
2023年2月、最近やたらとメディアに取り上げられているチャットGPT(Chat GPT)。
Google検索でのキーワード需要が急激に伸びていることから、みなさんの関心の高さがうかがえます。
一般的な説明については「【実験】チャットGPT(ChatGPT)に直接インタビューしてみた結果を公開します。」の記事でチャットGPTとの質問形式でまとめていますので、本記事ではもう少し技術的な情報について紹介したいと思います。
チャットGPT(Chart GPT)の概要
チャットGPTの公式サイトは下記URLから訪問できます。この記事を読んだ後は、実際に触ってお試しください。

詳しい手順は「【スクショで解説】チャットGPT(Chat GPT)のアカウント作成~ログイン&使い方の解説」に記載していますので、併せてご利用下さい。
チャットGPTとは
チャットGPTは、サンフランシスコの非営利団体「OpenAI」によって開発された自然言語生成モデルです。
GPTとは、Generative Pretrained Transformer(生成的な事前学習トランスフォーマー)の略なのですが、大量のテキストデータの学習を行い、人間のような自然な文章を生成することが可能です。
特に、質問応答タスクや対話タスクに特化してトレーニングされており、人間と対話するような会話形式で回答を返してくれます。
しかし、学習データがWebに存在する大量のテキストであり、これらの中には間違った情報が含まれている可能性があり、すべての質問に対して正しい回答が保証されません。
つまり、質問をする側もチャットGPTが出した回答を鵜吞みにするのではなく、何らかの裏付けや検証によって正確か否かを判定するスキルが求められます。
ただ、人間との会話形式でやり取りできる点は今までにないメリットであり、チャットボットはもとのり検索エンジンとしての需要にも注目されています。今までのキーワード羅列型の検索スタイルから、対話形式の検索スタイルへ進化を遂げるのは、もうすぐかもしれません。
OpenAIとは
OpenAIは、人工知能に関する研究と開発を目的とする非営利組織として、2015年にサンフランシスコで設立されました。
設立者には、ElonMusk(イーロン・マスク)、SamAltman(サム・アルトマン)、GregBrockman(グレグ・ブロックマン)、IlyaSutskever(イリア・サツケーヴァー)、WojciechZaremba(ボイチェフ・ザレンバ)、JohnSchulman(ジョン・シュールマン)らの著名な技術者やビジネスマンが名を連ねています。
OpenAIの目的は、人工知能を安全かつ適切に利用することを通じて、人類の未来を改善することです。そのために、人工知能に関連する研究、開発、教育、普及活動などを行っています。
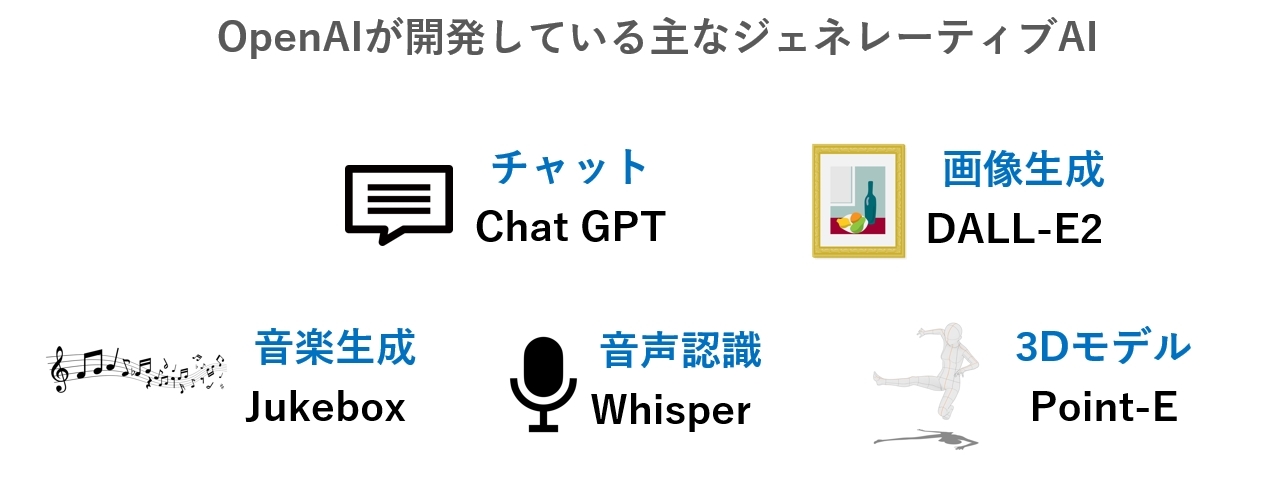
OpenAIは、GPTやDALL-E、GPT-3などの大規模な言語モデルを開発し、人工知能技術の一層の発展に貢献しています。また、人工知能に関連する政策や倫理、法律の問題にも取り組んでおり、人工知能の普及と利用に関する社会的な議論を促進しています。
現在、OpenAIの時価総額3兆8千億円であり、これはキャノンや富士通の時価総額に相当します。
イーロンマスク氏は、今後ともOpenAIへの支援は継続しつつも、2018年に役員から退いています。理由は、「TeslaがAIへの取り組みの強化を続ける中で、将来的にElonに利益が相反する可能性が生じることを回避するための措置」とのことです。
引用元:CNET Japan
チャットGPTの使い方(UI、API)
チャットGPTの利用方法として一番手軽なのは、公式サイトのチャット画面から質疑応答することです。現在、OpenAIのウェブサイト、Slack、Discord から簡単に利用することが可能です。
しかし、本来の使い方は Web API を通じて質疑応答することです。
OpenAIのウェブサイトからAPI Key(有料) を入手し、それを使って質問を投げ、回答を受信します。
チャットGPTはテキストでやり取りするのですが、音声認識と音声合成を前後に挟んであげることで、発話での質疑応答も可能です。
このように、API化されていることにより今後様々なサプリやサービスでチャットGPTが利用されることになりますので、「知らない間にチャットGPTを使っていた」というケースはそう遠くないでしょう。
他のチャットボットとの違い、特徴について
従来のチャットボットは、特定の業務に関する質問と回答を対にして学習させることで、対話を実現させていました。
言い換えると、チャットボットの内部には学習によって得られた質疑応答のリストがあり、これを使って回答を返しているだけです。
今でこそ多少曖昧な表現でも回答を得られるようにはなりましたが、それは曖昧な質問内容が、質疑応答リストのどれに該当するかを見分ける能力が向上したに過ぎません。
一方、チャットGPTは、入力されたテキストから次の単語を予測するという手法で文章を生成していくため、特定の業務に特化することなく、幅広い質問に対する回答を得られるようになっています。
チャットGPTの特長として、次のものが挙げられます。
ちなみに、回答の矛盾に気が付いて指摘すると、非を認めて謝罪してくれました。
- 同じ質問に対して、毎回ニュアンスや表現を変えてくる
- これまでの会話内容(履歴)を前提として、新たな質問に回答してくれる
- 自分の回答に対して間違いを指摘されると、それを認めて謝罪する。
- 正しくない前提があれば、意義を唱える
- 倫理的、道徳的に不適切なリクエストには応じない
いずれも従来のチャットボットでは実現し得なかったものばかりです。
以下は、チャットGPTに矛盾を指摘した時の反応です。

チャットGPTが返す回答の課題
チャットGPTは、Web上にある約1TB文のテキストを学習した大規模な言語モデルであるため、多様なトピックに関して回答を生成することが可能です。しかし、学習データの全てが正しいものとは限らないため、以下の課題があります。
- 正確性: 学習データの中には誤った情報も含まれており、特に最新情報や事実に関しては情報が不足気味であるため、誤った回答があたかも正しいように返される可能性(ハルシネーション=幻覚)があります。従って、最終的な判断は常に自分で行うことが重要です。
- 偏向性: 学習データの中には特定の人種、国、宗教に関する偏った情報が含まれている可能性があるため、チャットGPTが出す回答も何かに偏っている(偏向している)可能性があります。
- 倫理的な問題: 学習データの中には人種、性別、宗教などに関して倫理的に反する意見や問題が含まれている可能性があるため、返される答えも時には倫理に反しているかもしれません。
従って、チャットGPTの回答を活用する場合は、他の情報源とも照らし合わせて、正確な情報を確認であるかを自ら判断する力が求められます。
もっとも、現在の検索エンジンを使った検索結果を活用する場合も同じことが言えるのですが、ことAIがそれらしい回答を返してくるので、受け取り側もついつい信じてしまいがちです。
利用料金

2024年1月時点では、無料と有料の2種類となります。無料版はチャットブラウザ上でGPT-3.5を使ったチャットしかできませんが、有料版はGPT-4が選択可能で、且つ従量課金制のAPI公開など、様々なサービスが展開されています。
| 無料プラン | 有料プラン | |
|---|---|---|
| 費用 | 0円 | 20ドル/月(約2600円/月) |
| ピーク時間帯の利用 | △ (利用制限あり) | 〇 (優先的に提供) |
| レスポンス時間 | △ | 〇 |
| 新機能と改善の提供 | △ | 〇 (優先的に提供) |
APIの料金に関する詳細は株式会社Goatmanの「【24年最新版】ChatGPT(OpenAI)のAPI料金体系まとめ」に詳しく記載されています。
登場までの歴史

チャットGPTの歴史は浅く、2018年に今の原型となるGPT-1がリリースされています。以降、現在に至るまでの歴史を振り返ってみましょう。
| 2015年 | サム・アントルマン、イーロンマスクらによってOpenAI設立 |
| 2018年 | 最初のGPTモデル、GPT-1をリリース |
| 2019年 | GPT-2をリリース マイクロソフトとMatthew Brown Companiesが10億米ドル (約1300億円)を投資 |
| 2020年 | GPT-3をリリース |
| 2022年 | 12月に対話型チャットAI「チャットGPT」をリリース リリース後1週間以内にユーザー数100万人を突破 |
| 2023年 | 1月にマイクロソフトが100億ドル(約1.3兆円)の追加投資を表明 3月にGPT-4をリリース。有料会員向けに公開。 10月にチャットGPT大型アップデート |
採用されているアルゴリズム

GPT (Generative Pretrained Transformer) は、Transformer と呼ばれる深層学習アルゴリズムをベースに改良されたものです。
Transformerは、文書の分類、意味的な文章生成、翻訳、質疑応答、サマリー生成など、いわゆる自然言語処理(Natural Language Processing, NLP)を目的としたモデルで、2017年にGoogleによって提唱されました。
GPTは、このTransformerに手を加えて、文書生成に特化させています。具体的には、入力された文書に対して、次に来る単語を予測できるようにしました。
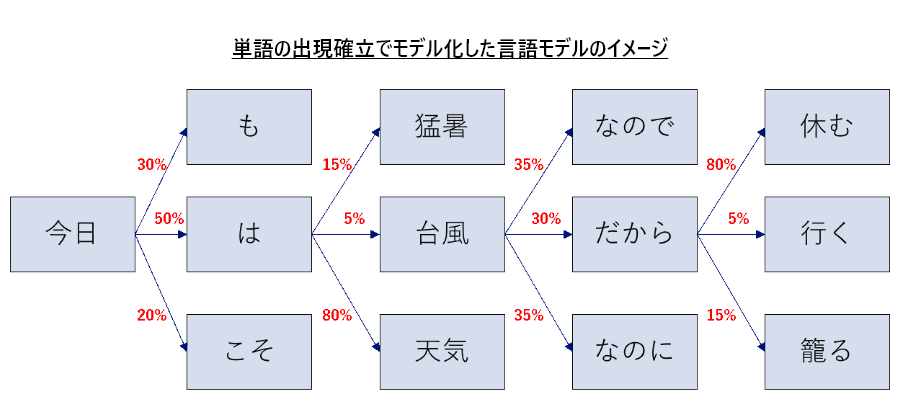
ディープラーニングでは、投入する学習データに正解となるデータを付加した、いわゆる「教師データ」を用いて学習させることが多いのですが、文書の次に来る単語を予測させる場合は、インプットとなるテキストデータに正解データが含まれています。
従って、あとは大量のテキストを与えるだけで、勝手に学習が進んでいくことになります。
このようにして作られたGPTに、「GPT自身が予測した結果に対しても次の単語を予測させる」という事を行わせると、次々と長い文章が生成できるようになります。
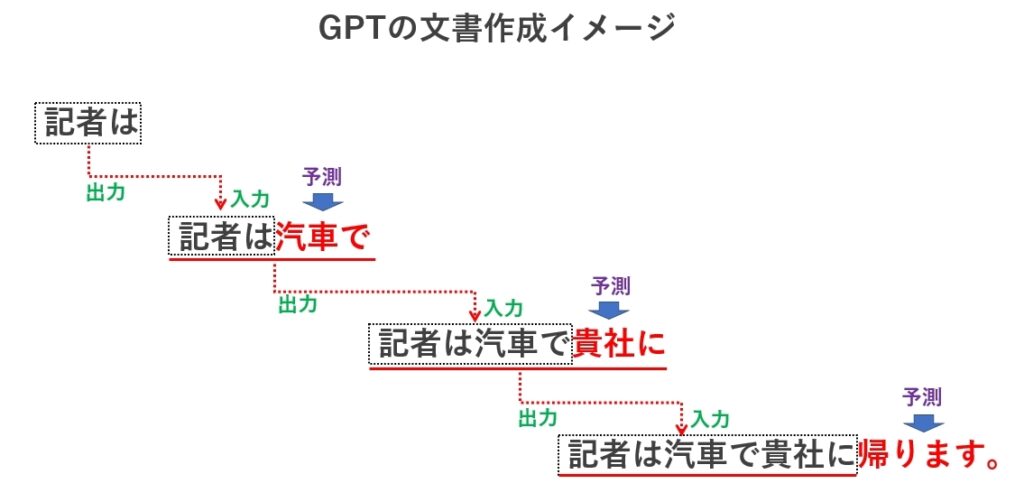
かなり大雑把な説明になりますが、このような仕組みでGPTは文書を生成していきます。
更に詳しい仕組みについてお知りになりたい方は、技術系サイト "Qiita" の「話題爆発中のAI「ChatGPT」の仕組みにせまる!」が参考になるかと思います。
学習データと学習方法

公開当初、GPT-3 はネット上に存在する2021年9月までのデータで学習データを学習していましたが、その後追加学習が行われ、2024年1月時点で2022年1月までのデータが学習済みとなりました(GPT-4は2023年4月までを学習済み)。
GPTはGPT2、GPT3、GPT4へと進化を遂げていますが、ベースとしてTransformer モデルを採用している点は変わらず、深層学習のレイヤー数、ユニット数、学習データを増やすことで実現しています。
| モデル | 学習用テキストデータ容量 | パラメータ数 |
|---|---|---|
| GPT-1 | 4.5 GB | 1.7億個 |
| GPT-2 | 40GB | 15憶個 |
| GPT-3 | 750 | 1750億個 |
| GPT-3.5 | 非公開 | 3550億個 |
| GPT-4 | 非公開 | 非公開 |
| GPT-4 Turbo | 非公開 | 非公開 |
尚、無料で利用できるのはGPT-3.5のみで、OpenAI公式サイトのチャットGPTがこれに該当します。一方、GPT-4、GPT-4 Turbo は月額20ドルの有料会員のみが利用可能です。
とはいうものの、マイクロソフトは自社向けにカスタマイズしたGPT-4を、検索エンジン「Bing(Copilot)」、Windows標準ブラウザ「Edge」、「Windows11」OSに組み込んでおり、これらはいつでも無料で利用可能となっています。
また、マイクロソフト製品に搭載されているGPT-4は、ウェブから情報を検索する機能を持っているため、本来GPT-4が学習している2023年4月より新しい情報でも回答してくれます。
社会への影響

アメリカでは、教育(先生)やジャーナリズム(記事、編集)がチャットGPTに置き換わるのではないか、フィッシングメールやフィッシングサイトに悪用されたり、チャットGPTの誤った回答によるフェイクニュースが広がるのではないかと懸念されています。
また、教育現場においても、宿題や試験でチャットGPTが利用されるケースが増えており、構内からチャットGPTへのアクセスを禁止する学校も出てきています。
その一方、不動産業者が物件情報の作成に利用したり、飲食店への口コミに対して、自動で返信してくれるシステムが登場するなど、急速にチャットGPTの利用シーンが拡大しています。
日テレNEWSの記事「チャットGPT]で近未来はどう変わる?アメリカで注目の技術者に聞く」に動画が掲載されているので、興味のある方は是非ご覧ください。
今後の動向

マイクロソフトはOpenAIに多額の支援をしており、自社の検索エンジン「Bing」や「Windows11」に GPT-3の次世代バージョンとなる「GPT-4」を搭載しています。今後、Office製品を含む様々なマイクロソフト製品と連携できるようになるでしょう。
一方、これに対抗するようにGoogleは独自AIチャットサービス「Google Bard」を公開、進化させています。日々Google ChromeやGmail、Googleカレンダー等のGoogle製品との連携機能を強化し、巻き返しを図っています。
これからは、チャットGPT、マイクロソフトBing AI、Google Bardがウェブ検索の方法を大きく変え、現時点で主流となるキーワード検索方法から対話型検索方法に切り替わっていくでしょう。
また、チャットGTP、マイクロソフトBing AI、Google Bardをフロントとして、音声認識、画像認識、音声合成、画像生成など様々なAIが統合され、複雑なことが簡単な指示だけで実現できるようになります。
正直、今後我々の仕事がどうなっていくのか分かりませんが、この変化に対して柔軟に対応し、AIをうまく活用していける人材がこれから生き残っていくことになるのでしょう。
参考書籍
もうすでに参考書籍がいくつか登場しています。いずれもアマゾンの電子書籍(Kindle)ですが、いづれも試し読みができます。興味のある方はどうぞ。
ちなみに、Kindle unlimited会員なら無料で読めます。
まとめ
今回は、2022年12月に登場し、わずか1週間でユーザー数100万人を突破、さまざまなメディアでに取り上げられ注目されているチャットGPTについて解説しました。
チャットGPTは「OpenAI」が開発した自然言語生成モデルで、対話形式で質疑応答が出来るチャットボットです。そして、この対話による質疑応答はAPIとして利用できるため、様々なシステムに組み込まれ、新たなサービスが登場してきています。
また、これに対抗する形でGoogleのBardも日々進化し続けています。
近いうちに、マイクロソフトやGoogleの検索エンジンはこれらのAIに置き換わり、キーワード羅列の検索スタイルから、対話形式の検索スタイルへチェンジしていくことになります。
また、チャットGPT、BingAI、Google Bardは、音声や画像系のAIと連携し、より高度なものへと進化していくものと思われます。
様々なSF映画に登場するシーンのように、音声でコンピュータと会話し、家電や自動車を操る時代がようやく到来しました。これからが本当に楽しみですね。



コメント
コメント一覧 (1件)
ドクターDX先生の講演おもしろかったよ。ねっとでは材料物理数学再武装ってのが有名だけど新バージョンの話。マテリアルズ・インフォマティクスに関係するものだった。