今回は、回帰や分類などの機械学習モデルを簡単に作成できるPythonのパッケージ「Pycaret」について、Windowsで使うためのインストール方法と基本的な使い方を、分かりやすく解説します。
Pythonで機械学習といえば scikit-learn が定番ですが、Pycaret はより簡単に複数のアルゴリズムを比較し、精度が最も高いものを探してくれますし、最適なハイパーパラメータ値の探索も1行で書けてしまう優れものです。
入門用の記事は数多く見受けられますが、本記事は実用性を重視した内容となっています。
これから使おうとされている方は是非ご一読ください。
Pycaretとは
Pycaret は 、機械学習の一連の作業を自動化してくれるオープンソースの機械学習パッケージです。
同様の製品として、Microsoft社 の Azure AutoML 、Googleの Cloud auto ML、DataRobot社 DataRobot が有名ですが、いずれも高額な利用料が必要が発生することから、気軽に使うことができません。
Pycaretは、これら有料製品に比べてサポートされているアルゴリズムの数や操作性は見劣りするものの、メジャーなアルゴリズムはサポートされていることや、パソコンと電気代以外の用が掛からないということから、Pythonとscikit-learnでモデルを作成する人にとっては、非常に利用価値の高いパッケージです。
特に機械学習をこれから始めようとする方には最適ではないかと思います。
Pycaretの概要
まず全体を理解して頂くために、「出来る事」を簡単な図にまとめてみました。図から分かるように、Pycaretは大きく3つの機能を持っています。
- 複数モデルの比較:
教師データを使って複数モデルの作成&精度比較を行い、最も成績が良かったモデルを選んでくれます。 - モデルの作成:
指定したアルゴリズムでモデルを作成し、そのモデルに対してハイパーパラメータのチューニングや、予測結果のグラフ化を行うことが出来ます。 - モデルの適用:
予測させたいデータを渡すと、作成したモデルを使って実際に予測を行ってくれます。
チュートリアルやメソッドの使い方などは公式ページに記載されていますので、本記事をご一読し頂いてから公式ページを見ていただくと、より分かりやすいかと思います。
Pycaretで最初に知っておくべきこと(制約条件など)
Pycaret を使う場合は、PythonのバージョンやOSに制限があるので注意しましょう。2024年9月現在においては次の制限があります。
- OSは 64-bit systems であること
- Python 3.8~3.11 であること
- Ubuntu は 16.04 以降であること
- Windows 7 以降であること
- Pythonの pip でインストールすること(Conda install は不可)
制約条件ではありませんが、各メソッドを Jupyter Notebook で動作させる場合とPythonコンソール(もしくはVisual Studio Codeなどの統合開発環境)で動作させる場合では挙動が異なります。
例えば、Jupyter Notebook ではマウスで描画するグラフが選択できますが、Pythonコンソールだとグラフそのものが表示されません。
本記事では Jupyter Notebook の画面キャプチャを使用していますのでご注意ください。
Pycaretのインストール方法
あらかじめ、インストールされているPython のバージョンが3.8、3.9、3.10、 3.11 のいづれかであることを確認してください。
もしPycaret がサポートしていないPython のバージョンである場合は、python の仮想環境を作って、そこにインストールして下さい。
インストール方法は他のパッケージと同様で、Pythonコンソールを管理者モードで起動した後に、pip コマンドでインストールします。
尚、 Pycaretをインストールすれば、自動的に pandas や numpy 等の必要パッケージもインストールされます。
pip install pycaret
Python のインストール状態によってはエラーが発生する場合があります。
私の場合は以下のコマンドを実行することでインストール出来ました。
pip install --upgrade pip --user
pip install pycaret --user
ちなみに、conda install でもインストールすると、一見インストールされたように見えますが、Pycaret実行時にエラーになります。
Pycaretインストール時に自動でインストールされる pandas や numpy は最新のバージョンがインストールされるので、都合が悪い場合は個別にバージョンを指定してインストールし直して下しさい。
Pycaretを使うための準備
Pycaret を使うタイミングは、大きく分けて「新しくモデルを作成する時」と、モデルを使って「新しいデータで予測したい時」の2通りです。
この章では、この2つについてサンプルコードを交えて解説したいと思いますが、その前に以下の3点につれて触れておきたいと思います。
- pycaret のインポート
- 説明に用いるサンプルデータ
- 前処理
Pycaret のインポート
必要最小限として、pandas と Pycaret のインポートが必要です。
Pycaret は、分類や回帰などの用途によってインポート対象のモジュールが異なります。
下記は回帰のインポートサンプルとなります。
import pandas as pd
from pycaret.regression import *回帰以外にも以下のものが用意されていますので、用途に応じてインポートして下さい。
| 用途 | モジュール名 |
|---|---|
| 分類 | pycaret.classification |
| 回帰 | pycaret.regression |
| 時系列予測 | pycaret.time_series |
| クラスタリング | pycaret.clustering |
| 異常検出 | pycaret.anomaly |
Pycaet 2.0 では、自然言語処理とアソシエーション分析がサポートされていましたが、Pycaret 3.0からはサポート外となっています。これらのアルゴリズムを使いたい場合は、Pycaret 2.0 をご検討ください。
説明に用いるサンプルデータ
Pycaret にはチュートリアル用のテストデータ が含まれています。
今回は、その中にあるボストンの不動産価格のデータ 'boston' を使って回帰モデルを作成します。
何を予測するかは趣味の世界なのですが、ここでは定番として犯罪発生率 'crim' を目的変数(ターゲット)にしたいと思います。
| カラム名 | 内容・意味 | データの型 |
|---|---|---|
| crim | 犯罪発生率 | float64 |
| zn | 25,000 平方フィート(約2.3 Km2)以上の住宅区画比率 | float64 |
| indus | 小売以外の商業が占める土地面積比率 | float64 |
| chas | チャールズ川沿いか否かを示すダミー変数 (1: 川沿い、 0: それ以外) | int64 |
| nox | 窒素酸化物の濃度(pphm単位) | float64 |
| rm | 1戸当たりの平均部屋数 | float64 |
| age | 1940年より前に建てられた物件比率 | float64 |
| dis | ボストンにある5つの雇用施設までの距離(重み付き) | float64 |
| rad | 環状高速道路へのアクセス指数 | int64 |
| tax | 10,000ドルあたりの固定資産税比率 | int64 |
| ptratio | 町ごとの生徒と教師比率 | float64 |
| black | 町ごとの黒人比率 | float64 |
| lstat | 低所得者比率(%) | float64 |
| medv | 住宅価格の中央値(単位:1000ドル) | float64 |
前処理
今回は Pycaret が用意しているデータを使いますが、通常はCSVファイルで用意されているケースが大半だと思います。
この場合、データの型が意図した通りになっていない(例えば1か0のフラグが含まれるカラムを、整数と判断するなど)こともあるため、Pycaret に正しい型を教えてあげる必要が生じます。
また、データにはNaN などの欠損値や異常値が含まれていることも多く、これらを補間するなり排除するなり、いわゆるクレンジング処理が必要になります。
setup メソッドは、Pycaret に対して学習データや目的変数、説明変数を指示するためのメソッドなのですが、同時に各カラムの型判定と欠損データ等のクレンジングも行ってくれます。
setup メソッドには様々な引数が指定できますが、最低限データと目的変数を指定するだけOKです。
setup(data = データ名,target='目的変数のカラム名')
ちなみに、setupメソッドを実行すると自動判定した結果が表示され、入力待ち状態になりますので、特に問題が無ければ、エンターキーを入力してください。
エンターキーを押さないと、いつまでもこの状態から先に進まないので注意ください。
もし、除外したい説明変数がある場合、ignore_features引数にリスト形式で指定します。
#データの読み込み
boston = get_data('boston')
#前処理の実行
setup(data=boston,target='crim',ignore_features=['zn','indus'])新しくモデルを作成する
新しくモデルを作成する場合は、Pycaretを使ってゼロから最適なアルゴリズムを探索してモデルを作る場合と、任意のアルゴリズム名(例えば lightGBM、Gradient Boosting Regressor など)を指定してモデルを作成する場合の2通りがあります。
下記は、この2通りについて、メソッドの呼び出し手順を図で表したものになります。
最適なモデルを探したい場合
では、実施に最適なモデルを探してハイパーパラメータのチューニングを行い、モデルファイルとしてファイル出力するまでの一連の流れについて、サンプルソースコードを紹介します。
#サンプルデータの読み込み
from pycaret.datasets import get_data
boston = get_data('boston')
#モデル探索に必要なパッケージのインポート
import pandas as pd
from pycaret.regression import *
#前処理を行う(データの指定と目的変数(=ターゲット) のカラム名を指定)
setup(data=boston,target='crim')
#複数のモデルを試し、成績が一番良いモデルを取得
model = compare_models()
#取得したモデルに対してハイパーパラメータを自動探索
tuned_model = tune_model(model)
#ハイパーパラメータ調整後のモデルに対して、精度を把握するためのグラフを表示
evaluate_model(tuned_model)
#与えられた全ての教師データを使ってモデルを最終版の作成
final_model = finalize_model
#出来上がった最終版のモデルをファイルに書き出す
save_model(final_model,'p:/finalmodel')compare_model を実行すると、以下の通り複数のモデルが生成/比較され、jupyter notebook 上に表示されます。
ちなみに、比較するモデルの候補を指定することも可能で、この場合は include 引数にリスト形式で列記します。
model = compare_models(include=['rf','en','br'])モデルの比較が終了すると、MAE,MSE,RMSE などの精度評価指標が表示され、最も成績が良かった値が黄色で塗りつぶされます。
この時、compare_modelsメソッドの戻り値として最も成績が良かったモデルが返ってきますので、その中身をprint で見ることが可能です。
LGBMRegressor(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.1, max_depth=-1,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=100, n_jobs=-1, num_leaves=31, objective=None,
random_state=3903, reg_alpha=0.0, reg_lambda=0.0, silent='warn',
subsample=1.0, subsample_for_bin=200000, subsample_freq=0)戻り値として返されたモデルに対して tume_model メソッドを実行することにより、ハイパーパラメータの探索を行うことが出来ます。
そして、その結果を evaluate_model メソッドに渡すことで、精度評価や重要度などの情報を可視化/一覧表示することができます。
PlotTypeのグレー部分(Hyperparameters,Residuals,Prediction Error、・・・)をクリックすることにより、任意の情報を切り替えて表示できます。
finalize_model メソッドはモデル作成の最終作業で、探索したハイパーパラメータをもとに全データを使ってモデルを再構築し、その結果を返します。
以上で、最適なアルゴリズムと、チューニングされたハイパーパラメータを持つモデルの完成です。
最後に save_model でモデルをファイルに書き込んでいますが、単にハイパーパラメータの値が知りたいだけであれば、特にモデルを保存する必要はありません。
尚、保存されたモデルファイルは '.pkl' という拡張子が自動で付与されます。
既にモデルが決まっている場合
例えば、lightbgm を決め打ちでモデルを作りたい場合(アルゴリズムが決まっている場合、或いは既存モデルのハイパーパラメータの最適値を探索したい場合)は、compate_model の代わりに create_model を使います。
#サンプルデータの読み込み
from pycaret.datasets import get_data
boston = get_data('boston')
#モデル探索に必要なパッケージのインポート
import pandas as pd
from pycaret.regression import *
#前処理を行う(データの指定と目的変数(=ターゲット) のカラム名を指定)
setup(data=boston,target='crim')
#★★★ アルゴリズムを指定してモデルを作成
model = create_model('lightgbm')
#取得したモデルに対してハイパーパラメータを自動探索
tuned_model = tune_model(model)
#ハイパーパラメータ調整後のモデルに対して、精度を把握するためのグラフを表示
evaluate_model(tuned_model)
#与えられた全ての教師データを使ってモデルを最終版の作成
final_model = finalize_model
#出来上がった最終版のモデルをPドライブのルートにファイルとして書き出す
save_model(final_model,'p:/finalmodel')create_model の引数として使えるアルゴリズムは回帰、分類など目的により変わりますが、例えば、xgboost のモデルを作成したい場合、 create_model('xgboost')と記述します。
実際に使えるアルゴリズムは公式サイトに詳しく記載されていますので、そちらをご覧ください。
| 用途 | 英語名称 | ドキュメントのURL |
|---|---|---|
| 分類 | Classification | Classification — pycaret 2.3.5 documentation |
| 回帰 | Regression | Regression — pycaret 2.3.5 documentation |
| クラスタリング | Clustering | Clustering — pycaret 2.3.5 documentation |
| 異常検出 | Anomaly Detection | Anomaly Detection — pycaret 2.3.5 documentation |
| 自然言語処理 | NLP | NLP — pycaret 2.3.5 documentation |
| アソシエーション分析 | Association Rules | Association Rules — pycaret 2.3.5 documentation |
新しいデータで予測する
予測する方法は、予測したいデータとsave_model で保存したモデルファイルを読み込み、 predict_model メソッドを実行するだけです。
#サンプルデータの読み込み
from pycaret.datasets import get_data
input_data = get_data('boston')
#必要なパッケージのインポート
import pandas as pd
from pycaret.regression import *
#Pドライブのルートに置かれた finalmodel.pkl というモデルファイルを読み込む
final_model = load_model('p:/finalmodel')
#モデルにデータを渡して予測結果を取得
result = predict_model(final_model ,data = input_data )
#予測結果をPドライブにCSV出力
result.to_csv('p:/result.csv',index=None)predict_modelメソッドで予測した結果は、末尾にLabelというカラムが追加され、そこに予測結果が格納されます。
尚、predict_model メソッドの戻り値はDataFrame形式なので、pandas のto_csv メソッドでそのままファイルに書き出すことが可能です。
ちなみに、load_model で指定するモデルファイルに拡張子を指定するとエラーになるため注意が必要です。
例えば'mymodel.pkl' という風に拡張子を指定すると、’mymodel.pkl.pkl' と指定されたこととなり、ファイルが見つからないというエラーが発生します。
compare_models や create_model がちゃんと動作しない時
compare_model は動いているみたいだけど結果が出ない場合、或いは Create_model で エラーが発生して終了してしまう場合があります。
例えば、compare_model を実行したら、プログレスーバーは進むのにモデルが表示されないとか。
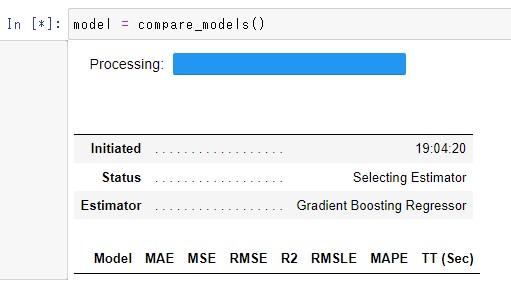
例えば、create_model を実行したら、エラーが表示されて止まってしまうとか。
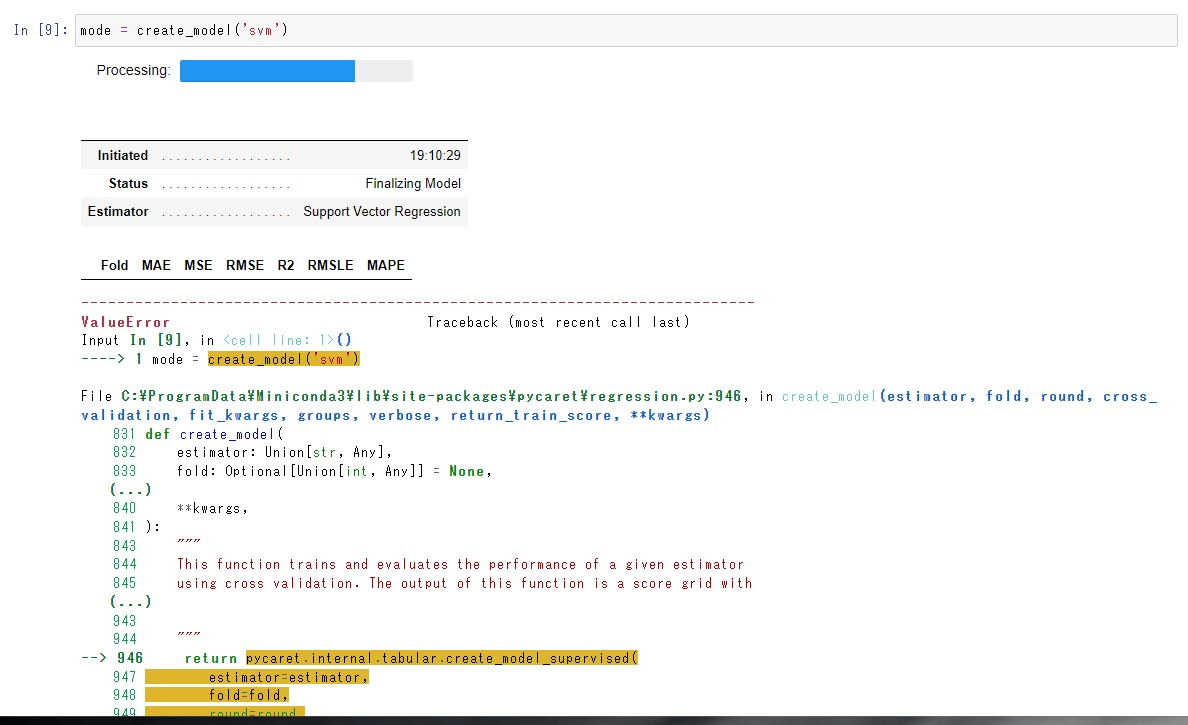
そんな時は、投入したデータを疑ってみましょう。
ついつい見落としがちなのですが、setupメソッド実行時、MissingValuesがTrueになっていると、何所かしらに変なデータが含まれています。
たとえば、浮動小数点の列に文字列が含まれている場合とかです。
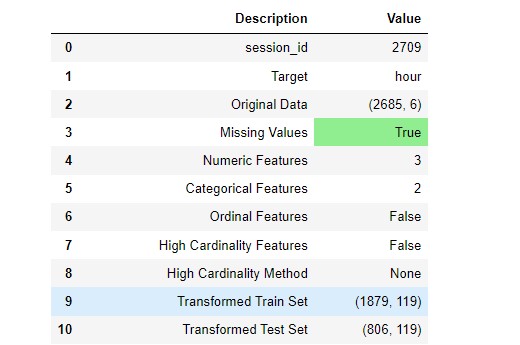
setup メソッドで上記の様に異常な値(Missing Value)が含まれていることを教えてはくれますが、エラーにはならずそのまま正常終了します。
これに気づかず compare_models や create_model を実行してしまうと、今回のような現象に見舞われます。
Missing Values は常にチェックするようにして、 Trueの場合は何らかの対応をしましょう。
Pycaret で扱えるデータ量について
compare_models() で複数のモデルを比較する場合、数千~数万件程度のCSVであれば全く問題はありません。
当然マシンスペックにもよりますが、第7世代のCore-i5と8GBメモリでも問題無く処理できます。
しかし、 kaggle で公開されている18GB程度のCSVデータ(約300万件×約300カラム)で試したところ、9世代のCore-i5 、メモリ64GBのPCでさえ、CPUは100%に張り付き、メモリ64GBを使い切ってしまいました。
3日程度放置しましたが、サポートされている16アルゴリズム(回帰の場合)の7番目から先へ進まず、そのPCへのログインすらできなくなりました。
大量のデータに対して compare_models() を実行する場合は、CPUとメモリが枯渇してフリーズ状態になりますのでご注意ください。
ちなみに、CPUスペックを上げるとCPUの使用率は50%~60%に落ち着きますが、メモリは相変わらず64GBを使い切ってしまったので、どちらかというとメモリ量を気にした方が良いかもしれません。
では、CPUやメモリ量がそれほど多くないPCで、大量データに対して compare_models() を実行したい場合はどのような対策があるでしょうか。
データを間引いて投入する方法はありますが、それは別としてモデルを限定するという方法が使えます。
下記の様に include オプションに続けてリスト形式で指定すれば、そんなにメモリを消費しないようです。
model = compare_models(include = ['lr', 'dt', 'lightgbm'])タスクマネージャを確認すると同時に5~6個のPython.exe が事項され、それぞれが結構多くのメモリを消費していました。おそらく複数モデルを並列処理しているのでしょう。
もう1つ、budget_time オプションを指定することで、指定時間(単位:分)が経過すると強制終了させることが可能です。
#100分で処理を強制終了
modeo = compare_models(budget_time = 100)この場合は、指定時間が経過すると compare_models() を強制的に中断してしまうため、全てのモデルを比較することは出来ません。
全てのアルゴリズムは試せなくても、とりあえず出来るところまでの結果が欲しいという場合に使うのがベストです。
まとめ
今回は、たった数行のソースコードを書くだけで、メジャーなアルゴリズムから総当たりでモデルを作成、その中から最も成績の良いモデルを選定してくれ、おまけにハイパーパラメータのチューニングまでやってくれる超便利なパッケージ「Pycaret 」について、インストールの方法から実際の使い方まで、図を交えて解説しました。
Pycaret を使わなくても同じことをは出来ますが、いくつものパッケージを組み合わせたり、自力で沢山のコードを各必要があるため、かなり面倒で敷居が高い作業になります。
Pycaret を知ってから、今までの作業は何だったんだと思うほど、モデル作成作業が簡略化されました。
予測モデル作成~新規データに対する予測の実行までをPycaret で行うこと以外に、既にscikit-learnで作った予測プログラムがあって、ハイパーパラメータだけを最適化したいという使い方も可能です。
もし機械学習を使ってモデルを作成することがあれば、是非 Pycaret をご検討下さい。
この記事が皆様のプログラミングの参考になれば幸いです。








コメント