みなさんがamazon で商品を購入する際、amazon の口コミを参考にすることが多いと思います。
でも、ページ送りで見ていくのって、結構面倒ですよね。
たくさん口コミがある人気商品だったら、なおさらです。
そこで、今回は amazon の口コミを自動で抽出するプチ便利ツールを作ってみましたので、プログラムの公開とソースコードの説明をしたいと思います。
ダウンロード
ツール(実行ファイル)のみと、プロジェクト一式(ソースコード一式)の2通りのダウンロードを用意しました。
ソースコード一式のダウンロードは、VIsual Stduio2019 でリビルドが可能なので、改造するなり中身を調べるなり好きなようにご活用下さい。
ツールのみダウンロード
理屈はどうでもいいので、とりあえず使ってみたいという方は、下記から実行ファイル(EXE)だけダウンロードできます。
ソースコード一式のダウンロード
機能を追加したい、不具合を見つけたので修正したいという方は、プロジェクト一式(ソースコード一式)を下記からダウンロードできます。
ツールの使い方
本プログラムを起動すると、次の画面が表示されます。
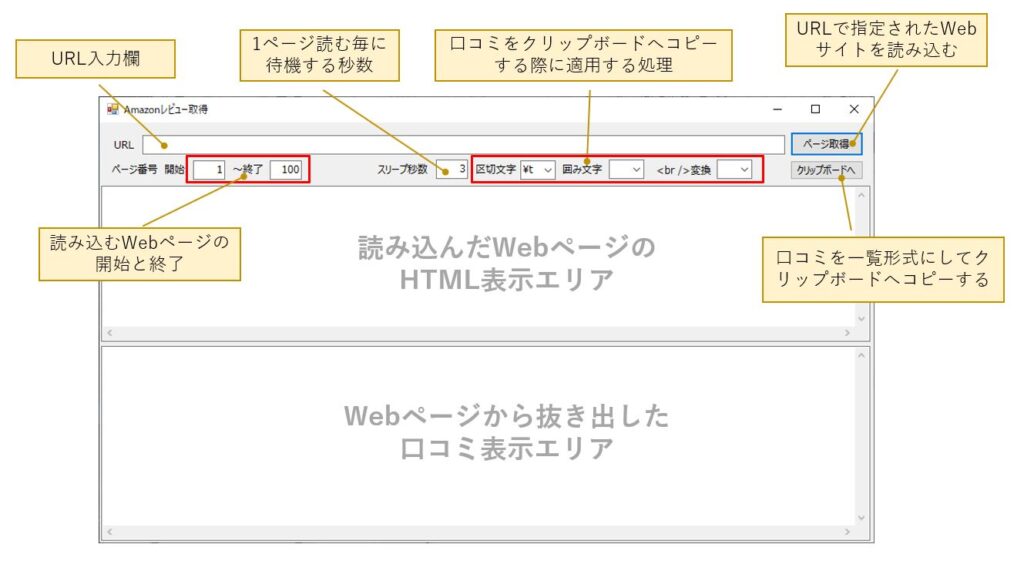
URLにAmazonの口コミページのURLを張り付け、ページ取得ボタンをクリックすると、画面の「HTML表示エリア」にWebページが読み込まれると同時に、「口コミ表示エリア」に評価、日付、口コミ等が表示されます。
| 項目名 | 用途・機能 |
|---|---|
| URL | 読み込みたいURLを入力 URLの数字部分に{0}を入力すると、ページ番号の開始~終了で指定した ページ番号に自動で置き換えてWebページを読み込む |
| ページ番号 開始~終了 | URLのページ番号の開始と終了を入力 |
| スリープ秒数 | 1ページ読む毎に待機する秒数を入力 |
| 区切り文字 | クリップボードへコピー時、各項目を区切る文字の指定 初期値はタブコード(\t) |
| 囲み文字 | クリップボードへコピー時、各項目の前後に付加する文字の指定 ダブルクォートで囲みたい場合などに使用 |
| <br />変換 | 口コミ本文に含まれる<br />タグを別の文字に置換したい場合に指定 初期値はタグを半角スペースに変換 \nを選択すると改行コードに変換される |
| HTML表示エリア | 読み込んだWebページのHTMLを表示する場所 |
| 口コミ表示エリア | HTMLから口コミを抜き出して表示する場所 |
| ページ取得 | URL欄に入力されたURLでWebページを読み込む |
| クリップボードへ | 口コミ一覧表示エリアの内容を、区切り文字、囲み文字、 <br />変換の指定内容に従って加工処理し、クリップボードへコピー |
amazon 口コミ(レビュー)のURLフォーマット
amazon の口コミ(レビュー)ページのURLは次の様な形式になっています。

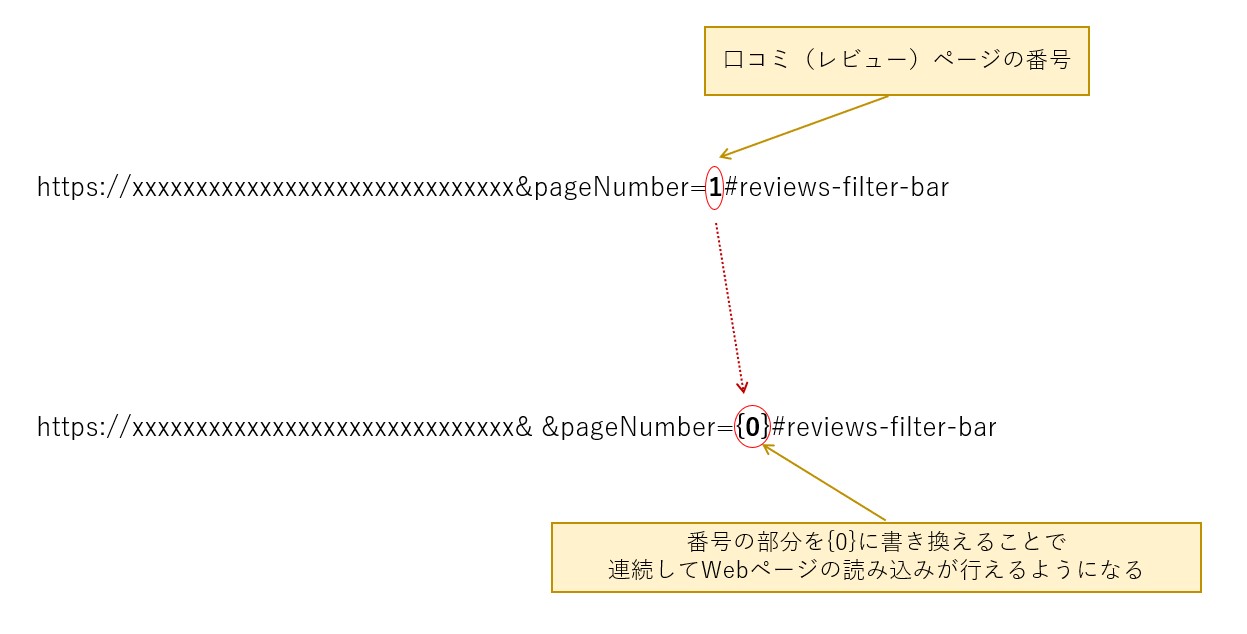
この番号がページ番号なので、この部分を{0} に変更することで、次々と口コミページを読み込むことが出来るようになります。

口コミ自動取得機能について
URLの数字部分を{0} に書き換えて「ページ取得」ボタンをクリックすると、「ページ番号開始~終了」で指定した範囲のページ番号を{0}に埋め込み、Webページを自動取得します。
口コミ最終ページの自動判定について
初期値は1~100になっているので1~100ページまで読み込むことになりますが、1ページ当たり10件の口コミが表示されるため、最大1000件の口コミを取得できることになります。
勿論、ページ番号を200とか300にすると読み込むページ数を増やすことが出来ますが、実際に1000件も口コミが書かれている商品はほとんど無いでしょう。
そこで、1ページ読み込む毎に、そのページが口コミの最終ページか否かを判断し、最終ページであれば強制的に読み込みが終了するようになっています。
具体的には、最終ページにだけ存在する特定のタグを見て最終ページを判断しているのですが、それがページの下の方に存在する「次へ」ボタンのタグになります。
class=\"a-disabled a-last\">次へ<スリープ秒数について
本プログラムは自動で連続的にWebページを読み込みますが、これが時には amazon への攻撃として受け止められる可能性を秘めています。
Webページを自動で読み込む「スクレイプ」という行為全般に言える事なのですが、短時間に特定のURLに対してアクセスすることは、接続先のWebサーバに対して負荷を掛けることになるため、貧弱なサーバだとダウンしてしまいます。
ずっと前に図書館サイトに対してこのような行為を行い、サーバがダウンして賠償問題に発展した事件がありました。
さすがにamazonではそのような事はありませんが、むしろ短期間で接続してくる相手に対しては攻撃と判定し、接続を拒否するような対策が講じられています。
こうなると、お使いのインターネット環境から amazon に対して一定時間接続できなくなります。
この対策の為にスリープ時間の入力欄を設けています。
スリープ時間は秒単位になっており、空白にするか数字に変換できない文字が入力されると1秒になるようになっています。
少なくとも0は入力せず、2~3秒あたりで利用して頂くのが安心かと思います。
クリップボードへコピーについて
「クリップボードへコピー」をクリックすると、口コミ表示エリアに表示されている内容がクリップボードにコピーされます。
この時、区切り文字、囲み文字、<br /> 変換 で指定された内容でデータを加工、一覧形式に変換した結果がクリップボードにコピーされます。
初期値は区切り文字をタブコードに、囲み文字は無し、<br /> は半角スペースに変換しますので、そのままEXCELに張り付ける事が可能です。
口コミの<br /> を改行コードに変換したい場合 \n を指定することで、改行コードに変換できます。
口コミURLの見つけ方と張り付け方
まず、口コミを取得したい商品ページを表示し、以下の操作を行ってください。
①商品の評価(5つ星)マークにマウスカーソルを当てます。

②下記の子ウィンドウが表示されるので、「星5つ」のリンクをクリックします。(実際は、この子ウィンドウに配置されているどのリンクをクリックしてもOKです)。

③商品のカスタマーレビューページに移動するので、少しスクロールして「並べ替え」と「フィルタ」のドロップダウンを探し、「星5つのみ」を「全ての星」に変更します。
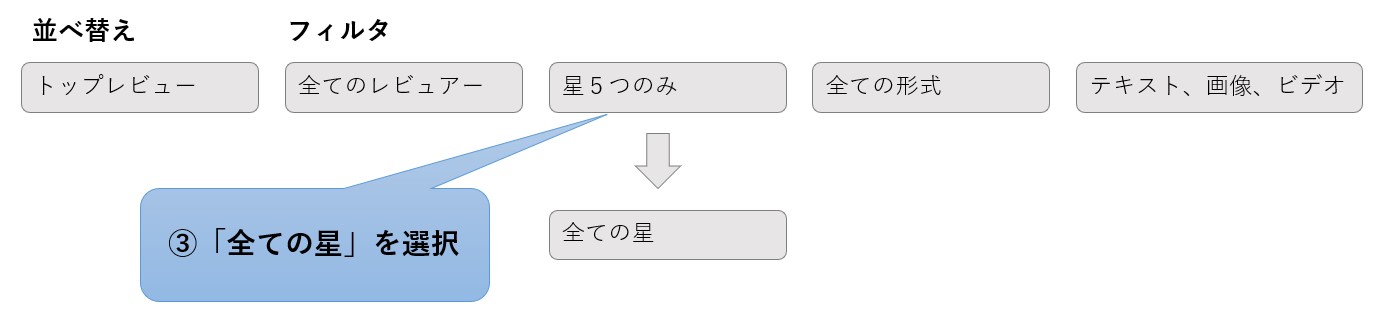
④ページをスクロールして、「次へ」のボタンがあるか探し、あれば「次へ」をクリックします。
すると、その商品のカスタマーレビューページに移動します。

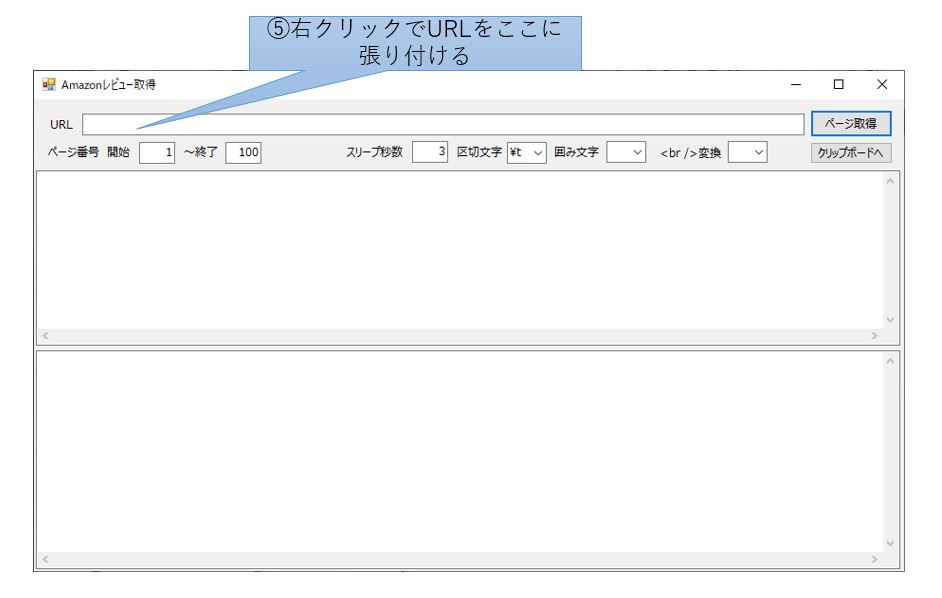
⑤ブラウザのアドレスバーに表示されているURLにマウスを当て、右クリックで内容をクリップボードにコピーします。

⑥最後に、本ツールのURL欄に右クリックで張り付けてください。
⑦最後に、URLの番号部分を{0} に書き換えて、「ページ取得」ボタンクリックすればOKです。
ソースコードの掲載
今回のプチツールのソースコードを掲載しておきます。
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using System.Net;
using System.Text.RegularExpressions;
using System.Threading;
namespace AmazonReviewScraper
{
public partial class MainForm : Form
{
public MainForm()
{
InitializeComponent();
}
/// <summary>
/// ページ取得ボタンクリック時のイベント処理
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void uxGetHtml_Click(object sender, EventArgs e)
{
//開始、終了のページ番号を取得
var start = (int.TryParse(uxStartPage.Text,out int val1)) ? val1 : 1;
var end = (int.TryParse(uxEndPage.Text, out int val2)) ? val2 : 1;
//開始~終了までループ
for (int i = start; i <= end; i++)
{
//urlの{0}にページ番号を張り付けてWebページを取得
uxDocument.Text = GetWebPage(string.Format(uxUrl.Text,i));
//Webページからレビュー記事を取得
List<string> lines = Extract(uxDocument.Text);
//下段の結果表示用TextBoxに表示
uxResult.AppendText(string.Join(Environment.NewLine,lines.ToArray()) + Environment.NewLine);
//OSに制御を移し、実行待ちのイベントを処理する
Application.DoEvents();
//特定キーワードがあれば最終ページと判断してループを抜ける
if(uxDocument.Text.Contains("class=\"a-disabled a-last\">次へ<"))
{
break;
}
//画面から入力された秒数だけ待機する
Thread.Sleep(((int.TryParse(uxSleep.Text, out int sleep)) ? sleep : 1) * 1000);
}
}
/// <summary>
/// 指定したURLからWebページを取得
/// </summary>
/// <param name="url"></param>
/// <returns></returns>
private string GetWebPage(string url)
{
//インスタンスの生成
WebClient wc = new WebClient();
//Webページの取得
byte[] data = wc.DownloadData(url);
//Webページの内容をUTF-8として文字列に変換
string html = Encoding.GetEncoding("UTF-8").GetString(data);
//CRをCRLFに変換した結果を戻り値として返す
return html.Replace("\n", Environment.NewLine);
}
/// <summary>
/// Webページの中身からレビュー記事部分を抜き出す
/// </summary>
/// <param name="html"></param>
/// <returns></returns>
public List<string> Extract(string html)
{
//HTMLを改行コードで分割
string[] lines = html.Split(new string[] { Environment.NewLine }, StringSplitOptions.None);
//抽出の開始/終了を制御するフラグ
bool enable = false;
//抽出結果格納用List
List<string> result = new List<string>();
foreach (string line in lines)
{
//抽出を開始するキーワード
if (line.Contains("data-hook=\"review\""))
{
enable = true;
}
//抽出を終了するキーワード
if (line.Contains("人のお客様がこれが役に立ったと考えています</span>"))
{
enable = false;
}
//抽出処理
if (enable)
{
addtext(result, line, " <span>", "</span>"); //タイトルの取得
addtext(result, line, "<span class=\"a-icon-alt\">", "</span>"); //評価(星)の取得
addtext(result, line, ";formatType=current_format\">サイズ:", "<i"); //サイズの取得
addtext(result, line, "class=\"a-size-base a-color-secondary review-date\">", "</span>"); //レビュー記事の取得
addtext(result, line, " <span class=\"cr-original-review-content\">", "</span>"); // 英語レビュー記事
}
}
return result;
//指定したキーワード~キーワードの間の文字列をListに追加するローカル関数
void addtext(List<string> p_list,string p_line,string p_start,string p_end)
{
int pos = p_line.IndexOf(p_start);
if (pos >= 0)
{
pos += p_start.Length;
int idx = p_line.IndexOf(p_end, pos);
int len = (idx < 0) ? p_line.Length : idx;
p_list.Add(p_line.Substring(pos, len - pos));
}
}
}
/// <summary>
/// クリップボードへコピー処理
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void uxCopyToClipboard_Click(object sender, EventArgs e)
{
//CSV分割文字の取得
string split = uxSplitChar.Text.Replace("\\t", "\t");
//BR置換文字の取得
string br = uxBrReplace.Text.Replace("\\n", Environment.NewLine);
//行データ保存用Listの作成
List<string> rows = new List<string>();
//列データ保存用Listの作成
List<string> columns = new List<string>();
//抽出結果の行数でループ
foreach (string line in uxResult.Lines)
{
if (line.StartsWith("5つ星のうち"))
{
//列データが0より大きい場合
if (columns.Count > 0)
{
//列データを行データ保存用ワークに登録
rows.Add(string.Join(split, columns.ToArray()));
}
//
columns.Clear();
}
//列データに登録
columns.Add(uxEncloseChar.Text + line.Replace("<br />", br) + uxEncloseChar.Text);
}
//行データ保存用ワークに未登録の列データがあるか確認
if (columns.Count > 0)
{
//列データを行データ保存用ワークに登録
rows.Add(string.Join(split, columns.ToArray()));
}
//クリップボードへコピー
Clipboard.SetText(string.Join(Environment.NewLine, rows));
}
}
}
uxGetHtml_Click イベント
ページ取得ボタンをクリックした時に発生するイベントです。
WebページからHTMLを取得してはスリープ秒数分だけ待機するという処理を、画面で指定された開始~終了まで繰り返しています。
また、この中で "class=\"a-disabled a-last\">次へ<" がHTMLに含まれているかを判断し、含まれていれば最終ページと判断してループを抜けています。
GetWebPageメソッド
このメソッドは引数に指定されたURLのWebページからHTMLを取得して、文字列として返すメソッドです。
WebClient クラスの DownloadData メソッドを呼ぶことで該当URLのHTMLが取得できます。
このメソッドは byte配列で結果を返すため、Encoding.GetEncoding("UTF-8").GetString(data) にてUTF-8の文字列に変換しています。
なぜ UTF-8 に変換しているかというと、amazon のサイトの文字列が UTF-8 であるためです。
ここは対象となるWebサイトの文字コードに合わせる必要があります。
Extractメソッド
このメソッドは文字列として得られたHTMLの中から、特定のキーワードが含まれる部分を抜き出すものです。
得られたHTMLにはJavascriptなどが大量に含まれているので、口コミが含まれているであろう箇所まで読み飛ばすようにしています。
HTMLを調べたところ、”data-hook=\"review\"" が見つかるまでは完全に無視しています。
そして、見つかった時点で抽出処理を開始し、 "人のお客様がこれが役に立ったと考えています" という文字列が見つかった時点で、口コミの終わりだという判定をして抽出処理を止めています。
抽出処理を開始してから終了するまでの間は addtext というローカル関数を呼び出していますが、これは取り出したい文字列(抽出部分)が含まれているかを判定し、あれば抜き出すというローカル関数です。
//抽出処理
if (enable)
{
addtext(result, line, " <span>", "</span>"); //タイトルの取得
addtext(result, line, "<span class=\"a-icon-alt\">", "</span>"); //評価(星)の取得
addtext(result, line, ";formatType=current_format\">サイズ:", "<i"); //サイズの取得
addtext(result, line, "class=\"a-size-base a-color-secondary review-date\">", "</span>"); //レビュー記事の取得
addtext(result, line, " <span class=\"cr-original-review-content\">", "</span>"); // 英語レビュー記事
}ここでは、タイトル、評価、口コミ(レビュー)記事、サイズを抜き出したいので、addtext を使って抜き出すようにしています。
ちなみに、サイズという項目名は商品によって存在しない場合もあり、あったとしてもサイズではなく、全く別の意味(例えば MK1やMK2 など製品の派生を表すもの)で使われている場合もあります。
addtext ローカル関数
Extractメソッドの中に記述している addtextローカル関数は4つの引数を持っています。
| List<string> p_list | 抽出部分の文字列を格納(追加)するList変数 |
| string p_line | 抽出部分が含まれている可能性がある文字列 |
| string p_start | 抽出部分の始まりを示すキーワード |
| string p_end | 抽出部分の終わりを示すキーワード |
void addtext(List<string> p_list,string p_line,string p_start,string p_end)
{
int pos = p_line.IndexOf(p_start);
if (pos >= 0)
{
pos += p_start.Length;
int idx = p_line.IndexOf(p_end, pos);
int len = (idx < 0) ? p_line.Length : idx;
p_list.Add(p_line.Substring(pos, len - pos));
}
}やっている事は単純で、p_line に対してp_start で指定されたキーワード(文字列)の開始位置を探し、あれば p_end で指定されたキーワードが見つかるまでの部分を抜き出し、p_list に追加するというものです。
Webページから取得したHTMLの中から、評価(星の数)、日付、口コミなどの必要情報を取り出す方法として、正規表現という方法がよく使われます。
これは、()*.?[] などの文字を使って文字が出現するパターンを指定し、そのパターンと一致する部分を取り出したり、別の文字列に変換するという方法です。
しかし、この手段を使う際に必要な出現パターンの記述がけっこう複雑であることから、今回はプログラムのロジックで文字列の部分取り出しを行う事にしました。
クリップボードへコピー処理
uxResult.Text には下図のような順番で口コミが追加されています。
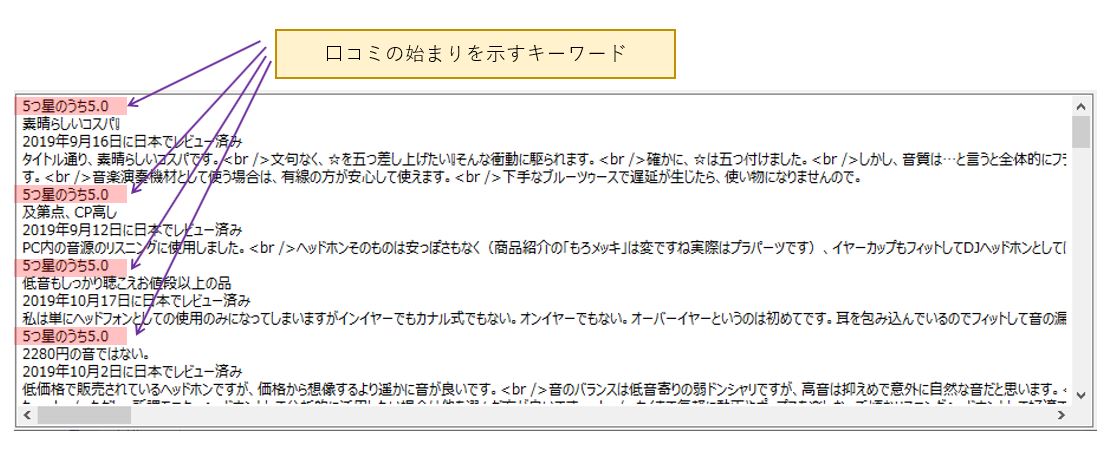
口コミ1件につき、「5つ星のうち~」「タイトル」「口コミの日付」「口コミの本文」という構成になっていますので、”5つ星のうち” というキーワードが行の先頭にあれば、口コミの開始と判断し、次の "5つ星のうち" が見つかるまで、columns 変数に追加していきます。
そして、次の "5つ星のうち" が見つかった時点で、それまでに columns変数に追加した内容を 一旦string[] に変換し、 string.Joinメソッドを使って1つの文字列に結合し、更に rows 変数に追加しています。
この処理を全ての口コミが取得できるまで繰り返し、最後に クリップボードにコピーしています。
まとめ
いかがでしたでしょうか。
今回は amazon の口コミのURLを使って全ての口コミを取り出し、クリップボードにコピーする簡易ツールについて、プログラムの共有とソースコードの説明をしました。
amazon のHTMLの仕様が変わったり、想定していないHTMLが来た場合、うまく口コミが取得できなくなりますので、その時は今回の説明内容を参考に修正してみて下さい。








コメント