データ分析の現場で広く利用されるファイルフォーマットのひとつに「Parquet」があります。Pythonでは、PyArrowなどのライブラリを使って、Parquetファイルを簡単かつ高速に操作できますが、C#でもParquet.NETを用いることで、同様に手軽に扱うことが可能です。
そこで今回は、C#でのParquetファイルの読み書き方法をわかりやすく解説します。コピペで使える便利クラスも掲載し、参考としてPythonとの速度比較も行っていますので、「Parquet.NET の実力」が気になる方はぜひご一読ください。
Parquetファイルとは
Parquet は、列ごとにデータを保存する「カラム指向」のファイル形式で、データ分析に広く使われています。Apache によって開発され、Hadoop や Spark などの分散処理環境と高い親和性を持ちます。Python(PyArrow)や C#(Parquet.NET)など、複数言語から簡単に扱えるのも魅力です。ファイルは軽量で高速に読み込めるため、データレイクや機械学習ワークフローでも重宝されています。
Parquetファイルの主な特徴
- カラム指向フォーマット
列単位でデータを保存するため、特定の列だけを効率よく読み込める。 - 高速な読み込み性能
必要なデータにだけアクセスできるので、大量データでも処理が速い。 - 高い圧縮率
同じ型のデータが連続するため、Snappyなどの圧縮アルゴリズムがよく効く。 - スキーマ情報を内包
カラム名・型情報などがファイルに含まれており、読み取り時の整合性が保たれる。 - 型の厳格さ
データ型を正確に定義するため、後続処理が安定しやすい(数値・文字列・ブールなど)。 - NULLや欠損値の扱いが明確
データの存在・非存在を判別しやすく、データ分析に向いている。 - HadoopやSparkなどの分散処理と相性抜群
Parquet は分散処理基盤で標準的に使われており、大量データの処理に強い。 - 複数の言語・ツールで利用可能
Python(PyArrow, Pandas)、C#(Parquet.NET)、Java、R など多言語対応。
Parquetのフォーマット
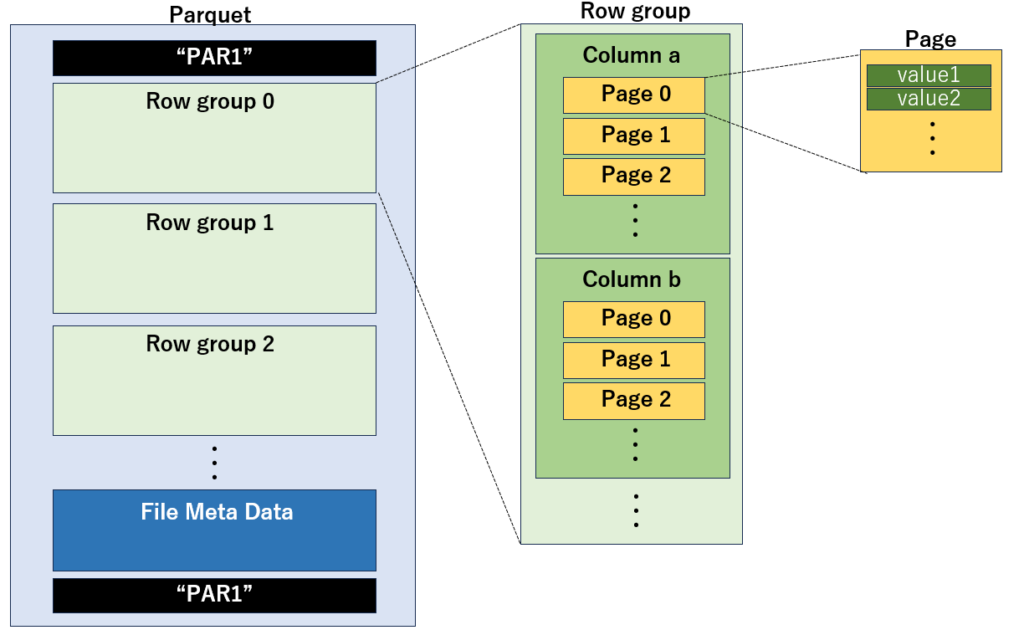
Parquetファイルは、Row Group と呼ばれる複数のデータブロックで構成されており、各 Row Group の内部にはカラムごとにデータが格納されています。さらに、各カラムは複数の Page に分割されており、この Page が Parquet の最小の読み書き単位です。
ファイルの先頭と末尾には、Parquet形式を示すマジックナンバー "PAR1"が埋め込まれています。また、ファイルの末尾には、カラムの型情報やサイズ、Row Group の構造などを含むメタデータが格納されています。
Parquet.Net とは

Parquet.NET は、.NET(C#)環境で Parquet ファイルを手軽に読み書きできるライブラリです。Python や Spark などのツールで主に使われる Parquet を、C# プログラムの中でも自然に扱えるようにしてくれるツールで、軽量かつ直感的な API が特徴です。
このライブラリは、ファイルの読み込み・書き出しに加え、スキーマの定義やデータの型指定、列ごとの操作などにも対応しています。特に、小規模〜中規模のデータを手早く扱いたい場面で活躍し、ログ解析、IoTデータ保存、CAN信号処理などにも応用可能です。
また、NuGet からインストールできるため、Visual Studio や CLI から簡単に組み込み可能です。Python の pandas.to_parquet() に相当する処理を、C#でスマートに行いたいときに頼れる存在です。
| クイックスタート | https://aloneguid.github.io/parquet-dotnet/starter-topic.html#quick-start |
|---|---|
| ドキュメント | https://aloneguid.github.io/parquet-dotnet/starter-topic.html#why |
Parquet.Net のインストール方法
Visual Studio の Nuget から、下記のキーワードで検索します。
parquet.net
Parquet.Net が表示されるので、これを選択してインストールしてください。
Parquet.Net の使い方
Parquetファイルの読み込み
Parquetファイルを読み込むためのサンプルです。Parquetは、複数のRowGroupとカラムで構成されているため、このサンプルでは、先頭のRowGroupのみ取得しています。
reader.Schema.GetDataFields()
→ 実データを持つフィールドのみ取得(計算列や非データフィールドは除外)。OpenRowGroupReader(0)
→ Parquetファイルが複数の RowGroup を持つ場合、最初のグループのみ読み込む処理。ReadColumn(field)
→ 同期的に 1 カラム分のデータを配列形式で取得。
using Parquet;
using Parquet.Data;
// Parquet ファイルを開く(読み取りモード)
using (var stream = File.OpenRead(@"d:\data.parquet"))
{
// ParquetReader を作成(同期バージョン)
using (var reader = ParquetReader.Open(stream))
{
// ファイル内のカラム情報(スキーマ)を取得
var dataFields = reader.Schema.GetDataFields();
// 最初の RowGroup を開く(0番目)
var groupReader = reader.OpenRowGroupReader(0);
// 各カラム(フィールド)に対して処理
foreach (var field in dataFields)
{
// 該当カラムのデータを読み込む(同期)
var column = groupReader.ReadColumn(field);
// カラム名を表示
Console.WriteLine($"Column: {field.Name}");
// カラム内の各値を表示
foreach (var val in column.Data)
{
Console.WriteLine(val);
}
}
}
}Parquetファイルの書き込み
Parquetファイルに書き込むためのサンプルです。
GetDataFields()
→ 実際にデータを持つフィールドのみ取得。書き込み時もスキーマから参照。new DataColumn(field, array)
→ 1 カラム分のデータを配列で定義。列指向フォーマットなので、配列単位で効率的に処理。ParquetWriter.CreateAsync(...)
→ スキーマに沿ってファイル書き込み処理を初期化。CreateRowGroup()
→ Parquetファイル内のレコードまとまり(RowGroup)を開始。読み込み時にはOpenRowGroupReader(n)で取得可能。WriteColumnAsync(...)
→ 列ごとのデータをファイルに書き込み。読み込み時にはReadColumn(...)で一致する構造で抽出可能。
using System.IO;
using Parquet;
using Parquet.Data;
using Parquet.Schema;
async Task WriteParquetFile()
{
// Parquetファイルの書き込み先パス
using (var stream = System.IO.File.Create(@"d:\output.parquet"))
{
// Parquetのスキーマ(カラム名とデータ型)を定義
var schema = new ParquetSchema(
new DataField<int>("id"),
new DataField<string>("name")
);
// id列のデータを定義(int型)
var idColumn = new DataColumn(schema.GetDataFields()[0], new int[] { 1, 2, 3 });
// name列のデータを定義(string型)
var nameColumn = new DataColumn(schema.GetDataFields()[1], new string[] { "Alice", "Bob", "Carol" });
// ParquetWriterを作成(非同期)
using var writer = await ParquetWriter.CreateAsync(schema, stream);
// 1つのRowGroup(レコードのまとまり)を作成
using var rowGroup = writer.CreateRowGroup();
// 各カラムのデータを書き込み
await rowGroup.WriteColumnAsync(idColumn);
await rowGroup.WriteColumnAsync(nameColumn);
}
}Parquet⇔DataTable の相互変換クラス
指定したParquetを読み込んでDataTableを返すメソッドと、DataTableの内容をParquetファイルに書き込むメソッドを持った便利クラスを作りました。静的クラスにしているので、new せずにお使いください。
# Parquetファイルの読み込み
DataTable dt = await ParquetUtils.Read(@"D:\hoge.parquet");
# Parquet ファイルの書き込み
await ParquetUtils.Write(@"D:\hage.parquet", dt);以下がクラスのソースコードです。
using System;
using System.Collections.Generic;
using System.Data; // DataTable を使うために必要
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Windows.Documents;
using Parquet;
using Parquet.Data; // DataTable への拡張メソッドのために必要 (Parquet.Net パッケージに含まれる)
using Parquet.Schema; // ParquetSchema のために必要
namespace ParquetDemo
{
internal static class ParquetUtils
{
/// <summary>
/// 指定されたParquetファイルを読み込み、その内容をDataTableとして返します。
/// カラムの定義はParquetファイルから自動的に推論されます。
/// </summary>
/// <param name="filePath">読み込むParquetファイルのパス</param>
/// <returns>Parquetファイルから読み込まれたデータを含むDataTable</returns>
/// <exception cref="FileNotFoundException">指定されたファイルが見つからない場合</exception>
/// <exception cref="ParquetException">Parquetファイルの読み込み中にエラーが発生した場合</exception>
public static async Task<DataTable> Read(string filePath)
{
using (Stream fs = System.IO.File.OpenRead(filePath))
{
using (ParquetReader reader = await ParquetReader.CreateAsync(fs))
{
// DataTable構築
var dt = new DataTable();
var dataFields = reader.Schema.GetDataFields();
foreach (var df in dataFields)
{
var clrType = Nullable.GetUnderlyingType(df.ClrNullableIfHasNullsType)
?? df.ClrNullableIfHasNullsType;
dt.Columns.Add(df.Name, clrType);
}
for (int i = 0; i < reader.RowGroupCount; i++)
{
using var rgReader = reader.OpenRowGroupReader(i);
var columns = new Parquet.Data.DataColumn[dataFields.Length];
for (int j = 0; j < dataFields.Length; j++)
{
columns[j] = await rgReader.ReadColumnAsync(dataFields[j]);
}
int rowCount = columns[0].Data.Length;
for (int r = 0; r < rowCount; r++)
{
var rowValues = new object[dataFields.Length];
for (int c = 0; c < dataFields.Length; c++)
{
rowValues[c] = columns[c].Data.GetValue(r)!;
}
dt.Rows.Add(rowValues);
}
}
return dt;
}
}
}
public static async Task Write(string filePath, DataTable dt)
{
using Stream output = File.Create(filePath);
// スキーマ構築
var fields = new List<DataField>();
foreach (System.Data.DataColumn col in dt.Columns)
{
Type clrType = col.DataType;
// Parquet.Net は null 許容型をサポートしているが、DataTable 側は非対応なのでそのまま
if (clrType == typeof(int)) fields.Add(new DataField<int>(col.ColumnName));
else if (clrType == typeof(long)) fields.Add(new DataField<long>(col.ColumnName));
else if (clrType == typeof(double)) fields.Add(new DataField<double>(col.ColumnName));
else if (clrType == typeof(bool)) fields.Add(new DataField<bool>(col.ColumnName));
else if (clrType == typeof(string)) fields.Add(new DataField<string>(col.ColumnName));
else if (clrType == typeof(DateTime)) fields.Add(new DataField<DateTime>(col.ColumnName));
else
throw new NotSupportedException($"型 {clrType} は現在未対応です");
}
var schema = new ParquetSchema(fields);
using var writer = await ParquetWriter.CreateAsync(schema, output);
using var rowGroupWriter = writer.CreateRowGroup();
foreach (DataField field in fields)
{
var col = dt.Columns[field.Name];
Array values = Array.CreateInstance(field.ClrType, dt.Rows.Count);
for (int i = 0; i < dt.Rows.Count; i++)
{
object? raw = dt.Rows[i][col];
values.SetValue(raw == DBNull.Value ? null : raw, i);
}
var dataCol = new Parquet.Data.DataColumn(field, values);
await rowGroupWriter.WriteColumnAsync(dataCol);
}
}
}
}Pythonとの速度比較
C#とPythonの速度比較結果です。790KbyteのParquetファイルを読み込む時間と、書き込む時間を計測しました。
結論から言うと、Parquetファイルの読み込みは、C#とPythonではほぼ互角ですが、書き込みはPythonが6倍高速でした。
読み込み時間の比較
Parquetファイルの読込については、C#,Pythonとも互角でした。2回目以降はPythonの方が圧倒的に高速ですが、Pyallowのキャッシュが効いているのかもしれません。
| 回数 | Parquet.Net(C#) | Pandas + pyarrow(Python) |
|---|---|---|
| 1回目 | 0.514 秒 | 0.503 秒 |
| 2回目 | 0.266 秒 | 0.046 秒 |
| 3回目 | 0.266 秒 | 0.050 秒 |
書き込み時間の比較
一方書き込みでは、Pythonの圧倒的勝利です。Pythonは内部最適化と C++ バックエンドの恩恵だと思われます。
| 回数 | Parquet.NET(C#) | Pandas (Python) |
|---|---|---|
| 1回目 | 0.386 | 0.064 |
| 2回目 | 0.229 | 0.066 |
| 3回目 | 0.232 | 0.064 |
下記は計測で使ったPythonプログラムです。
import pandas as pd
import time
# 測定対象のファイルパス
input_path = r"P:\can_in.parquet"
output_path = r"P:\can_out.parquet"
# 読み込み時間計測
start_read = time.time()
df = pd.read_parquet(input_path, engine="pyarrow")
end_read = time.time()
print(f"読み込み時間: {end_read - start_read:.3f} 秒")
# 書き出し時間計測
start_write = time.time()
df.to_parquet(output_path, engine="pyarrow", compression="snappy")
end_write = time.time()
print(f"保存時間: {end_write - start_write:.3f} 秒")まとめ
本記事は、C#環境で Parquet ファイルを扱う方法を中心に、Parquet.NETの使い方とその特徴を解説しました。Python(PyArrow)との性能比較では、読み込み処理では互角の結果となり、書き込み処理では Python が優位でしたが、C#でも実用的な速度で十分に運用可能です。
Parquetは、高速・高圧縮でスキーマを保持できるカラム指向のフォーマットであり、分散処理やデータ分析に適した構造を持っています。C#でも簡潔なコードで扱えることから、ログ保存やCAN信号処理、業務データの可視化など、幅広いシーンに応用できます。
Parquetは、Pythonを使う方が圧倒的に簡単且つ高速ですが、諸事情でC#からParquetを扱う必要が生じた方は、是非本記事を参考にしてください。








コメント