2022年11月に登場したChatGPTにより脚光を浴びた「大規模言語モデル」。その後2023年2月にBing AIが、5月にGoogle Bardが続きますが、それ以外にも数多くの「大規模言語モデル」が登場しており、様々なシーンで活用され始めています。
ただいずれの場合も巨大なモデルであることから、気軽に個人のPCにインストールして使うということは、これまで出来ませんでした。
しかし、2023年5月に登場した rinnna は、大規模言語モデルの中では小さくまとまっており、中級ゲーミングPCのスペックがあれば、インストールして使うことができます。
今回は、この rinna についてどのようなものか、ChatGPTをはじめとする大規模言語モデルと何が違うのか、そしてPCへのインストールと使い方について紹介したいと思います。
rinnaとは

rinnaは、rinna株式会社が開発した日本語に特化した大規模言語モデルです。2023年5月に公開され、「汎用言語モデル」と「対話言語モデル」の2種類がオープンソースとして公開されています。
rinnaは、36億パラメータを持つGPT言語モデルであり、テキストとコードの膨大なデータセットでトレーニングされていることから、テキストの生成、言語の翻訳、さまざまな種類のクリエイティブ コンテンツの作成、有益な方法で質問に答えることが可能です。
ところで皆さんは、2015年8月にLINEで公開された女子高生AI「りんな」をご存じでしょうか。マイクロソフトの開発部門であるAI&リサーチが開発した「共感をテーマに、AIと人の間に感情のつながりを築くことを目的」としたプロジェクトなのですが、2020年8月に独立し、「りんな」を含むマイクロソフトのチャットボットAI事業を引き継いだのがrinna株式会社 です。
rinnaの特徴

rinnaの特徴は、次のとおりです。
- 日本語に特化しているため、日本語の文章をより自然に生成することが可能
- 人間の評価を利用したGPT言語モデルの強化学習(Chat GPTと同じ手法)により、性能が向上
- オープンソースで提供されているため、無料で利用が可能
- PCに直接インストールして使うことが可能
rinnaは、日本語に特化した大規模言語モデルとして、チャットボットや音声認識システム、翻訳システムなどの開発や、教育や研究などの分野で利用されています。
他の大規模言語モデルとの比較

rinna、ChatGPT、Bing AI、Google Bardは、いずれも大規模言語モデルであり、テキストの生成、言語の翻訳、さまざまな種類のクリエイティブ コンテンツの作成、有益な方法で質問に答えることができる点は共通です。
ただし、rinna のパラメータ数は他の大規模言語モデルに比べてかなり少なく36億個しかないため、一般的な会話では噛み合わないことも多く、会話の受け答えや解答の質に関しては遠く及びません。特にプログラムコードの生成は不可能なので、過度の期待は禁物です。
| 項目 | rinna | ChatGPT | Bing AI | Google Bard |
|---|---|---|---|---|
| 開発元 | 株式会社rinna | OpenAI | Microsoft | |
| 言語 | 日本語 | 英語 | 英語 | 英語 |
| パラメータ数 | 36億 | 1750憶 | 非公開 | 5400億 |
| データセット | 日本語のテキストとコード | 英語のテキストとコード | 英語のテキストとコード | 英語のテキストとコード |
| 機能 | テキストの生成、言語の翻訳、さまざまな種類のクリエイティブ コンテンツの作成、有益な方法で質問に答える | テキストの生成、言語の翻訳、さまざまな種類のクリエイティブ コンテンツの作成、有益な方法で質問に答える | テキストの生成、言語の翻訳、さまざまな種類のクリエイティブ コンテンツの作成、有益な方法で質問に答える | テキストの生成、言語の翻訳、さまざまな種類のクリエイティブ コンテンツの作成、有益な方法で質問に答える |
| オープンソース | あり | なし | なし | なし |
rinnaの用途

ローカルな環境で利用できることから、社内向けのチャットボットを構築したり、翻訳や文書要約などの機能を既存のシステムに組み込むことが考えられます。
OpenAIやBingAIのように、API単位で課金されることもなく、ローカルがゆえに機密情報が外部に記録される心配もないため、活用範囲は幅広いでしょう。
インストール方法

Pythonがインストールされている必要があります。まだの方は「【初心者必見】Pythonインストールはどれを選べばいい?(Windows)」の記事を参考にインストールして下しさい。
Pythonの環境で以下のコマンドを実行します。私は Python 3.10.9 で以下のコマンドを実行しています。
python.exe -m pip install --upgrade pip
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Pip install transformers sentencepieceモデルはPythonプログラムを実行すると自動でダウンロードされるため、事前にダウンロードしておく必要はありません。
尚、回答速度は遅いですが、GPUが無くても動作は可能です。Corei-5 13400 で今回のデモを動かした場合、簡単な質問への解答に約1分程度掛かりました。
使い方

以下の公式サイトに「汎用言語モデル」と「対話言語モデル」のサンプルプログラムが掲載されています。本記事では、「対話言語モデル」のサンプルを取り上げています。


以下がサンプルです。公式サイトではプロンプトの記述が分かりにくかったので、本体のソースコードに埋め込みました。
プロンプトは、それまでに行った会話のやりとりの末尾に次の会話を追加していく方法になります。その時、ユーザーとシステムのどちらが答えたかを明示してあげること、会話の区切りは<NL>を付けること、最後に "システム: " を付加するというルールになっています。
ユーザー: 質問1<NL>システム: 回答1<NL>ユーザー:質問2<NL>システム:回答2<NL>・・・
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
#モデルのダウンロード。
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft")
#GPUが使える状態なら使用する。
if torch.cuda.is_available():
model = model.to("cuda")
#プロンプトを作成する。
prompt = "<NL>".join([
"ユーザー: 太陽系について教えてください。",
"システム: 太陽系の何が知りたいですか?",
"ユーザー: 所属している惑星の名前 です",
"システム: わかりました。どのような惑星に興味がありますか?",
"ユーザー: 木星です",
"システム: "
])
#プロンプトをrinnaに与えて、回答を生成する。
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
#rinna からの回答を取得する。
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)会話型(チャット)のサンプル
先ほどのサンプルプログラムだと会話できないので、ループ処理を入れて会話できるように修正してみました。
ちなみに、max_new_tokens=128に設定されているので、少し長い会話になると途切れてしまいます。気になる方は、値を調整してみてください。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
print("rinnaモデルを読み込み中です。")
# モデルのダウンロード。
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft")
# GPUが使える状態なら使用する。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 対話の開始
print("会話を始めましょう!何か質問して下さい。")
while True:
user_input = input("ユーザー: ")
# ユーザーの入力をプロンプトに追加
prompt = f"<NL>ユーザー: {user_input}<NL>システム: "
# プロンプトをrinnaに与えて、回答を生成する。
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt").to(device)
with torch.no_grad():
output_ids = model.generate(
token_ids,
do_sample=True,
max_length=128,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
# rinnaからの回答を取得する。
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print("システム:", output)このプログラムでrinnaと少し会話してみました。その結果が下記です。
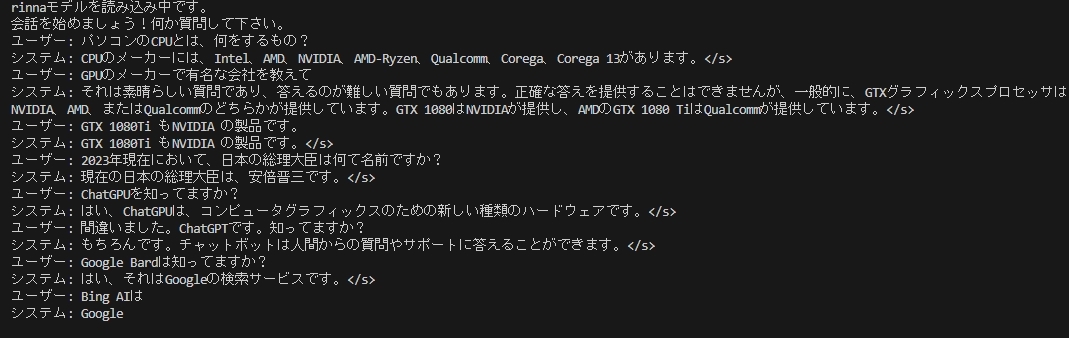
なんか微妙に会話が噛み合いませんでした。
まとめ
今回は2023年5月に公開されたrinna株式会社の大規模言語モデル「rinna」についての特徴、ChatGPTをはじめとする大規模言語モデルとの違い、ローカルPCへのインストール方法と使い方のサンプルについて紹介しました。
性能的にはChatGPT などの有料モデルに劣るものの、ローカルPCにインストールして無料で使える点はかなりメリットが大きく、様々な活用シーンが考えられます。
インストールは簡単ですし、GPUが無くても動作するので、まずはお試しで利用してみてはいかがでしょうか。




コメント