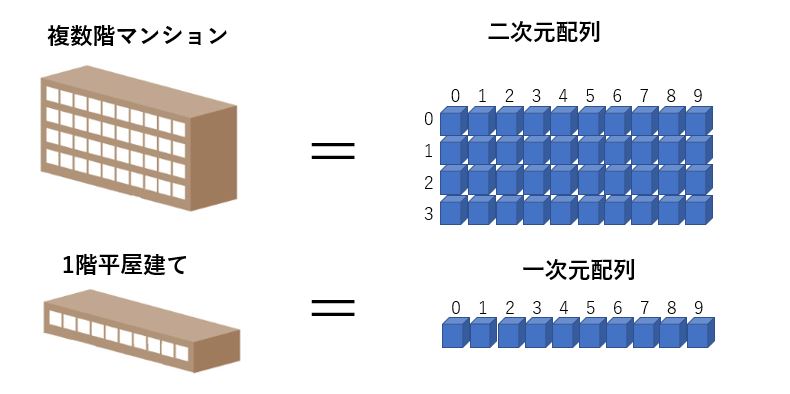
マンションは、複数の部屋が縦や横につらなって1つの建屋を構成していますが、これと同じイメージでデータを格納する変数を、配列変数(略して配列)と呼んでいます。
この配列にはいくつかの派生形があり、1つはリスト(List)、もう1つは辞書(Dictionaly)と呼ばれるものです。
この記事では、配列、リスト、辞書の違いと、C#でどのように扱うかを解説しています。
配列とは
冒頭で説明しましたが、配列はマンション(集合住宅)のようなもので、1つの部屋に1つの値が格納できます。
値を格納したり、取り出したりするには、部屋番号に相当する数値を指定する必要があり、これを「添え字」と呼びます。
そして、1つ1つの部屋に相当する値の格納場所のことを「要素」と呼びます。
配列は、あらかじめサイズ(要素の数)を決める必要があり、作った後はサイズの変更ができません。
ちなみに、変数を作るという行為は「変数を宣言する」という言い方をします。
変数を宣言する時、型名の隣に[] を付加することで、配列変数にすることが出来ます。
また、必ず new を付けて、値を格納する箱を確保しなければなりません。
型名[] 変数名 = new 型名[要素の数]
例えば、以下の様な記述をします。
// dataという変数名で、10個の要素を持つint 型の配列(1次元配列)を宣言
int[] data = new int[10];
// dataという変数名で、縦50,横50個の要素を持つint 型の配列(2次元配列)を宣言
double[] data = new double[50,50];
// dataという変数名で、"aaa","bbb","ccc"という3つの要素を持つ配列を宣言
string[] data = new string[]{"aaa","bbb","ccc"};一般的に1次元配列は非常に良く使いますが、2次元配列はあまり使われません。
値の代入や取り出し方法は、先頭からの番号(添え字)を指定するのですが、添え字は0から始まっている事にご注意ください。
//dataという名前が付けられた int 型配列の5番目の要素に10を代入
data[4] = 10;
//dataという名前が付けられた string 型配列の7番目の要素から変数を取り出す
string res = data[6]; リスト(List)
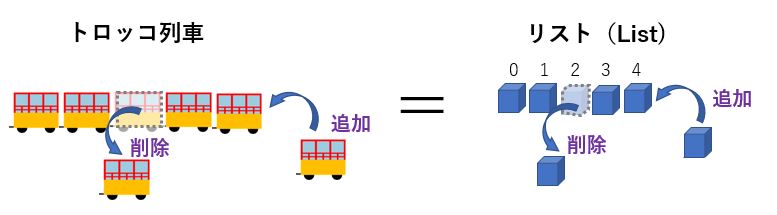
リストは、後から要素を自由に追加/削除できる1次元配列です。
トロッコ列車の様に、1つ1つの要素が連結したような構造になっていて、任意の要素を削除したり、そこへ追加したり、あるいは並べ替えを行う事も可能です。
リストを宣言する時、必ず型を指定する必要があります。
List<int> data = new List<int>();
例えば、以下の様な記述をします。
// dataという変数名で、10個の要素を持つListを宣言
List<int> data = new List<int>();
// dataという変数名で、縦50,横50個の要素を持つListを宣言
List<double> data = new List<double>();
// dataという変数名で、"aaa","bbb","ccc"という3つの要素を持つListを宣言
List<string> data = new List<string>(){"aaa","bbb","ccc"};値の代入や取り出し方法は、配列と同様に0から始まる添え字を使います。
取り出しや値の設定方法は、配列とまったく同じ記述になります。
//dataという名前が付けられた int 型配列の5番目の要素に10を代入
data[4] = 10;
//dataという名前が付けられた string 型配列の7番目の要素から変数を取り出す
string res = data[6]; Listは配列と異なり、要素の追加や削除を行うためのメソッドが用意されています。
| 用途 | メソッド |
|---|---|
| 末尾に1要素だけ追加 | Add(値) |
| 末尾に配列の内容を追加 | AddRange(配列) |
| 指定位置に1要素だけ挿入 | Insert(挿入位置,値) |
| 指定位置に配列の内容を挿入 | InsertRange(挿入位置,配列) |
| 指定した要素を削除 | Remove(値) |
| 指定した位置の要素を削除 | RemoveAt(削除位置) |
| 指定した位置から指定個数を削除 | Remove(削除位置,削除個数) |
| 並べ替え | Sort() |
次にいくつかの使用例を挙げておきます。
//dataという名前が付けられた int型Listの末尾に 5 を追加
data.Add(5);
//dataという名前が付けられた int型Listの3番目の要素を削除
data.RemoveAt(2);
//dataという名前が付けられた string型Listから "aaa" の値を持つ要素を削除
data.Remove("aaa");
//dataという名前が付けられた double型Listを並べ替え
data.Sort();
辞書(Dictionary)
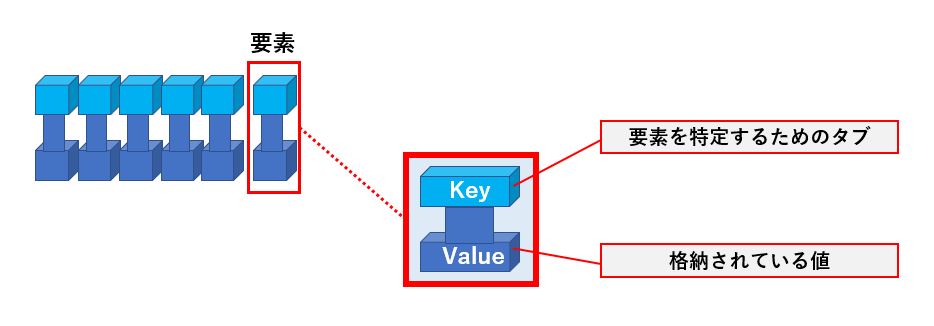
辞書(Dictionary)は連想配列とも呼ばれており、Listとよく似ていますが、値の取り出し方が添え字ではなく、「任意の値」である点が異なります。
例えるなら、事務で書類を整理するために用いるタブ付きファイルです。

タブ付きファイルは、タブの部分に見出しを付けることで、必要な書類を探しやすくしますよね。
Dictionaryは、これと同じ構造になっています。
Dictionaryの要素1つにつき、要素を特定するための情報を格納するKeyプロパティと、実際の値が格納されているValueプロパティが存在します。
KeyプロパティとValueプロパティの型は、Dictionaryを宣言する際に指定します。
//Keyが整数で、Valueが文字列の辞書を宣言
Dictionary<int,string> dic = new Dictionary<int,string>();
//Keyが文字列で、value が実数の辞書を宣言
Dictionary<string,double> dic = new Dictionary<int,string>();Dictionary で宣言した後は、辞書にKeyとValueを登録していきますが、この時にAddメソッドを使います。
//Keyが整数で、Valueが文字列の辞書に値を追加する
dic.Add(3,"abc");
//Keyが文字列で、value が実数の辞書に値を追加する
dic.Add("pi",3.1415926);要素を特定する場合は、Keyの値を使います。
Listは添え字でしたが、Dictionaryは Addメソッドによる追加の際に用いたKeyの値を[ ] 内に記述します。
//Keyが整数で、Valueが文字列の辞書に Add(3,"abc")で要素を登録済み
string str = dic[3]; //値の取り出し
dic[3] = "xyz"; //値の変更
//Keyが文字列で、value が実数の辞書にAdd("pi",3.1415926)で要素を登録済み
double val = dic["pi"]; //値の取り出し
dic["pi"] = 1.234567; //値の変更
Dictionaryからデータを削除する場合もKeyの値を使います。
//Keyが整数で、Valueが文字列の辞書に Add(3,"abc")で要素を登録済み
dic.Remove(3);
//Keyが文字列で、value が実数の辞書にAdd("pi",3.1415926)で要素を登録済み
dic.Remove("pi");Listは追加や削除のメソッドが複数あり、ソート機能までありましたが、Dictionaryの場合は追加、削除とも1種類しかなく、ソート機能はありません。
というのも、DictionaryにAddで登録した際、自動的にKeyの値でソートされるからです。
このため、Addした順番で要素を取り出すようなことは出来ません。
配列、リスト、辞書の比較
では、配列、リスト、辞書についての違いを比較したいと思います。
| 機能 | 配列 | リスト(List) | 辞書(Dictionary) |
|---|---|---|---|
| 宣言時の要素数 | 個数の指定が必要 | 不要 | 不要 |
| 要素数の変更 | 不可 | 可能 | 可能 |
| 要素の指定方法 | 添え字(連番) | 添え字(連番) Findメソッド | Keyで指定した値 |
| 要素の追加 | 不可 | 可能 | 可能 |
| 要素の挿入 | 不可 | 可能 | 不可 |
| 要素の変更 | 可能 | 可能 | 可能 |
| 要素の削除 | 不可 | 可能 | 可能 |
| 並べ替え | 不可 | 可能 | 不可 |
| その他 | Arrayクラスのメソッドで挿入、削除は可能 | Addした順番で取り出すことが可能 | Addした順番での取り出しは出来ない |
| メリット | メモリ消費が少ない |
配列は融通が利かないですが、メモリ消費量が少なく、添え字で検索する際には一番高速ですが、要素(値)そのものを検索するメソッドは存在しません。
Listは配列に比べてメモリ消費量が若干多くなりますが、Findメソッドを使って要素(値)そのものを検索することが可能です。
Dictonaryは検索に特化したものであるため、要素を[ ] で特定する際にも高速で検索してくれます。
配列、リスト、辞書の用途
それぞれについて、向く/向かないの用途は次の通りです。
| 用途 | 配列 | リスト(List) | 辞書(Dictionary) |
|---|---|---|---|
| 向いている用途 | ループ処理する際、宣言時に個数が確定できる場合 | ①ループ処理する際、宣言時に個数が未定の場合 ②処理途中に挿入や削除がしたい場合 ③要素の中身で並び替えしたい場合 | Keyを使って高速に検索したい場合 |
| 向かない用途 | 添え字ではなく、要素(値)で検索したい場合 | 左に同じ | Addで登録した順番で処理したい場合 |
配列はループ処理を使う場合に宣言するケースが大半ですが、ループ処理の直前で要素数が分かって、処理途中で要素の挿入や削除が発生しない場合は、配列で良いと思います。
逆に言うと、ファイルからデータを読み込むなど、最後まで処理を進めないと要素数がハッキリしない場合、或いは処理条件によってデータの追加や削除、挿入、並べ替えが発生するか、将来その可能性がある場合はListが向いています。
Dictionaryはループ処理するというよりは、何らかのマスターデータがあって、読み込んだデータと突き合わせてDictionaryから値を取り出すような場合に使うのが効果的です。
これら以外にも、Listとよく似たArrayListや、Dictionaryとよく似たHashtableというのもありますが、現在は非推奨になっているので、この記事では触れていません。
Containsによる存在チェック
配列、List、Dictionaryに共通して、要素(値)が既に登録されているか否かをチェックしたいことがよくあります。
例えば、連続してデータを読み込む際、重複しているデータを排除したい場合や、同じデータの個数を数えたい場合などです。
また、DictionaryにKeyを登録する際、重複しているとエラーになるため、これを防ぐ目的でチェックしたい場合もあります。
それぞれについての存在チェックは以下の通りです。
| 配列 | Contains<型>(値) |
| リスト(List) | Contains(値) |
| 辞書(Dictionary) | Containskey(値) ContainsValue(値) |
配列の場合だけ、少し形が違っていて、<型>を指定する必要があります。
実は、ListとDictionary には存在チェックするためのContainsメソッドが用意されているのですが、配列にはそれがありません。
しかし、ベースとなるクラス(Generic クラス)のメソッドに、少々使い方は違いますが、Containsというのがあり、これを利用しています。
ListもDictionaryも、配列と同じような書き方で存在チェックが出来ますが、ListやDictionaryには、もっと簡単に使える(記述できる)Containsメソッドが用意されているという事です。
更に、Dictionaryについては、キーの存在チェックと値の存在チェックの2通りが用意されています。
まとめ
今回は配列、List、Dictionaryについての概念と主要なメソッドについて解説しました。
C#には、ここから派生したクラスがいくつか用意されていますが、通常はほとんど使う機会がありません。
もし必要となったら、また別の記事で説明したいと思います。







