Quest2を買って早一年、この10月にはQuest3が出るようですが、VRの楽しみ方の1つとして、普通の2D写真を疑似的に3D化して大画面で鑑賞するという方法があります。
2D写真を3D化するには、写っている物の奥行きを推定(=深度推定)し、そこから左右の視差を計算し、それを元に左目と右目用の写真を作り出すという手順を踏みます。
今回は、3D化に欠かせない深度推定において、MiDaS と呼ばれるモデルを使って実現する方法を紹介したいと思います。
MiDasとは
MiDaSは(Mixed Depth and Scale Network)の略で、画像から奥行き(深度)を推定するニューラルネットワークです。
1枚の写真から各部分の深度を推測し、DepthMapを生成します。これを使うことで2D画像を疑似的に3D化することが可能となります。
MiDaSは、自動運転、バーチャルリアリティ、3D復元、セマンティックセグメンテーションなど、さまざまな応用分野で活用されています。
WinPython環境の構築
まず最初に、「【お手軽】WinPython+Portable Gitでお手軽Python環境を構築しようよ」の手順に従ってPython環境を構築して下さい。
以降は、この環境のことを「WinPython+PortablGit」環境を呼び、この環境を前提とした説明を行います。自身の環境で動作させる場合は、適宜読み替えをお願いします。
MiDaSのインストール
MiDaSを使えるようにするには、次の手順が必要です。
- MiDaSのダウンロード( git Clone ~ 又は Download.Zipファイルのダウンロード&解凍)
- モデルのダウンロード
- 必要モジュールのインストール(pip install ~)
では、それぞれの手順について詳しく説明していきます。
MiDaSのダウンロード
MiDaSはGitHubに公開されているので、git clone を使ってダウンロードするか、下記のページから直接 Download.Zipをダウンロードして下さい。
https://github.com/isl-org/MiDaS
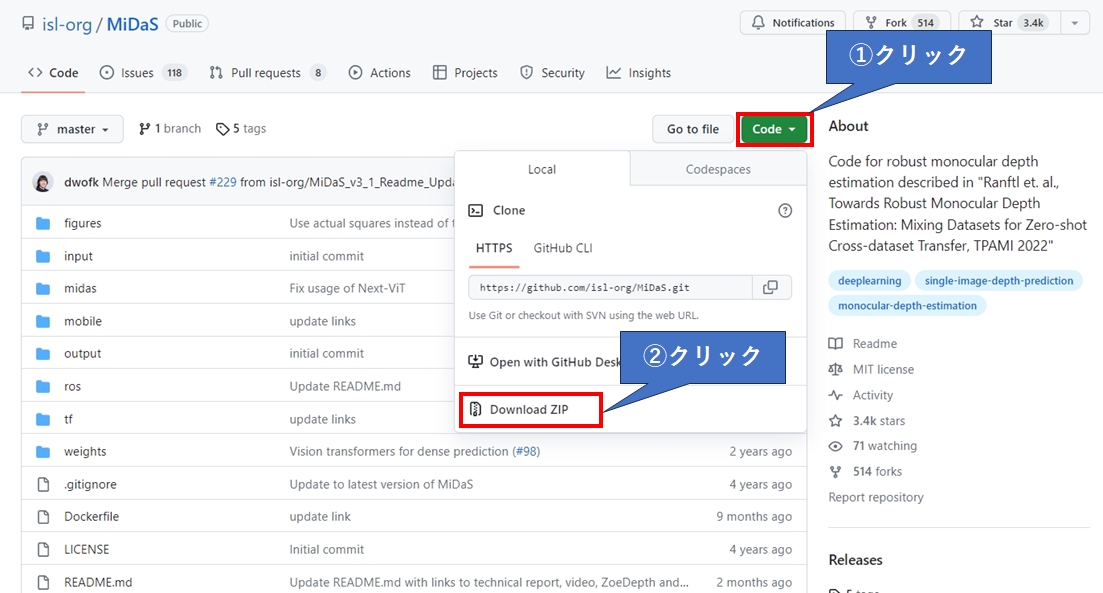
ダウンロードに成功すると、MiDaS-master.zip というファイルが出来上がっています。これを任意のフォルダに解凍して下さい。
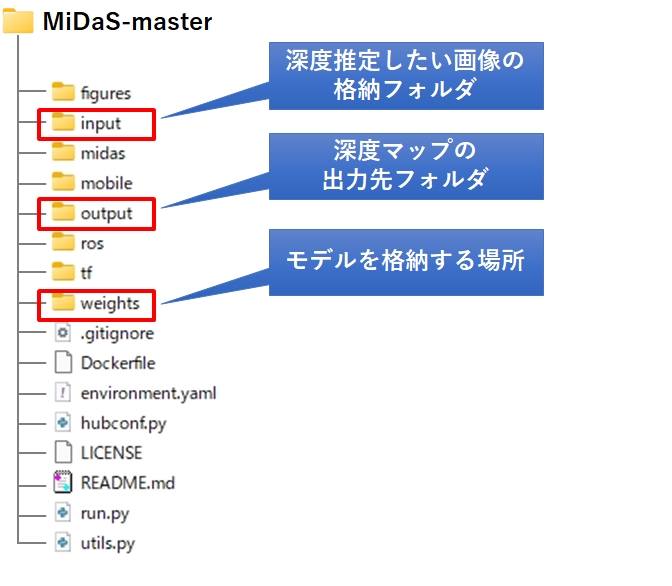
解凍すると下記のフォルダ構成が展開されます。
MiDaSで深度推定を行うには学習済みモデルが必要ですが、Zipファイルには同梱されていません。後述する手順で使いたいモデルをダウンロードし、 weights フォルダに格納して下さい。
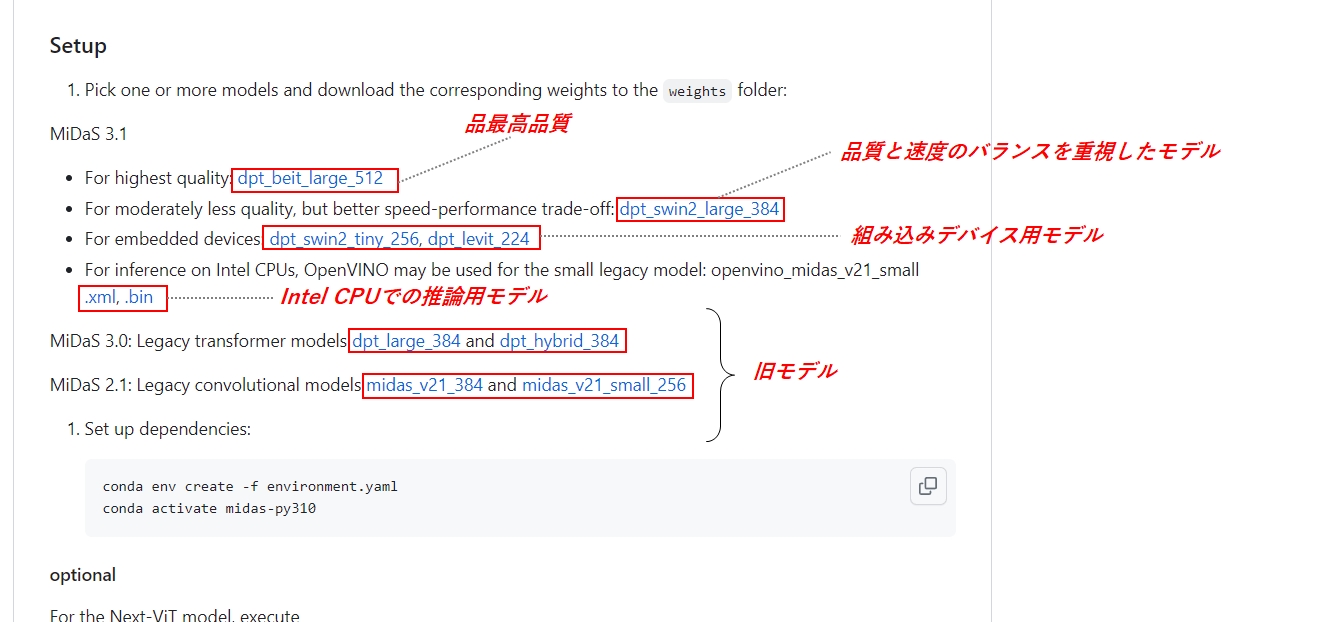
モデルのダウンロード
Download.Zipをダウンロードしたページ(https://github.com/isl-org/MiDaS)を下方向に少しスクロールすると、よく使われるモデルのリンクが張られていますので、ここからダウンロードして下さい。
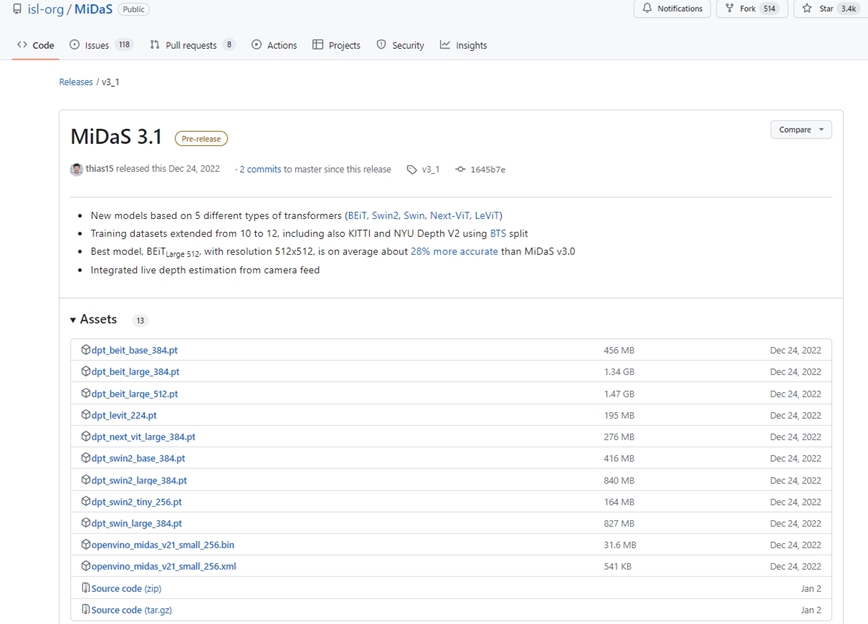
過去バージョンのモデルや、サイズが小さいモデルを利用したい場合は、下記のリンクからダウンロードすることが可能です。
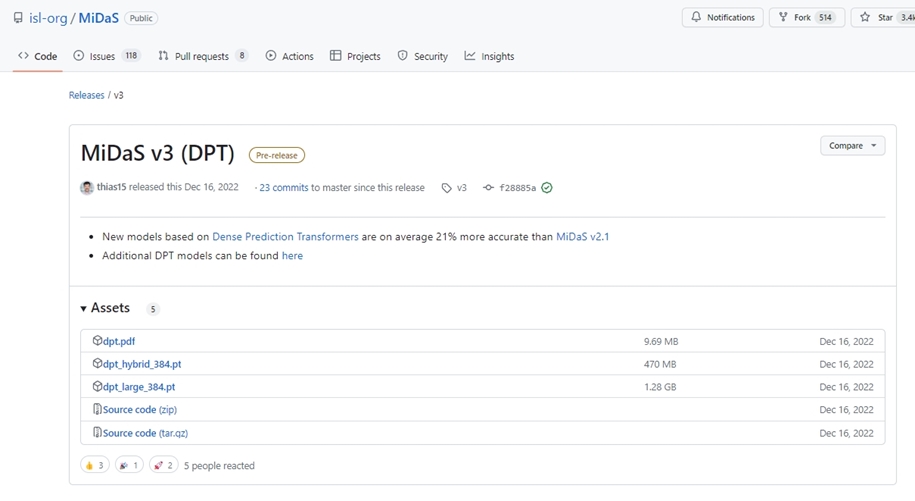
モジュールのインストール
@CommandPrompt を起動し、下記のコマンドを実行して下さい。
pip install opencv-python
pip install imutils
pip install timm==0.6.12
既に timm の最新がインストールされている場合は、MiDaS 3.1のモデルを指定するとエラーになります。この場合は一旦 timmをアンインストールしてから、timmのバージョンに0.6.12を指定して再インストールして下さい。
pip uninstall timm
pip install timm==0.6.12
また、GPUを使いたい場合は、下記も併せてインストールしておきましょう。
pip install torch==2.0.1.0+cu118 torchvision torchaudio -f
https://download.pytorch.org/whl/torch_stable.html
MiDaSの使い方
run.py というサンプルプログラムが同梱されていますので、これを使えば簡単に深度マップが作成できます。
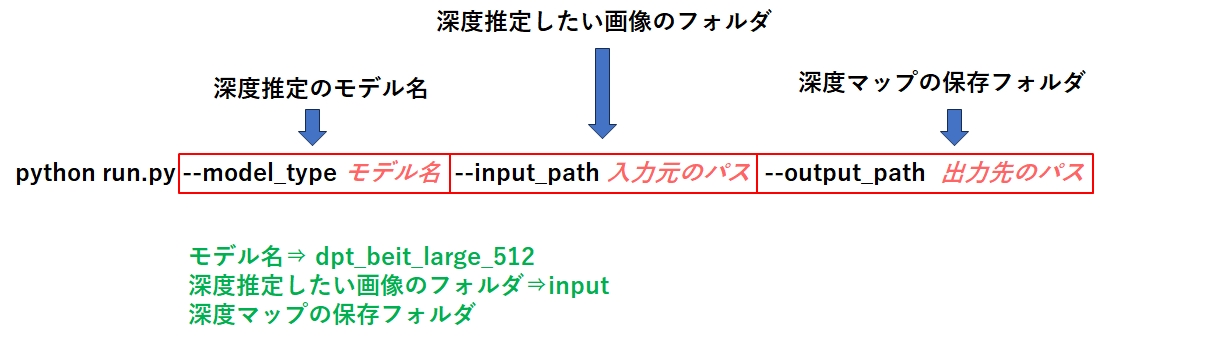
まず run.pyを実行する前に、下記の準備をしておきましょう。
- モデルファイル dpt_beit_large_512 をダウンロードし、weights フォルダに格納しておく
- @CommandPrompt 上で、MiDaS-master.zipを解凍したフォルダ(run.pyが格納されているフォルダ)にカレントフォルダを移動する。
- run.pyと同じ階層にある inputフォルダに、深度推定したい画像ファイルを任意の数だけ格納
準備が終わったら、下記のコマンドを実行します。
python run.py --model_type dpt_beit_large_512 --input_path input --output_path output
実行するとコマンドプロンプトに結果が表示されます。
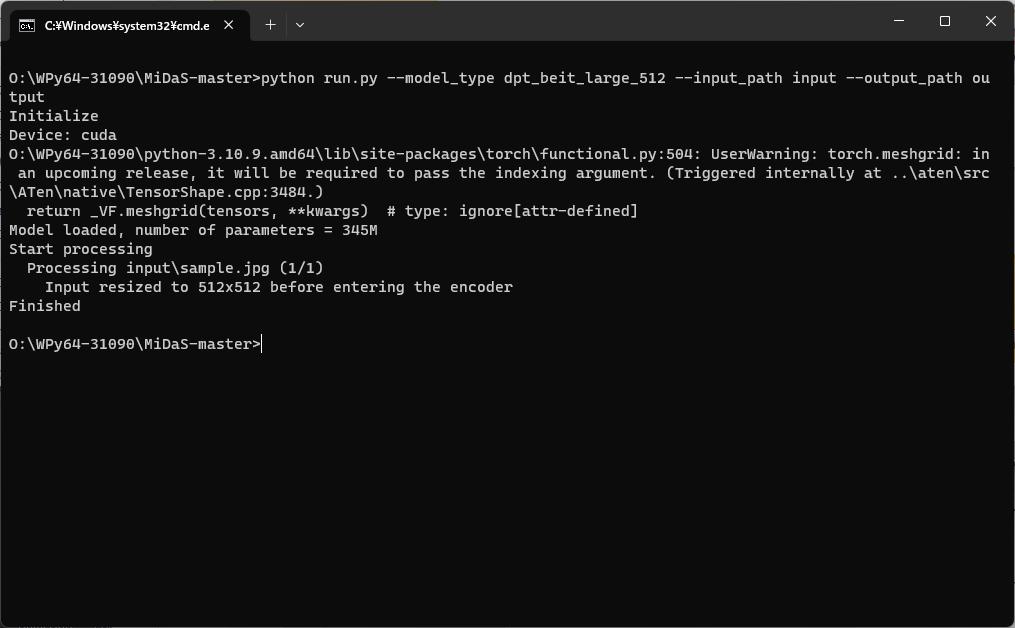
深度マップは run.py と同じ解像にある output フォルダに格納されます。
今回は inputフォルダに1枚だけ画像を格納しましたので、下記の深度マップ(DepthMap)が生成されました。

コマンドには数多くの引数がありますので、紹介しておきます。よく使いそうなのは、元画像と深度マップを並べて1つの画像として出力する --side オプションと、深度マップをグレイスケールで生成する --grayscaleオプションくらいでしょうか。
| オプション | 説明 |
|---|---|
| -h --help | ヘルプメッセージを表示して終了します。 |
| -i INPUT_PATH --input_path INPUT_PATH | 入力画像が含まれるフォルダを指定します(入力パスが指定されていない場合、カメラから画像を取得しようとします)。 |
| -o OUTPUT_PATH --output_path OUTPUT_PATH | 出力画像を保存するフォルダを指定します。 |
| -m MODEL_WEIGHTS --model_weights MODEL_WEIGHTS | 学習済みモデルの重みへのパスを指定します。 |
| -t MODEL_TYPE --model_type MODEL_TYPE | モデルタイプを指定します。 可能なモデルタイプ dpt_beit_large_512、dpt_beit_large_384、dpt_beit_base_384、dpt_swin2_large_384、dpt_swin2_base_384、dpt_swin2_tiny_256、dpt_swin_large_384、dpt_next_vit_large_384、dpt_levit_224、dpt_large_384、dpt_hybrid_384、midas_v21_384、midas_v21_small_256、openvino_midas_v21_small_256。 |
| -s --side | 出力画像にRGB画像と深度画像を横に並べて表示します。 |
| --optimize | ハーフフロートの最適化を使用します。 |
| --height HEIGHT | 推論時にエンコーダに供給される画像の好ましい高さを指定します。好ましい高さは32の倍数に整列されるため、実際の高さとは異なる場合があります。このパラメータが設定されていない場合、多くのモデルはトレーニング時に選択された高さを自動的に使用します。 |
| --square | 画像を正方形の解像度にリサイズするオプションです。画像がエンコーダに供給される際に幅を変更して解像度を正方形にします。このパラメータが設定されていない場合、モデルがサポートする場合は画像のアスペクト比を維持しようとします。 |
| --grayscale | infernoカラーマップの代わりにグレースケールカラーマップを使用します。デフォルトで使用されるinfernoカラーマップは視認性が向上しますが、このカラーマップの精度制限により、PNGファイルには8ビットの深度値しか保存できません(16ビットの深度値は保存できません)。 |
深度マップの生成例
run.py に--sideオプションを付けて、色々な画像から深度マップを生成してみました。結構上手く深度推定されているようです。

まとめ
今回は 深層学習を使って1枚の画像の深度推定を行う MiDaSについて、ダウンロード方法、インストール方法、使い方について紹介しました。
1枚の2D写真から奥行きを推定するという難しそうなテーマですが、かなり現実に近い形で推定できました。
ただ、推定する処理は結構重いので、ある程度性能のあるGPU(RTX-3000シリーズ、RTX-4000シリーズ)がないと辛いかもしれません。
AIがもっと普及して、高性能はGPU(又はAI専用チップ)が安く購入できるようになれば有難いですね。








コメント