Python をインストールすると、もれなくSQLiteが付いてきます。
つまり、Pythonにとって、SQLiteは標準データベースなんですね。
しかし、Pythonの公式サイトは今一分かり難いし、かと言ってネットでググっても断片的な情報しか出てきません。
そこで、この記事では実際のアプリで使う事を前提に、必要となるメソッドと使い方について解説したいと思います。
SQLiteに関する特徴や仕様、実用上の注意点を理解しておきたい方は、「【ポイント解説】知っておきたいSQLiteの仕様と注意事項」をご一読下さい。
一通りの機能をクラス化して「【コピペで完了】9割の機能を網羅!PytonからSQLiteを扱うクラスを作ってみました。」の記事で公開していますので、すぐ使いたい方は合わせてご覧下さい。

最初の準備
Pythonをインストールすると標準でSQLiteがインストールされています。
単純にインポートすればOKです。
import sqlite3データベースの作成
SQLiteのデータベースは単一ファイルで構成されており、データベースの作成は connect メソッドを呼ぶだけで完了します。
sqlite3.connect(ファイル名)
このメソッドを呼ぶと、既にデータベースファイルが存在していればデータベースに接続し、存在しなければ新しくデータベースを作成してくれます。
ファイル名の代わりに ':memory:' という文字列を指定すると、メモリ上にデータベースが構築されます。
いわゆるインメモリデータベースです。
メモリに余裕があり、高速な処理を行いたい時には有効ですが、close メソッドを呼ぶと内容が消えてしまいますので、あくまでも一時的な使い方に適しています。
話は変わりますが、この connect に関して2点ほど注意点があります。
close 処理は忘れずに
1つ目は、close 処理の問題です。
connect メソッドを呼ぶとコネクションクラスのインスタンスが生成されます。
一般的にはこのまま放置していても問題ありませんが、多少なりともメモリを消費してしまうため、あまり良い事ではありません。
connect メソッドを呼んだら、そのインスタンスを使って closeメソッドを呼び出すことを心がけましょう。

パスの区切り文字はスラッシュ'/'が無難
Windowsの場合、パスの区切りは '¥' マークを使いますが、Pythonでパスを記述する場合は 'D:\\notepc.db' の様に'¥' マークを2回書いてエスケープしなければなりません。
このエスケープ処理は面倒ですし、ついつい忘れがちです。
Python では スラッシュ '/' も区切り文字として使えますので、こちらを使用する方が楽です。

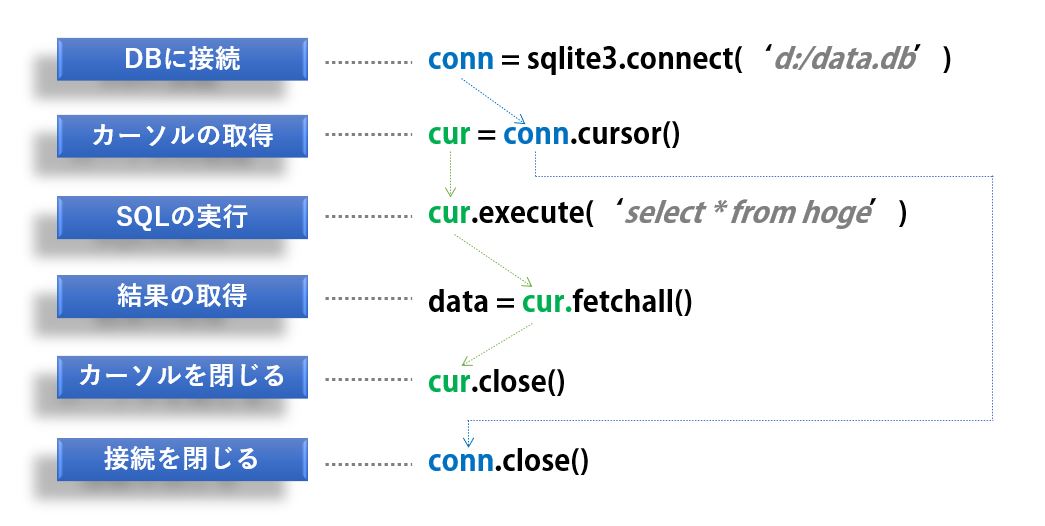
データベースの操作
SQLiteのデータベースを操作する場合、「DBに接続」「カーソルを取得」「SQLの実行」「カーソルを閉じる」「接続を閉じる」という手順が必要です。
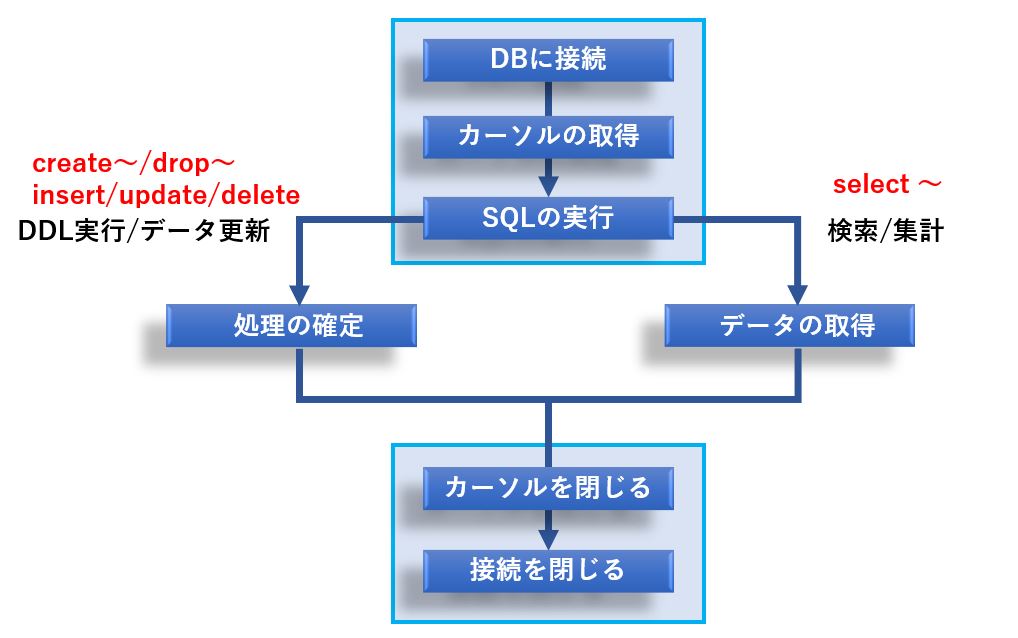
この章では、テーブル作成やテーブル名変更などを行うSQL、いわゆるDDL (Data Definition Language)と、テーブルへのデータの挿入/変更/削除を行う場合の2パターンについて、それぞれ解説します。
DDL(Data Definition Language)を実行する場合
DDLはトランザクションが効かないので、コミットやロールバックを省略することが可能です。
従って次のように書くことが出来ます。
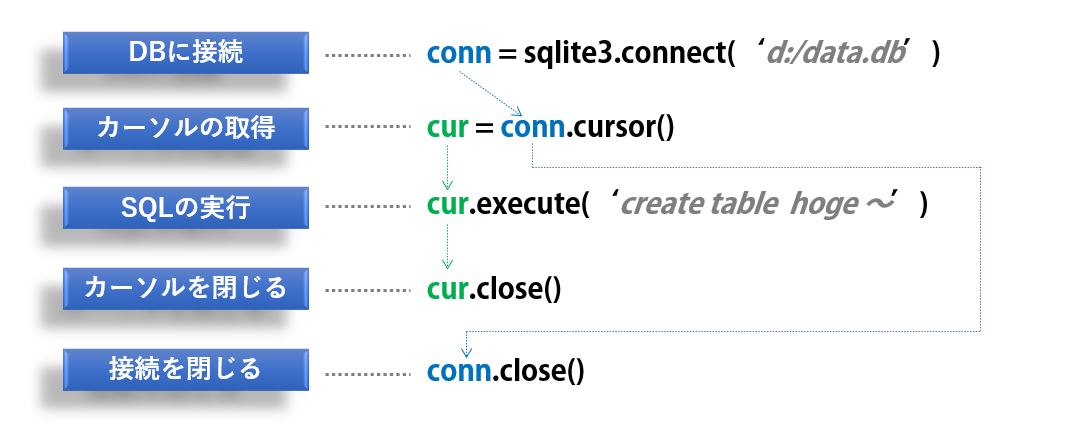
import sqlite3
conn = sqlite3.connect("d:/data.db")
cur=conn.cursor()
cur.execute("create table mytable(name text,age int)")
cur.close()
conn.close()カーソルを取得せず、connに実装されているexecute メソッドを使っても同じことが出来ます。
実は、conn.execute を実行するとカーソルのインスタンスが返され、メモリに残ったままになります。
一般的な使い方では問題ありませんが、前述の様に明示的にカーソルを取得して使い終わったらclose するという書き方の方が良いでしょう。
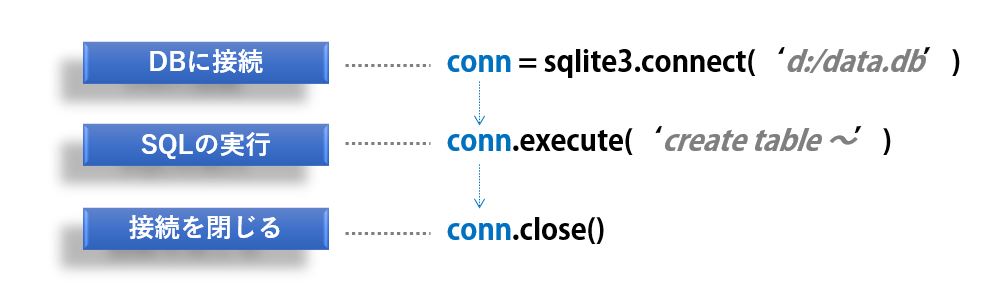
import sqlite3
conn = sqlite3.connect("d:/data.db")
conn .execute("create table mytable(name text,age int)")
conn.close()データの挿入/変更/削除を実行する場合
こちらはトランザクションが前提となるため、コミットが必要になります。
ちなみに、Pythonの場合、特に指定しない限りconnectメソッド実行と同時にトランザクションが開始されています。
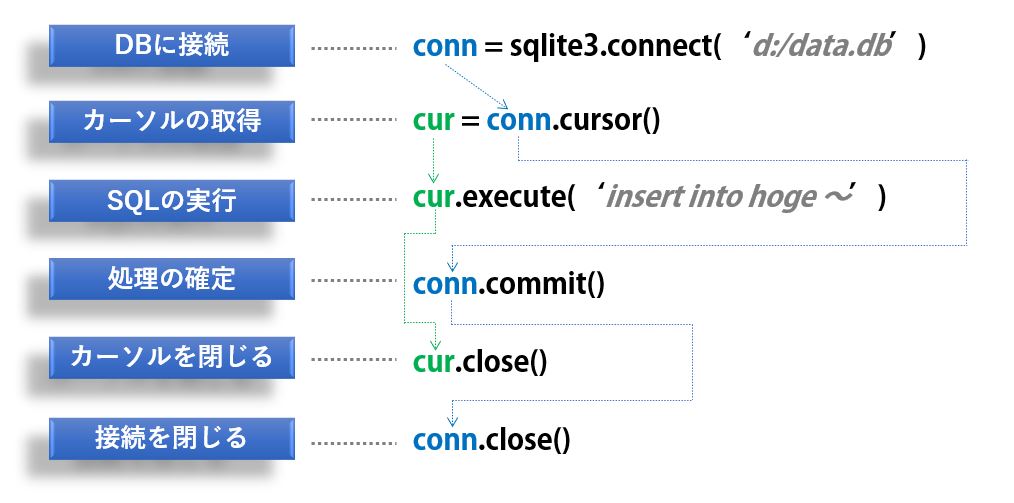
import sqlite3
conn = sqlite3.connect("d:/data.db")
cur=conn.cursor()
cur.execute("insert into mytable values('山田',25)")
conn.commit()
cur.close()
conn.close()もちろん、DDLを実行した後にコミットをしても問題ないので、DDLとデータの挿入/変更/削除を連続して行わせても構いません。
ちなみに、エラーが発生したり、処理を中断した時に元に戻したい時は、conn.rollback() メソッドを使います。
データベースの作成
データベースを作成するには、sqlite3.connectメソッドを使います。
conn = sqlite3.connect(データベースファイル名)
テーブルの作成と削除
テーブルの作成や削除はDDLであるため、直接コネクションのインスタンスからSQLを実行できます。
ここでは、コネクションを使う方法とカーソルを使う方法の2通りについてサンプルを提示しておきます。
# data.db に pc という名前のテーブルを作成するサンプル
import sqlite3
conn = sqlite3.connect("D:\data.db")
cur = conn.cursor()
cur.execute('create table pc(id integer,maker text,name text,score integer,size real,memory integer,weight real,primary key(id))')
conn.rollback()
cur.close()
conn.close()また、テーブルの削除についても同様に次のように記述できます。
# data.db に作られた テーブル名 pc を削除するサンプル
import sqlite3
conn = sqlite3.connect("D:\data.db")
cur = conn.cursor()
cur.execute('drop table pc')
conn.rollback()
cur.close()
conn.close()もちろん、テーブル名を変更する ALTER TABLE 、Viewを作成する Create Viewについても同様に2通りの手順が使用できます。
テーブルの作成と削除の詳細については「【試して覚える】SQLite で テーブル作成(create table と drop table)」で解説していますので、併せてご覧下さい。
データの登録/変更/削除
テーブルに対してデータの登録/変更/削除を行う場合はトランザクションを使用します。
といっても、connect メソッドと同時にトランザクションが開始されているため、必要なSQLを実行し終えた段階で commit 又は rollback メソッドを呼び出すだけです。
言い換えると、commitを実行しないとデータの変更は行われません。
Insert
以下はインサートのサンプルです。
# pc という名前のテーブルにデータを追加するサンプル
import sqlite3
conn = sqlite3.connect("D:/data.db")
cur = conn.cursor()
cur.execute("insert into pc(id,maker,name,score,size,memory,weight) values(10000,'Dell','Inspiron 13 7000',6484,13.3,8,0.955)");
cur.execute("insert into pc(id,maker,name,score,size,memory,weight) values(10001,'Lenovo','ThinkPad X380 Yoga',6196,13.3,8,1.44)");
cur.execute("insert into pc(id,maker,name,score,size,memory,weight) values(10002,'マイクロソフト','Surface Laptop D9P-00039',3359,13.5,4,1.25)");
cur.execute("insert into pc(id,maker,name,score,size,memory,weight) values(10003,'富士通','FMV LIFEBOOK SH75/C3',6196,13.3,4,1.36)");
cur.execute("insert into pc(id,maker,name,score,size,memory,weight) values(10004,'Dynabook','dynabook GZ83/M',10326,13.3,16,0.859)");
conn.commit()
cur.close()
conn.close()Insert文に関する詳細は「【試して覚える】SQLite で Insert 文入門」で解説していますので、併せてご覧下さい。
delete
下記は削除のサンプルです。
# pc という名前のテーブルから idが10000のデータを削除するサンプル
import sqlite3
conn = sqlite3.connect("D:/data.db")
cur = conn.cursor()
cur.execute('delete from pc where id=10000')
conn.commit()
cur.close()
conn.close()delete文に関する詳細は「【試して覚える】SQLite で Delete 文入門」で解説していますので、併せてご覧下さい。
update
下記は更新のサンプルです。
# pc という名前のテーブルから maker が Dell のデータについて、score を 9999 に変更するサンプル
import sqlite3
conn = sqlite3.connect("D:/data.db")
cur = conn.cursor()
cur.execute("update pc set score=999 where maker='Dell'")
conn.commit()
cur.close()
conn.close()update文に関する詳細は「【試して覚える】SQLite で Update 文入門」で解説していますので、併せてご覧下さい。
データの検索と結果の取得(fetch~)
データを検索して結果を取り出したい場合、execute メソッドで select 文を実行し、fetch~メソッドで結果を受け取ります。
フェッチメソッドには3種類用意されており、それぞれ特徴があります。
| 用途 | メソッド | 解説 |
|---|---|---|
| 全件まとめて取得する時 | fetchall() | 検索結果の全件がリスト形式で返されます。 検索結果が多い場合、メモリ不足でエラーになる可能性 があります。 |
| 1件づつ取得したい時 | fatchone() | 呼び出すごとに検索結果を1行づつタプル形式で返します。 データが無くなればNone を返すので、ループ処理の中で 呼び出して使います。 |
| 指定した件数づつ取得したい時 | fetchmeny(件数) | 呼び出すごとに検索結果を指定した件数だけ取り出して、 リスト形式で返します。 データが無くなれば None を返すので、ループ処理の中で 呼び出して使うことになります。 |
fetchall
直前に実行した select 文の結果を、タプルを要素としたリスト形式(下記)で返します。
検索結果が少なければ問題ありませんが、大量の場合はメモリオーバーフローが起きる可能性があるので注意しましょう。

#fetchallのサンプル
import sqlite3
conn = sqlite3.connect("d:/data.db")
cur = conn.cursor()
cur.execute('select * from pc')
data = cur.fetchall()
cur.close()
conn.close()
print(data)fetchone
直前に実行した select 文の結果を、1行だけタプル形式で返します。
1件しか返さない select 文を実行し、その結果を受け取る場合に良く利用されますが、複数件を返すselect 文であっても、ループ処理の中で結果を順番に処理したい場合もよく利用されます。
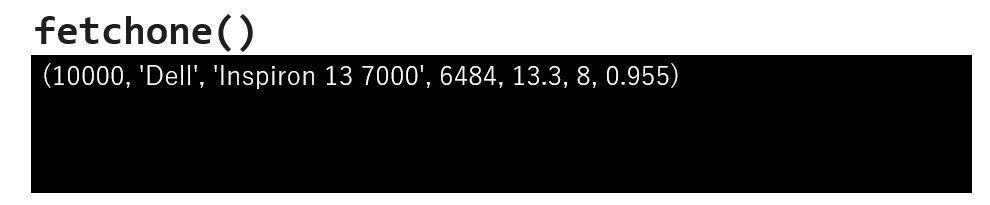
fetchone は取り出す結果が無くなると None を返しますので、これをループ処理の終了条件として利用します。
#fetchone のサンプル
import sqlite3
conn = sqlite3.connect("d:/data.db")
cur = conn.cursor()
cur.execute('select * from pc')
while(True):
row = cur.fetchone()
print(row)
if row == None:
break
cur.close()
conn.close()fetchmeny
直前に実行した select 文の結果を、引数で指定した件数づつ、タプルを要素としたリスト形式で返します。
例えば引数に2を指定すると次の様になります。

fetchmeny は取り出す結果が無くなると空のリスト [] を返すので、これをループ処理の終了条件として利用します。
#fetchmanyのサンプル
import sqlite3
conn = sqlite3.connect("d:/data.db")
cur = conn.cursor()
cur.execute('select * from pc')
while(True):
row = cur.fetchmany(2)
print(row)
if row == []:
break
cur.close()
conn.close()データの検索と結果の取得(カーソル)
cursorメソッドの戻り値として返される カーソル・オブジェクトを使う事でも、直前に実行した select文の結果を取得することが可能です。
カーソル・オブジェクトはイテレータであり、forループで使うことが出来るので、fetchone よりもスマートに記述することが可能です。
import sqlite3
conn = sqlite3.connect("d:/data.db")
cur = conn.cursor()
cur.execute('select * from pc')
for row in cur:
print(row)
cur.close()
conn.close()集計処理
select 文の中に計算式や集計関数を記述することで、任意の計算や集計が可能です。取り出し方は普通のselect文と同様に fetch~を使用します。
# メモリの平均と重量の合計を集計
import sqlite3
conn = sqlite3.connect("d:/data.db")
cur = conn.cursor()
cur.execute('select avg(memory),sum(weight) from pc')
data = cur.fetchall()
cur.close()
conn.close()
select count(*) from ~ の様に値が1つしか返さない場合であっても、戻り値のフォーマットは同じです。
集計関数の詳細については「【試して覚える】SQLite で Select 文入門(Groupと集計関数)」で詳しく解説していますので、併せてご覧下さい。
トランザクションモード
connect メソッドの isolation_level 引数に下記表の設定値を渡すことで、トランザクションにおけるロックの種類を指定することが出来ます。
sqlite3.connect(ファイル名,isolation_level=設定値)
| 分離レベル (isolation_level) | 設定値 | 内容 |
|---|---|---|
| deferred | 'DEFERRED' | 読み込み処理時にSHARED ROCKを、書き込み処理時にRESERVED ROCKを取得 |
| immediate | 'IMMEDIATE' | 開始時にRESERVED ROCKを取得 |
| exclusive | 'EXCLUSIVE' | 開始時にEXCLUSIVE ROCKを取得 |
| auto commit | None | トランザクションをしない。 言い換えると、SQLを1つ実行する度に commit する。 |
ロックに関する詳細については、SQLite公式サイトに記載されています(但し英語です)。
下記は公式サイトの内容を簡単に要約したものです。
| UNLOCKED | データベースにはロックが保持されておらず、データベースの読み取りも書き込みも不可。 初期値はこれ。 |
|---|---|
| SHARED | データベースは読み取り可能だが、、書き込みはできません。 任意の数のプロセスが同時にSHAREDロックを保持できるため、多数の同時リーダーが存在する可能性があります。 ただし、1つ以上のSHAREDロックがアクティブな間は、他のスレッドまたはプロセスがデータベースファイルに書き込むことはできません。 |
| RESERVED | データベースファイルへの書き込みを予定しているが、現在はファイルからの読み取りのみを行っている状態。 複数のSHAREDロックを1つのRESERVEDロックと共存させることはできるが、一度にアクティブにできるRESERVEDロックは1つだけ。 |
| PENDING | ロックを保持しているプロセスができるだけ早くデータベースに書き込みを行い、現在のすべてのSHAREDロックがクリアされるのを待ってEXCLUSIVEロックを取得できることを意味します。 |
| EXCLUSIVE | データベースファイルに書き込むには、EXCLUSIVEロックが必要。 ファイルには1つのEXCLUSIVEロックのみが許可されており、他のいかなる種類のロックもEXCLUSIVEロックと共存することはできない。 |
トランザクションの有無による速度比較
PythonのSQLite では、sqlite3.connect の引数になにも指定しない場合、トランザクションが自動的に実行されます。
isolation_level という引数を None にすることで、トランザクションを無効にすることが可能です。
そこで、トランザクションの有り無しでどれくらい差がでるのかを調べてみました。
ついでに、興味本位でコネクションのexecute と カーソルの execute についても速度の差があるか調べてみました。
結果は、コネクションのexecute を使った場合で242倍、カーソルのexecuteを使った場合で188倍もの差がありました。
以下は、1000件インサート時間(10回の平均値)の計測結果です。
| トランザクション無し | トランザクション有り | |
|---|---|---|
| コネクションのexecute | 37.17秒 | 0.153秒 |
| カーソルのexecute | 37.25秒 | 0.198秒 |
実験に使ったソースコードは次の通りです。
#コネクションの execute を使った場合の速度計測
import sqlite3
result = []
for cnt in range(10):
conn = sqlite3.connect("D:/data.db")
conn.execute("drop table pc")
conn.execute('create table pc(id integer,maker text,name text,score integer,size real,memory integer,weight real,primary key(id))')
conn.close()
conn = sqlite3.connect("D:/data.db")
### conn = sqlite3.connect("D:/data.db",isolation_level=None)
t1 = time.time()
for id in range(1000):
conn.execute("insert into pc(id,maker,name,score,size,memory,weight) values({0},'Dell','Inspiron 13 7000',6484,13.3,8,0.955)".format(id));
conn.commit()
conn.close()
t2 = time.time()
result.append(t2-t1)
print(result)
print(sum(result)/len(result))#カーソルの execute を使った場合の速度計測
import sqlite3
result = []
for cnt in range(10):
conn = sqlite3.connect("D:/data.db")
conn.execute("drop table pc")
conn.execute('create table pc(id integer,maker text,name text,score integer,size real,memory integer,weight real,primary key(id))')
conn.close()
conn = sqlite3.connect("D:/data.db")
### conn = sqlite3.connect("D:/data.db",isolation_level=None)
cur = conn.cursor()
t1 = time.time()
for id in range(1000):
cur.execute("insert into pc(id,maker,name,score,size,memory,weight) values({0},'Dell','Inspiron 13 7000',6484,13.3,8,0.955)".format(id));
conn.commit()
cur.close()
conn.close()
t2 = time.time()
result.append(t2-t1)
print(result)
print(sum(result)/len(result))まとめ
今回は、WindowsのPythonからSQLiteを使う方法について、SQLiteデータベースの作成、データの挿入/更新/削除、Fetchを使ったループ処理、トランザクション処理について解説しました。
そして、最後にSQLiteで1000件のデータをインサートする際の時間を、トランザクション有りと無しで計測、比較してみました。
SQLiteのインサート処理は、トランザクションをONにするのが定石ですが、実は240倍もの速度差があったんですね。
SQLiteは軽量で気軽に使えるデータベースなので、是非みなさんも活用してみてください。








コメント