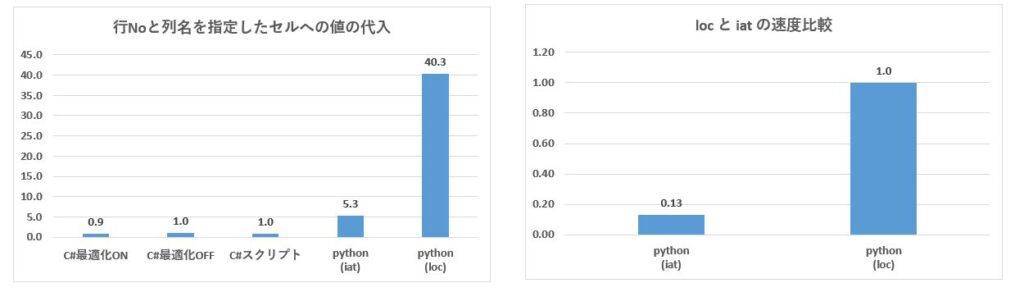
この実験は2重ループを使って、個々のセルに対して値を代入するという内容です。
Xの値が偶数ならNaNを、奇数なら0.5 を代入していますので、これで全データ(100行×100列=1万セル)の半分にNaNが代入されます。
Pythonはループ処理が遅いと言われていますが、この実験ではC#最適化OFFの場合と比較して40倍も遅いということが分かります。
for(int y = 0;y < COUNT;y++)
{
for(int x = 0;x < COUNT;x ++)
{
dt.Rows[y][x] = (x % 2 == 1) ? 0.5 : double.NaN;
}
}for y in range(COUNT):
for x in range(COUNT):
df.loc[y,'Col'+str(x)] = 0.5 if x % 2 == 1 else NaN今回はあえて列名を使っていますが、もし行と列を指定して何かを行う場合は、iat メソッドの方が6k~7倍高速です。
| セルの指定メソッド | 処理時間(秒) | locの速度を1とした時の倍率 |
|---|---|---|
| DataFrameのセルを loc で指定した場合 | 1.57433 | 1 |
| DataFrameのセルを iat で指定した場合 | 0.20682 | 0.13 |
for y in range(COUNT):
for x in range(COUNT):
df.iat[y,x] = 0.5 if x % 2 == 1 else NaNfunc3 :一覧形式のデータに対して、欠損値(NaN)に0を代入
この実験は、func3の結果に対してNaNを0に置き換えるものですが、C#の場合は2重ループで実現しているのに対し、Pythonは fillna メソッドを使っています。
つまり、Python ライブラリを使うことで速度がどれくらい速くなるのかを調べるためのものです。
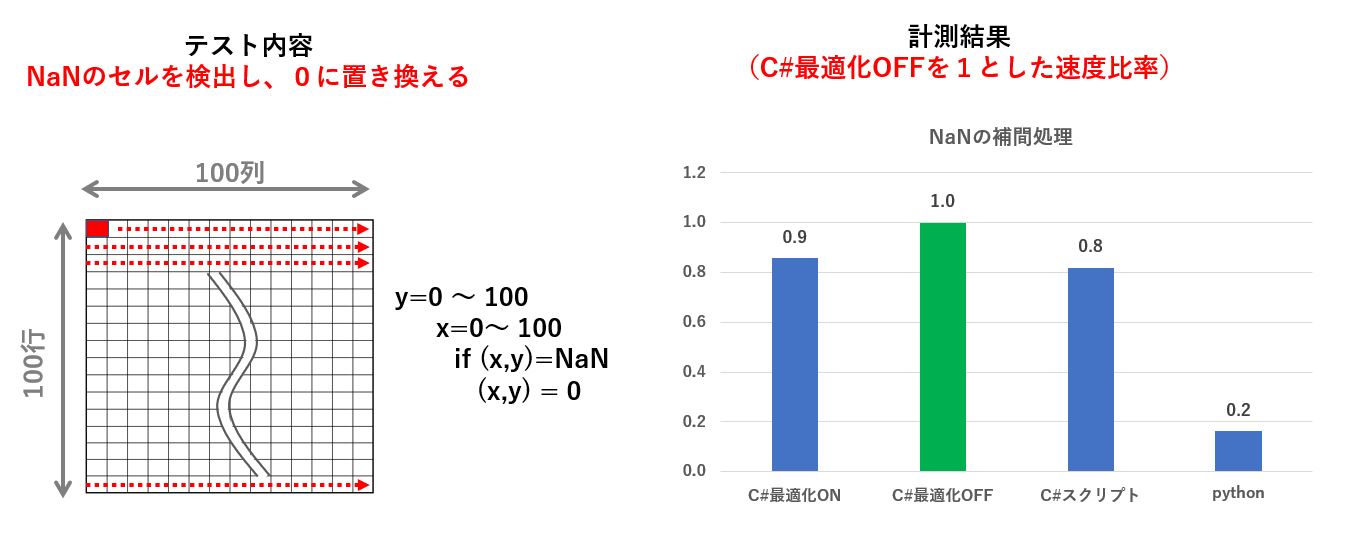
思った通り、Python がC# に比べて約5倍速いことが分かりました。
for (int y = 0; y < COUNT; y++)
{
for (int x = 0; x < COUNT; x++)
{
dt.Rows[y][x] = (double.IsNaN((double)dt.Rows[y][x])) ? 0.0 : dt.Rows[y][x];
}
}for i in range(COUNT):
df.fillna(0.0)func4 :クラスのインスタンス生成
この実験は、単純にクラスのインスタンスを生成する速度がどれくらいかを調べるためのものです。
C#に比べてPythonは22倍遅いので、例えばデータベースから取得した何万件もデータを、1つづつ個々のクラスに格納するような使い方は避けた方が無難です。
ちなみに、Python で単純に100万回ループするのに掛かる時間は0.02秒と小さく、十分無視できる時間であるため、インスタンス生成時間が22倍遅いと考えられます。

for(int i = 0;i < COUNT * COUNT * COUNT; i ++)
{
new myclass(i, i * i, i * i * i);
}for i in range(COUNT * COUNT* COUNT):
myclass(i,i*i,i*i*i)func5 :リストデータへのデータ追加
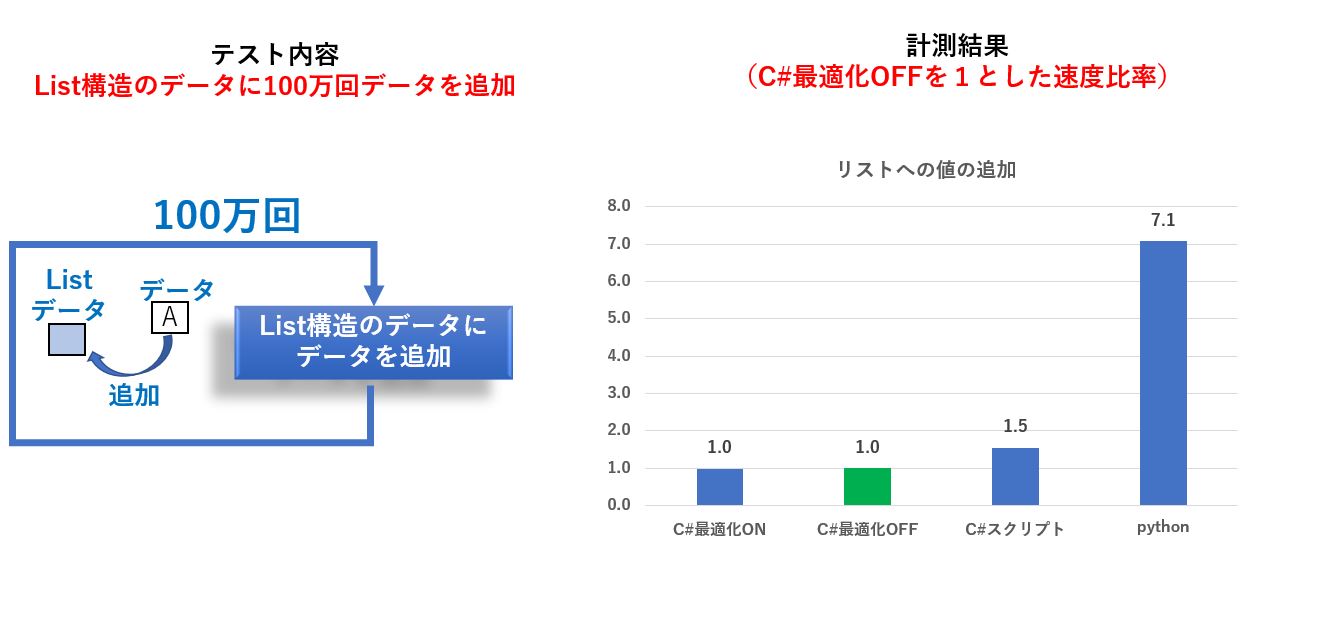
この実験は、リストに大量のデータを格納する場合の処理速度を調べるためのものです。
結果を見ると、やはりPythonの方が7倍程度遅いですね。
List<object> list = new List<object>();
for (int i = 0;i < COUNT * COUNT * COUNT;i ++)
{
list.Add("ABCDEFGHIJKLMNOPQRSTUVWXYZ");
}list = []
for i in range(COUNT * COUNT* COUNT):
list.append('ABCDEFGHIJKLMNOPQRSTUVWXYZ')実験で使ったソースコード一式
C#のソースコード
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Diagnostics;
using System.Data;
namespace speeddemo
{
class Program
{
const int COUNT = 100;
const int RETRY = 10;
static void Main(string[] args)
{
DataTable dt = new DataTable();
Console.WriteLine("func1 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt.Copy(), func1)).Average());
func1(dt);
Console.WriteLine("func2 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt.Copy(), func2)).Average());
func2(dt);
Console.WriteLine("func3 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt.Copy(), func3)).Average());
Console.WriteLine("func4 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt, func4)).Average());
Console.WriteLine("func5 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt, func5)).Average());
Console.ReadKey();
}
static double measurement(DataTable dt,Action<DataTable> func)
{
Stopwatch stopWatch = new Stopwatch();
stopWatch.Start();
func(dt);
stopWatch.Stop();
return stopWatch.Elapsed.TotalSeconds;
}
static void func1(DataTable dt)
{
for(int i = 0;i < COUNT;i ++)
{
dt.Columns.Add("Col" + i.ToString(),typeof(double));
if(i == 0)
{
Enumerable.Range(0, COUNT).Select(j => dt.Rows.Add()).ToArray();
}
Enumerable.Range(0, COUNT).Select(j => dt.Rows[j][i] = j).ToArray();
}
}
static void func2(DataTable dt)
{
for(int y = 0;y < COUNT;y++)
{
for(int x = 0;x < COUNT;x ++)
{
dt.Rows[y][x] = (x % 2 == 1) ? 0.5 : double.NaN;
}
}
}
static void func3(DataTable dt)
{
for (int y = 0; y < COUNT; y++)
{
for (int x = 0; x < COUNT; x++)
{
dt.Rows[y][x] = (double.IsNaN((double)dt.Rows[y][x])) ? 0.0 : dt.Rows[y][x];
}
}
}
static void func4(DataTable dt)
{
for(int i = 0;i < COUNT * COUNT * COUNT; i ++)
{
new myclass(i, i * i, i * i * i);
}
}
static void func5(DataTable dt)
{
List<object> list = new List<object>();
for (int i = 0;i < COUNT * COUNT * COUNT; i ++)
{
list.Add("ABCDEFGHIJKLMNOPQRSTUVWXYZ");
}
}
}
class myclass
{
private object Val1;
private object Val2;
private object Val3;
public myclass(object val1,object val2,object val3)
{
Val1 = val1;
Val2 = val2;
Val3 = val3;
}
}
}
C#スクリプトのソースコード
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Diagnostics;
using System.Data;
const int COUNT = 100;
const int RETRY = 10;
DataTable dt = new DataTable();
Console.WriteLine("func1 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt.Copy(), func1)).Average());
func1(dt);
Console.WriteLine("func2 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt.Copy(), func2)).Average());
func2(dt);
Console.WriteLine("func3 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt.Copy(), func3)).Average());
Console.WriteLine("func4 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt, func4)).Average());
Console.WriteLine("func5 {0} sec", Enumerable.Range(0,RETRY).Select(i => measurement(dt, func5)).Average());
double measurement(DataTable dt,Action<DataTable> func)
{
Stopwatch stopWatch = new Stopwatch();
stopWatch.Start();
func(dt);
stopWatch.Stop();
return stopWatch.Elapsed.TotalSeconds;
}
void func1(DataTable dt)
{
for(int i = 0;i < COUNT;i ++)
{
dt.Columns.Add("Col" + i.ToString(),typeof(double));
if(i == 0)
{
Enumerable.Range(0, COUNT).Select(j => dt.Rows.Add()).ToArray();
}
Enumerable.Range(0, COUNT).Select(j => dt.Rows[j][i] = j).ToArray();
}
}
void func2(DataTable dt)
{
for(int y = 0;y < COUNT;y++)
{
for(int x = 0;x < COUNT;x ++)
{
dt.Rows[y][x] = (x % 2 == 1) ? 0.5 : double.NaN;
}
}
}
void func3(DataTable dt)
{
for (int y = 0; y < COUNT; y++)
{
for (int x = 0; x < COUNT; x++)
{
dt.Rows[y][x] = (double.IsNaN((double)dt.Rows[y][x])) ? 0.0 : dt.Rows[y][x];
}
}
}
void func4(DataTable dt)
{
for(int i = 0;i < COUNT * COUNT * COUNT; i ++)
{
new myclass(i, i * i, i * i * i);
}
}
void func5(DataTable dt)
{
List<object> list = new List<object>();
for (int i = 0;i < COUNT * COUNT * COUNT;i ++)
{
list.Add("ABCDEFGHIJKLMNOPQRSTUVWXYZ");
}
}
class myclass
{
private object Val1;
private object Val2;
private object Val3;
public myclass(object val1,object val2,object val3)
{
Val1 = val1;
Val2 = val2;
Val3 = val3;
}
}Pythonのソースコード
from numpy import NaN
import pandas as pd
import statistics
import time
COUNT = 100
RETRY = 10
class myclass:
def __init__(self,val1,val2,val3):
self.val1 = val1
self.val2 = val2
self.val3 = val3
def measurement(df,func):
start_time = time.perf_counter()
func(df)
return time.perf_counter() - start_time
def func1(df):
for i in range(COUNT):
df['Col'+str(i)] = [1.0*x for x in range(COUNT)]
def func2(df):
for y in range(COUNT):
for x in range(COUNT):
df.loc[y,'Col'+str(x)] = 0.5 if x % 2 == 1 else NaN
def func3(df):
for i in range(COUNT):
df.fillna(0.0)
def func4(df):
for i in range(COUNT * COUNT* COUNT):
myclass(i,i*i,i*i*i)
def func5(df):
list = []
for i in range(COUNT * COUNT* COUNT):
list.append('ABCDEFGHIJKLMNOPQRSTUVWXYZ')
df = pd.DataFrame()
print("func1 {0} sec".format(statistics.mean([measurement(df.copy(),func1) for i in range(RETRY)])))
func1(df)
print("func2 {0} sec".format(statistics.mean([measurement(df.copy(),func2) for i in range(RETRY)])))
func2(df)
print("func3 {0} sec".format(statistics.mean([measurement(df.copy(),func3) for i in range(RETRY)])))
print("func4 {0} sec".format(statistics.mean([measurement(df,func4) for i in range(RETRY)])))
print("func5 {0} sec".format(statistics.mean([measurement(df,func5) for i in range(RETRY)])))
まとめ
今回はC#、C#スクリプト、Pythonの速度比較について実験してみました。
C#やC#スクリプトの方が圧倒的に早いので、 for ループを多用してゴリゴリ各場合は C#を使った方が処理速度を速くできます。
一方Python の場、ループ処理を使わず numpy や pandas などのライブラリが提供するメソッドの組み合わせで事が足りるのであれば、python の方が処理を速くできそうです。
もし C#の処理をPythonに置き直すのであれば、ループを極力減らして、ライブラリの機能で置き換えていくという事に注力すべきです。
今回の記事がPythonの開発のお役に立てれば幸いです。








コメント